python读取文本文件数据
2024-08-26 00:07:01
本文要点刚要:
(一)读文本文件格式的数据函数:read_csv,read_table
1.读不同分隔符的文本文件,用参数sep
2.读无字段名(表头)的文本文件 ,用参数names
3.为文本文件制定索引,用index_col
4.跳行读取文本文件,用skiprows
5.数据太大时需要逐块读取文本数据用chunksize进行分块。
(二)将数据写成文本文件格式函数:to_csv
范例如下:
(一)读取文本文件格式的数据集
1.read_csv和read_table的区别:
#read_csv默认读取用逗号分隔符的文件,不需要用sep来指定分隔符
import pandas as pd
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.csv')
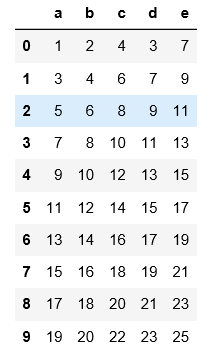
#read_csv如果读的是用非逗号分隔符的文件,必须要用sep指定分割符,不然读出来的是原文件的样子,数据没被分割开
import pandas as pd
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt')

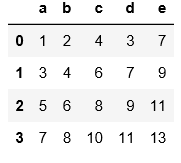
#与上面的例子可以对比一下区别
import pandas as pd
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
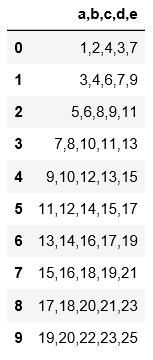
#read_table读取文件时必须要用sep来指定分隔符,否则读出来的数据是原始文件,没有分割开。
import pandas as pd
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.csv')
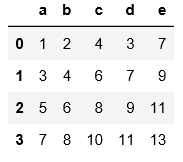
#read_table读取数据必须指定分隔符
import pandas as pd
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
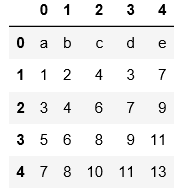
2.读取文本文件时不用header和names指定表头时,默认第一行为表头
#用header=None表示数据集没有表头,会默认用阿拉伯数字填充表头和索引
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|',header=None)
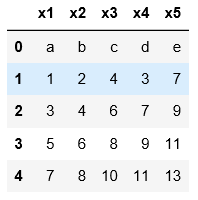
#用names可以自定义表头
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|',
names=['x1','x2','x3','x4','x5'])
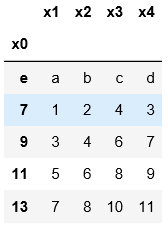
3.默认用阿拉伯数字指定索引;用index_col指定某一列作为索引
names=['x1','x2','x3','x4','x0']
pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|',
names=names,index_col='x0')
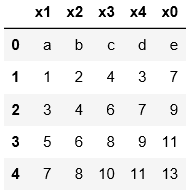
4.以下示例是用skiprows将hello对应的行跳过后读取其他行数据,不管首行是否作为表头,都是将表头作为第0行开始数
可以对比一下三个例子的区别进行理解
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt')

names=['x1','x2','x3','x4','x0']
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',names=names,
skiprows=[0,3,6])
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',
skiprows=[0,3,6])
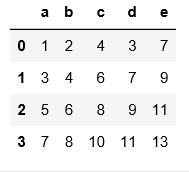
pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',header=None,
skiprows=[0,3,6])
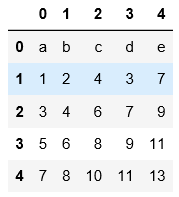
5.分块读取,data1.txt中总共8行数据,按照每块3行来分,会读3次,第一次3行,第二次3行,第三次1行数据进行读取。
注意这里在分块的时候跟跳行读取不同的是,表头没作为第一行进行分块读取,可通过一下两个例子对比进行理解。
chunker = pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',chunksize=3)
for m in chunker:
print(len(m))
print m

chunker = pd.read_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data1.txt',header=None,
chunksize=3)
for m in chunker:
print(len(m))
print m

(二)将数据写入文本格式用to_csv
以data.txt为例,注意写出文件时,将索引也写入了
data=pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
print data

#可以用index=False禁止索引的写入。
data=pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
data.to_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\outdata.txt',sep='!',index=False)

#可以用columns指定写入的列
data=pd.read_table('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\data.txt',sep='|')
data.to_csv('C:\\Users\\xiaoxiaodexiao\\pythonlianxi\\test0424\\outdata2.txt',sep=',',index=False,
columns=['a','c','d'])

最新文章
- Unreal4教程总结
- Linux之ls命令
- PoEdu - C++阶段班【Po学校】- 第1课
- setup 桌面化设置网卡
- 字符串匹配的KMP算法(转)
- JAVA 内存泄露的理解
- urlconnection.connect()和url.openconnection()的区别
- 基于GBT28181:SIP协议组件开发-----------第二篇SIP组件开发原理
- 路由器的nat模式、路由模式和全模式
- Stm32高级定时器(一)
- 简单工厂模式—>工厂模式
- SSM整合案例(Spring+Struts+Mybatis)
- spring-boot整合dubbo:Spring-boot-dubbo-starter
- Java设计模式-责任链模式
- 当你的layui表格要做全选+删除功能【兼容ie8】
- git代码提交步骤,教程
- 如何去掉Autodesk教育版印戳
- go语言指针判等
- openstack(Pike 版)集群部署(三)--- Glance 部署
- java 判断对象是否是某个类的类型两种方法