String相关介绍
String
- 字符串是常量,创建后不可改变。
- 字符串字面值存储在字符串池中,可以共享。
String s1 = "Runoob"; // String 直接创建
String s2 = "Runoob"; // String 直接创建
String s3 = s1; // 相同引用
String s4 = new String("Runoob"); // String 对象创建
String s5 = new String("Runoob"); // String 对象创建
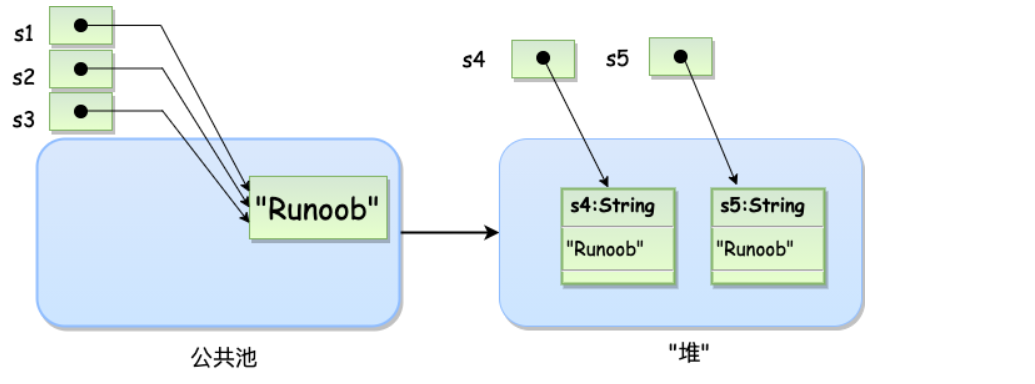
- 字符串常量池中是不会存储相同内容的字符串的.
- String的String Pool是一个固定大小的HashTable,默认值大小是1009.如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后会直接造成的影响就是当调用String.intern时性能会大幅下降
- 使用
-XX:StringTableSize可以设置StringTable的长度 - 在jdk6中的StringTable是固定的,就是1009的长度,所以如果常量池中的字符串过多就会导致效率下降很快.
- 在jdk7中,StringTable的长度默认是 60013,1009是可设置的最小值
在jdk1.7的时候把StringTable放到了堆空间中,为什么?
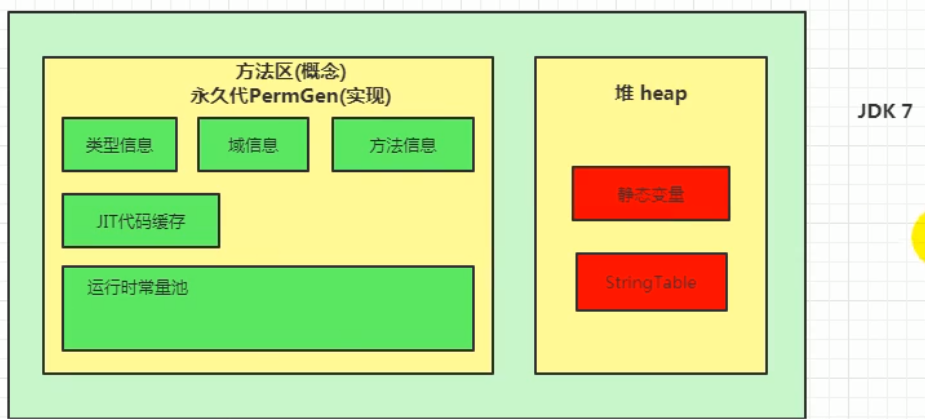
jdk7中将StringTable放到了堆空间中
- 因为永久代的回收效率很低,在full gc的时候才会触发.而full gc是老年代的空间不足,永久代不足时才会触发.
这就导致了StringTable回收效率不高.
- 而我们开发中会有大量的字符串被创建,回收效率低,导致永久代内存不足,放到堆里,能及时回收内存.
常用方法
public char charAt(int index);//根据下表获取字符
public boolean contains(String str);//判断当前字符串是否包含str
public char[] toCharArray;//将字符串转换成数组
public int indexOf(String str);//查找str首次出现的下标,存在,则返回该下标;不存在,则返回-1
public int length();//返回字符串长度
public String trim();//去掉字符串前后的空格
public String toUpperCase();//将小写转成大写
public String toLowerCase();//将大写转成小写
public boolean endWith(String str);//判断字符串是否以str结尾
public String replace(char oldChar,char newChar);//将字符串替换成新字符串
public String[] split(String str);//可根据str做拆分,拆分完不包含str
可变字符串
- StringBuffer: 可变长字符串,jdk1.0提供,运行效率慢,线程安全。
- StringBuilder: 可变长字符串,jdk5.0提供,运行效率快,线程不安全。
public static String appendEnds(String emilName){
StringBuilder buffer = new StringBuilder(emilName);
buffer.append("@baidu.com/");
return buffer.toString();
}
字符串拼接的底层
String s1 = "a";
String s2 = "b";
String s3 = "ab";
/*
*s1 + s2 执行细节
* 1. StringBuilder s = new StringBuilder();
* 2. s.append("a");
* 3. s.append("b");
* 4. s.toString(); -->约等于 new String("ab");
*
* 补充: 在jdk5之后使用的是StringBuilder,在jdk5之前使用的是StringBuffer
*/
String s4 = s1 + s2;
System.out.println(s3 == s4);//false
变形
final String s1 = "a";
final String s2 = "b";
String s3 = "ab";
/*
*s1 + s2 执行细节
* 被final修饰的是常量
* 这种情况等同于 s4 = "a" + "b";
*/
String s4 = s1 + s2;
System.out.println(s3 == s4);//true
总结
- 字符串拼接操作不一定使用的是StringBuilder,如果拼接符号左右两边都是字符串常量或常量引用,则仍然使用编译期优化,即非创建StringBuilder的方式
拼接操作与append方法的效率对比
通过StringBuilder的append()的方式添加字符串的效率要远高于使用String的字符串拼接方式!
原因:
StringBuilder的append()自始至终只创建一个StringBuilder的对象
使用String的字符串拼接方式创建过多个StringBuilder对象和String对象
使用String的字符串拼接方式:内存中由于创建了较多的StringBuilder和String对象,内存占用更大;如果进行GC需要花费更多的时间
改进空间:
实际开发中,如果基本确定要前前后后添加的字符串长度不超过某个限定值high的情况下,建议使用构造器构造
StringBuilder s = new StringBuilder(high);
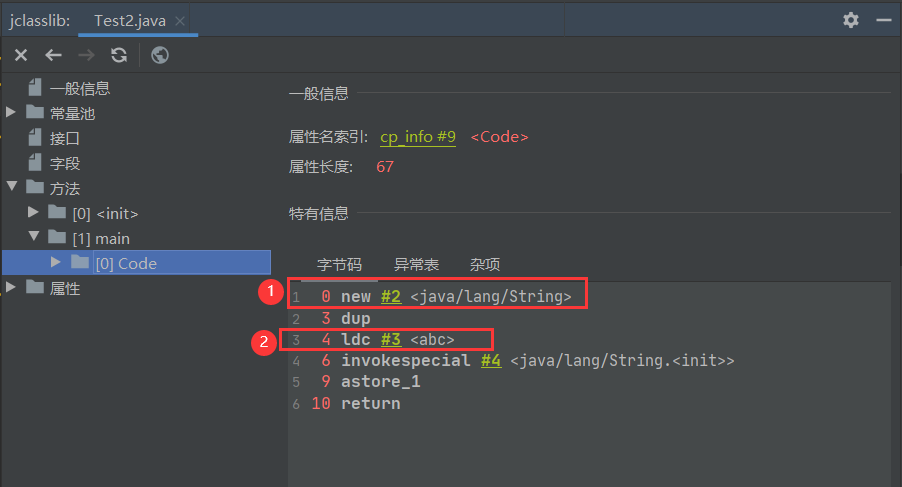
new String("ab")创建了几个对象?
public class Test2 {
public static void main(String[] args) {
String str = new String("abc");
}
}
- 两个
- 一个是new的时候在堆空间中开辟的一个新对象
- 另一个是在常量池中新建的"ab"
如何证明?
通过看java编译后的字节码文件
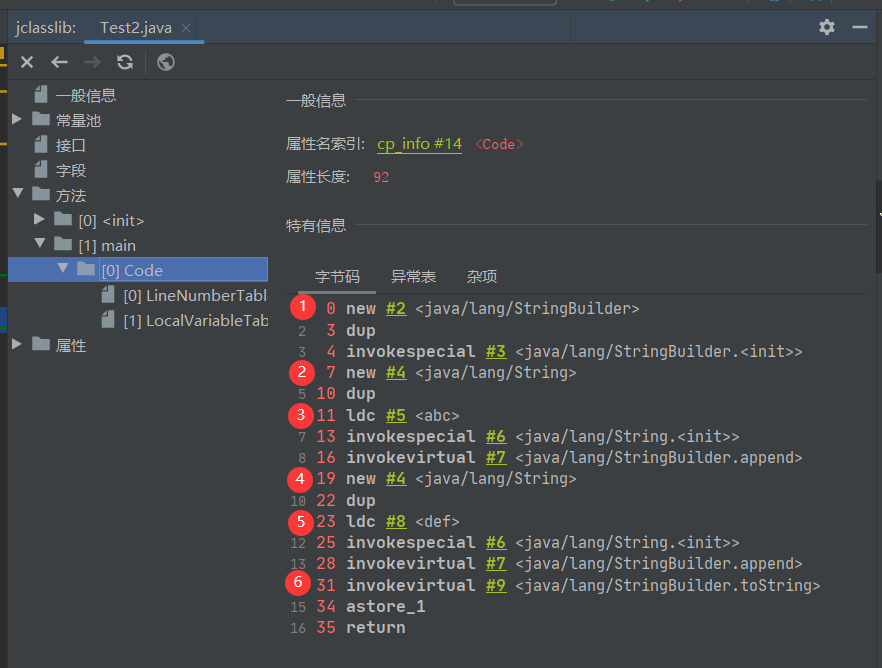
变形
String s = new String("abc") + new String("def");
5个
- new StringBuilder()
- new String("abc")
- 常量池中的"abc"
- new String("def")
- 常量池中的"def"
深入剖析:StringBuilder的toString():
- new String("abcdef")
intern()的使用
如何保证变量s指向的是字符串常量池中的数据?
有两种方式:
String s = "lld";//字面量定义
//调用intern()方法
String s = new String("lld").intern();
String S = new StringBuilder("lld").toString().intern();
String.intern()使用原理
String.intern()是一个Native方法,底层调用C++的 StringTable::intern方法实现。
当通过语句str.intern()调用intern()方法后,JVM 就会在当前类的常量池中查找是否存在与str等值的String
若存在则直接返回常量池中相应Strnig的引用;
若不存在,则会在常量池中创建一个等值的String,然后返回这个String在常量池中的引用。
因此,只要是等值的String对象,使用intern()方法返回的都是常量池中同一个String引用.
JDK6中
Jdk6中常量池位于PermGen(永久代)中,PermGen是一块主要用于存放已加载的类信息和字符串池的大小固定的区域。
执行intern()方法时
若常量池中不存在等值的字符串,JVM就会在常量池中创建一个等值的字符串,然后返回该字符串的引用。
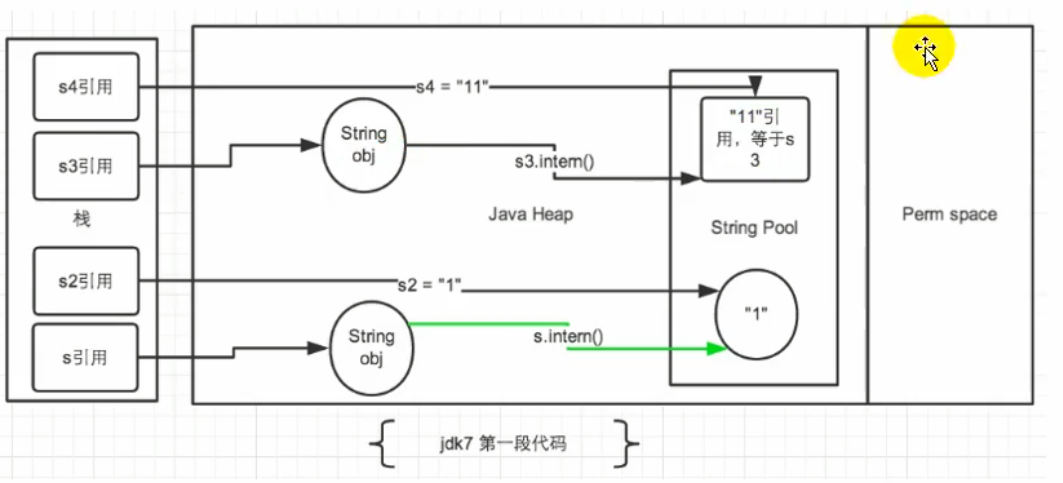
JDK7中
Jdk7将常量池从PermGen区移到了Java堆区.
执行intern操作时
如果常量池已经存在该字符串,则直接返回字符串引用,
否则复制该字符串对象的引用到常量池中并返回。
例如:
String s3 = new String("1") + new String("1");//s3变量记录的地址为: new String("11");
//执行完上一行代码以后,字符串常量池中并不存在"11"
s3.intern();
//在字符串常量池中生成"11".
//jdk6中创建了一个新对象"11",也就有了新地址
//jdk7中此时常量池中并没有创建"11",而是创建了一个指向堆空间中new String("11")的地址
String s4 = "11";
System.out.println(s3 == s4);
//在jdk6中为false 在jdk7/8中为true
BigDecimal
- 位置:java。math包中。
- 作用:精确计算浮点数。
- 创建方式:BigDecimal bd = new BigDecimal("1.2");
BigDecimal bg1 = new BigDecimal("2.2");
BigDecimal bg1 = new BigDecimal("1.2");
BigDecimal result = bg1.add(bg2);//加法
相关题目
1.判定定义为String类型的st1和st2是否相等,为什么
package string;
public class Demo2_String {
public static void main(String[] args) {
String st1 = "abc";
String st2 = "abc";
System.out.println(st1 == st2);
System.out.println(st1.equals(st2));
}
}
输出结果:
第一行:true
第二行:true
分析:
# 第一个打印语句
> 在Java中 == 这个符号是比较运算符,它可以基本数据类型和引用数据类型是否相等
如果是基本数据类型,== 比较的是值是否相等
如果是引用数据类型,== 比较的是两个对象的内存地址是否相等。
字符串不属于8中基本数据类型,字符串对象属于引用数据类型
在上面把“abc”同时赋值给了st1和st2两个字符串对象,指向的都是同一个地址,所以第一个打印语句中的==比较输出结果是 true
# 第二个打印语句中的equals的比较
> 我们知道,equals是Object这个父类的方法,在String类中重写了这个equals方法,在JDK API 1.6文档中找到String类下的equals方法,点击进去可以看到这么一句话“将此字符串与指定的对象比较。当且仅当该参数不为null,并且是与此对象表示相同字符序列的 String 对象时,结果才为 true。” 注意这个相同字符序列,在后面介绍的比较两个数组,列表,字典是否相等,都是这个逻辑去写代码实现。
由于st1和st2的值都是“abc”,两者指向同一个对象,当前字符序列相同,所以第二行打印结果也为true。
下面我们来画一个内存图来表示上面的代码,看起来更加有说服力。
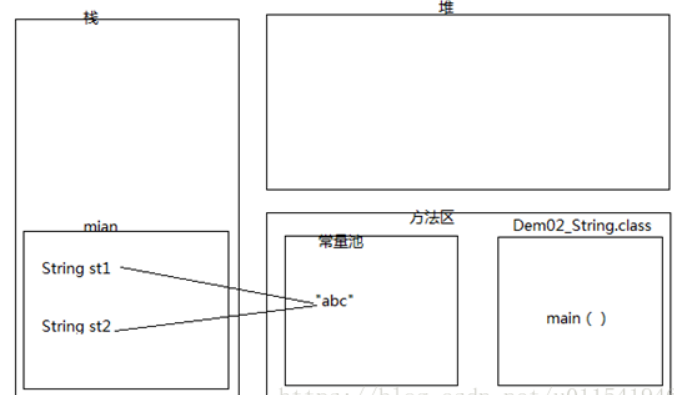
内存过程大致如下:
1)运行先编译,然后当前类Demo2_String.class文件加载进入内存的方法区
2)第二步,main方法压入栈内存
3)常量池创建一个“abc”对象,产生一个内存地址
4)然后把“abc”内存地址赋值给main方法里的成员变量st1,这个时候st1根据内存地址,指向了常量池中的“abc”。
5)前面一篇提到,常量池有这个特点,如果发现已经存在,就不在创建重复的对象
6)运行到代码 Stringst2 =”abc”, 由于常量池存在“abc”,所以不会再创建,直接把“abc”内存地址赋值给了st2
7)最后st1和st2都指向了内存中同一个地址,所以两者是完全相同的。
\2. 下面这句话在内存中创建了几个对象
String st1 = new String(“abc”);
答案是:在内存中创建两个对象,一个在堆内存,一个在常量池,堆内存对象是常量池对象的一个拷贝副本。
分析:
我们下面直接来一个内存图。
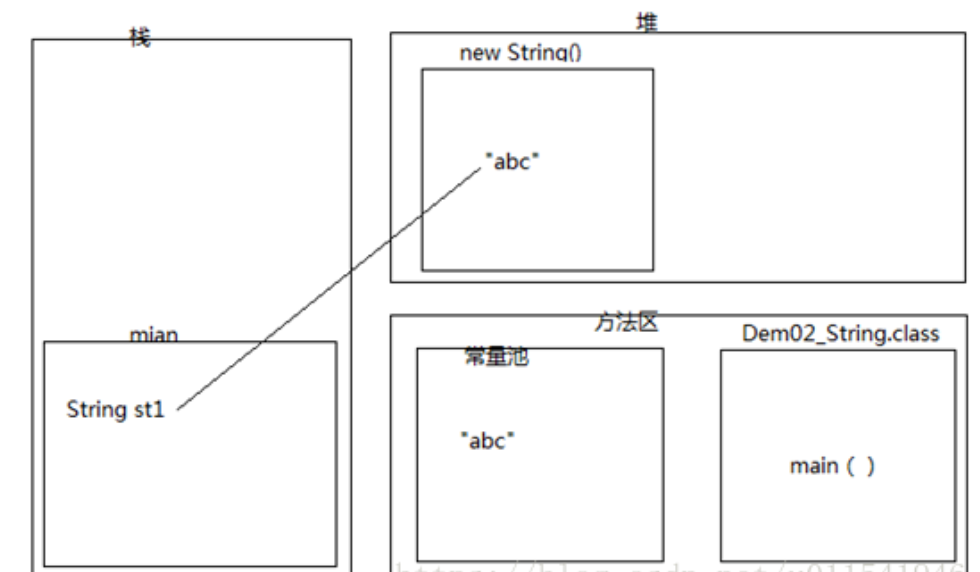
当我们看到了new这个关键字,就要想到,new出来的对象都是存储在堆内存。然后我们来解释堆中对象为什么是常量池的对象的拷贝副本。“abc”属于字符串,字符串属于常量,所以应该在常量池中创建,所以第一个创建的对象就是在常量池里的“abc”。第二个对象在堆内存为啥是一个拷贝的副本呢,这个就需要在JDK API 1.6找到String(String original)这个构造方法的注释:初始化一个新创建的 String 对象,使其表示一个与参数相同的字符序列;换句话说,新创建的字符串是该参数字符串的副本。所以,答案就出来了,两个对象。
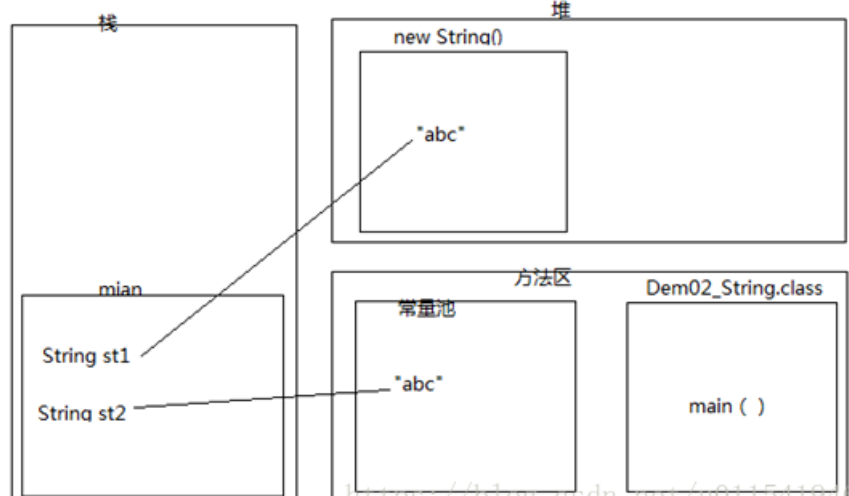
3.判定以下定义为String类型的st1和st2是否相等
package string;
public class Demo2_String {
public static void main(String[] args) {
String st1 = new String("abc");
String st2 = "abc";
System.out.println(st1 == st2);
System.out.println(st1.equals(st2));
}
}
答案:false 和 true
由于有前面两道提内存分析的经验和理论,所以,我能快速得出上面的答案。==比较的st1和st2对象的内存地址,由于st1指向的是堆内存的地址,st2看到“abc”已经在常量池存在,就不会再新建,所以st2指向了常量池的内存地址,所以==判断结果输出false,两者不相等。第二个equals比较,比较是两个字符串序列是否相等,由于就一个“abc”,所以完全相等。内存图如下
\4. 判定以下定义为String类型的st1和st2是否相等
package string;
public class Demo2_String {
public static void main(String[] args) {
String st1 = "a" + "b" + "c";
String st2 = "abc";
System.out.println(st1 == st2);
System.out.println(st1.equals(st2));
}
}
答案是:true 和 true
分析:
“a”,”b”,”c”三个本来就是字符串常量,进行+符号拼接之后变成了“abc”,“abc”本身就是字符串常量(Java中有常量优化机制),所以常量池立马会创建一个“abc”的字符串常量对象,在进行st2=”abc”,这个时候,常量池存在“abc”,所以不再创建。所以,不管比较内存地址还是比较字符串序列,都相等。
5.判断以下st2和st3是否相等
package string;
public class Demo2_String {
public static void main(String[] args) {
String st1 = "ab";
String st2 = "abc";
String st3 = st1 + "c";
System.out.println(st2 == st3);
System.out.println(st2.equals(st3));
}
}
答案:false 和 true
分析:
上面的答案第一个是false,第二个是true,第二个是true我们很好理解,因为比较一个是“abc”,另外一个是拼接得到的“abc”,所以equals比较,这个是输出true,我们很好理解。那么第一个判断为什么是false,我们很疑惑。同样,下面我们用API的注释说明和内存图来解释这个为什么不相等。
首先,打开JDK API 1.6中String的介绍,找到下面图片这句话。

关键点就在红圈这句话,我们知道任何数据和字符串进行加号(+)运算,最终得到是一个拼接的新的字符串。上面注释说明了这个拼接的原理是由StringBuilder或者StringBuffer类和里面的append方法实现拼接,然后调用toString()把拼接的对象转换成字符串对象,最后把得到字符串对象的地址赋值给变量。结合这个理解,我们下面画一个内存图来分析。
大致内存过程
1)常量池创建“ab”对象,并赋值给st1,所以st1指向了“ab”
2)常量池创建“abc”对象,并赋值给st2,所以st2指向了“abc”
3)由于这里走的+的拼接方法,所以第三步是使用StringBuffer类的append方法,得到了“abc”,这个时候内存0x0011表示的是一个StringBuffer对象,注意不是String对象。
4)调用了Object的toString方法把StringBuffer对象装换成了String对象。
5)把String对象(0x0022)赋值给st3
所以,st3和st2进行==判断结果是不相等,因为两个对象内存地址不同。
6.判断下面a == c和a == e
String a = "hello2";
final String b = "hello";
String d = "hello";
String c = b + 2;
String e = d + 2;
String f = c.intern();
System.out.println((a == c));
//true 由于变量b被final修饰,因此会被当做编译器常量,在使用到b的地方会直接将变量b替换为它的值“hello”
System.out.println((a == e));
//false d+2相当于是由StringBuilder.append后toString生成了一个新的堆对象,所以为false
System.out.println((a == e));
//intern():判断字符串常量池中是否存在 hello2 这个值,如果存在,则返回常量池当中这个常量的地址
//如果字符串常量池中不存在 hello2 ,则在常量池中加载一份 hello2 ,并返回这个值的地址
答案:true和false
总结:
- 常量与常量的拼接结果在常量池中,原理是编译期优化
- 常量池中不会存在相同内容的常量
- 只要其中有一个是变量,结果就在堆中.变量拼接的原理是StringBuilder
- 如果拼接的结果调用intern()方法,则主动将常量池中还没有的字符串对象放入池中,并返回此对象地址
最新文章
- 一次完整的HTTP事务是怎样一个过程?
- http://zhidao.baidu.com/link?url=X7IUn1KtjVb0889-lR1OlNOl5xJaA49LEqPHvjTvfKJt5uXPsyi-sn-Xc-yw6-fbaIBvuF0MiTVZGpZGeoW_HLphIR5WmiMVDMoNBFAOINa
- mac os x 安装mysql遇到 Access denied for user 'root'@'localhost' (using password: YES)的解决方法
- Linq专题之集合初始化器
- 周赛-Integration of Polynomial 分类: 比赛 2015-08-02 08:40 10人阅读 评论(0) 收藏
- WCF之事务
- 《那些事之Log4j》什么是log4j?【专题一】
- 【Java基础】几种简单的调用关系与方法
- android中使用Http下载文件并保存到本地SD卡
- 题解-COCI-2015Norma
- redis-使用问题
- 初读"Thinking in Java"读书笔记之第八章 --- 多态
- bootstrap-3-fileinput上传案例
- React文档(十五)使用propTypes进行类型检查
- 【HDU 1021】Fibonacci Again(找规律)
- CIKM Competition数据挖掘竞赛夺冠算法陈运文
- [整理]Error: [ngRepeat:dupes]的解决方法
- 深度学习attention 机制了解
- Dubbo与Zookeeper、SpringMVC整合和使用(负载均衡、容错)(略有修改)
- 六、Kafka 用户日志上报实时统计之分析与设计
热门文章
- 攻防世界 reverse 进阶 -gametime
- LookupError: 'hex' is not a text encoding; use codecs.decode() to handle arbitrary codecs
- 从本质彻底精通Git——4个模型1个周期1个史观1个工作流
- 我叫小M,立志建立MySQL帝国。
- IT培训有哪些坑(一)?
- .net 开源模板引擎jntemplate 教程:基础篇之在ASP.NET MVC中使用Jntemplate
- 翻译:《实用的Python编程》09_01_Packages
- poi 操作 PPT,针对 PPTX--图表篇
- 死磕Spring之AOP篇 - Spring AOP两种代理对象的拦截处理
- 我与OAuth 2.0那点荒唐的小秘密