GRAPH CONVOLUTIONAL NETWORK WITH SEQUENTIAL ATTENTION FOR GOAL-ORIENTED DIALOGUE SYSTEMS
面向领域特定目标的对话系统通常需要建模三种类型的输入,即(i)与领域相关的知识库,(ii)对话的历史(即话语序列)和(iii)需要生成响应的当前话语。
在对这些输入进行建模时,当前最先进的模型(如Mem2Seq)通常会忽略知识图和对话上下文中的句子中固有的丰富结构。
受最近结构感知图卷积成功的启发针对各种NLP任务,如机器翻译、语义角色标记和文档日期,我们提出了一种增强记忆的GCN用于面向目标的对话。
我们的模型利用(i)知识库中的实体关系图和(ii)与话语相关联的依赖图来计算词汇和实体的更丰富的表示。
此外,我们还注意到,在某些情况下,例如,当会话使用代码混合语言时,依赖解析器可能不可用。在这种情况下,我们可以使用全局词共现图来丰富话语的表征。
More specifically, there is some structure associated with the utterances as well as the knowledge base.
Current state-of-the-art methods (Seo et al., 2017; Eric & Manning, 2017; Madotto et al., 2018) typically use variants of Recurrent Neural Network (Elman, 1990) to encode the history and current utterance and an external memory network to store the entities in the knowledge base. The encodings of the utterances and memory elements are then suitably combined using an attention network and fed to the decoder to generate the response, one word at a time. However, these methods do not exploit the structure in the knowledge base as defined by entity-entity relations and the structure in the utterances as defined by a dependency parse.
但是,这些方法并未利用实体-实体关系定义的知识库结构和依存关系解析定义的话语结构。

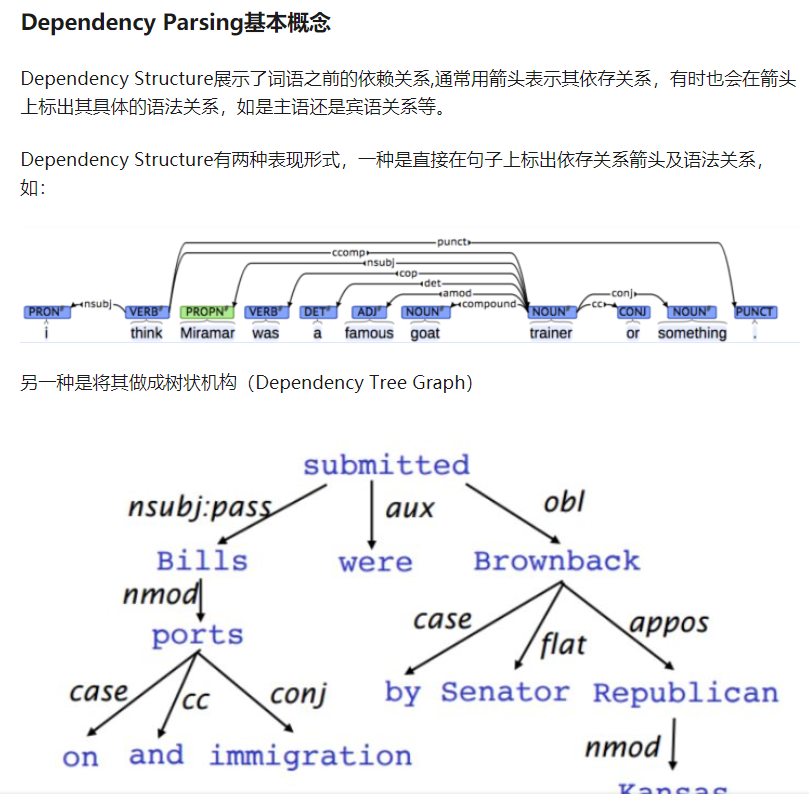
dependency parse tree
最新文章
- Redis应用场景一
- 【原】设置iOS项目BuildVersion自动增加
- JAVA 8 Lambda表达式-Lambda Expressions
- 小鸟哥哥博客 For SAE
- UI2_UITableViewDelete
- android145 360 进程管理
- 多tab页框架的使用场合
- Web —— java web 项目开发 笔记
- HTML系列(四):编辑图像
- 管理Fragments(转)
- ScheduledThreadPoolExecutor详解
- MVC RedirectToAction 跳转时传参问题
- JS获取页面复选框选中的值
- jsonArray返回
- ไม่มีวันเช่น--会有那么一天--电影《初恋这件小事》插曲--IPA--泰语
- 学习笔记之MobaXterm
- sudo执行脚本找不到环境变量和命令
- HTTP 请求头 详解
- Python 爬虫知识点
- 超简教程:Xgboost在Window上的安装(免编译)