2019-ICLR-DARTS: Differentiable Architecture Search-论文阅读
DARTS
2019-ICLR-DARTS Differentiable Architecture Search
- Hanxiao Liu、Karen Simonyan、Yiming Yang
- GitHub:2.8k stars
- Citation:557
Motivation
Current NAS method:
- Computationally expensive: 2000/3000 GPU days
- Discrete search space, leads to a large number of architecture evaluations required.
Contribution
- Differentiable NAS method based on gradient decent.
- Both CNN(CV) and RNN(NLP).
- SOTA results on CIFAR-10 and PTB.
- Efficiency: (2000 GPU days VS 4 GPU days)
- Transferable: cifar10 to ImageNet, (PTB to WikiText-2).
Method
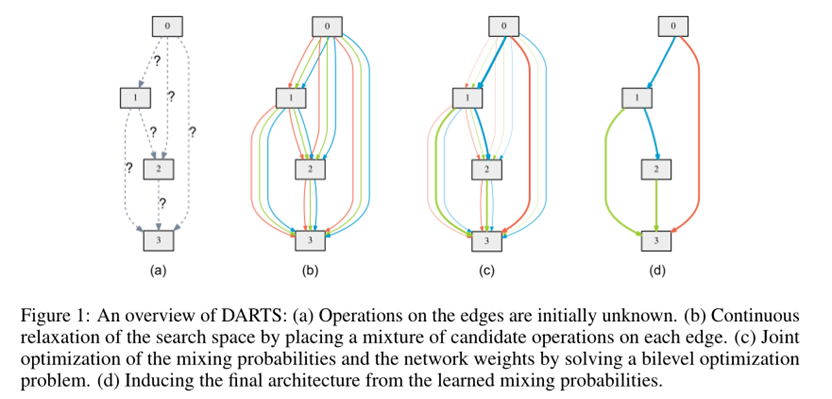
Search Space
Search for a cell as the building block of the final architecture.
The learned cell could either be stacked to form a CNN or recursively connected to form a RNN.
A cell is a DAG consisting of an ordered sequence of N nodes.
\(\bar{o}^{(i, j)}(x)=\sum_{o \in \mathcal{O}} \frac{\exp \left(\alpha_{o}^{(i, j)}\right)}{\sum_{o^{\prime} \in \mathcal{O}} \exp \left(\alpha_{o^{\prime}}^{(i, j)}\right)} o(x)\)
\(x^{(j)}=\sum_{i<j} o^{(i, j)}\left(x^{(i)}\right)\)
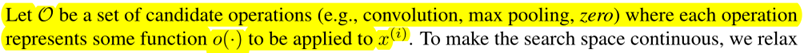
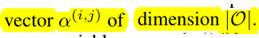


Optimization Target
Our goal is to jointly learn the architecture α and the weights w within all the mixed operations (e.g. weights of the convolution filters).
\(\min _{\alpha} \mathcal{L}_{v a l}\left(w^{*}(\alpha), \alpha\right)\) ......(3)
s.t. \(\quad w^{*}(\alpha)=\operatorname{argmin}_{w} \mathcal{L}_{\text {train}}(w, \alpha)\) .......(4)
The idea is to approximate w∗(α) by adapting w using only a single training step, without solving the inner optimization (equation 4) completely by training until convergence.
\(\nabla_{\alpha} \mathcal{L}_{v a l}\left(w^{*}(\alpha), \alpha\right)\) ......(5)
\(\approx \nabla_{\alpha} \mathcal{L}_{v a l}\left(w-\xi \nabla_{w} \mathcal{L}_{t r a i n}(w, \alpha), \alpha\right)\) ......(6)
- When ξ = 0, the second-order derivative in equation 7 will disappear.
- ξ = 0 as the first-order approximation,
- ξ > 0 as the second-order approximation.






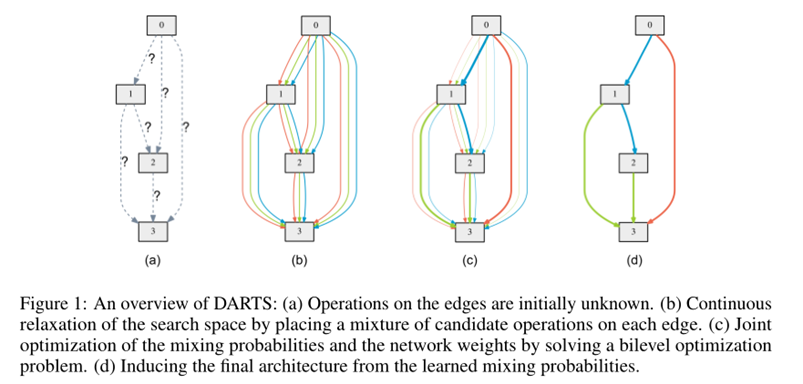
Discrete Arch
To form each node in the discrete architecture, we retain the top-k strongest operations (from distinct nodes) among all non-zero candidate operations collected from all the previous nodes.
we use k = 2 for convolutional cells and k = 1 for recurrent cellsThe strength of an operation is defined as \(\frac{\exp \left(\alpha_{o}^{(i, j)}\right)}{\sum_{o^{\prime} \in \mathcal{O}} \exp \left(\alpha_{o^{\prime}}^{(i, j)}\right)}\)
Experiments
We include the following operations in O:
- 3 × 3 and 5 × 5 separable convolutions,
- 3 × 3 and 5 × 5 dilated separable convolutions,
- 3 × 3 max pooling,
- 3 × 3 average pooling,
- identity (skip connection?)
- zero.
All operations are of
- stride one (if applicable)
- the feature maps are padded to preserve their spatial resolution.
We use the
- ReLU-Conv-BN order for convolutional operations,
- Each separable convolution is always applied twice
- Our convolutional cell consists of N = 7 nodes, the output node is defined as the depthwise concatenation of all the intermediate nodes (input nodes excluded).
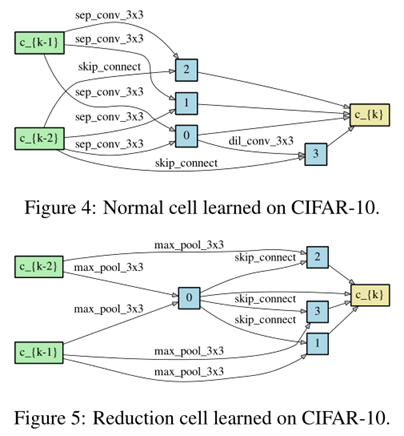
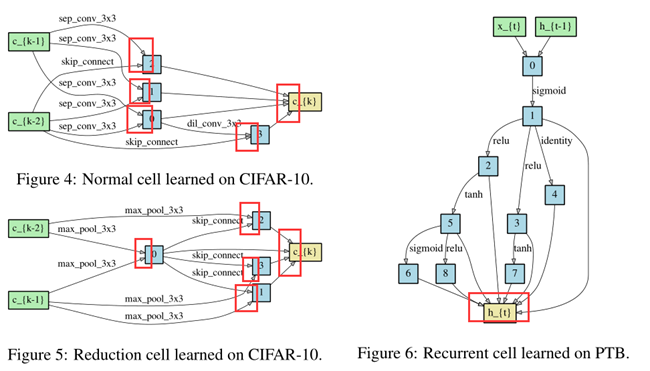
The first and second nodes of cell k are set equal to the outputs of cell k−2 and cell k−1
Cells located at the 1/3 and 2/3 of the total depth of the network are reduction cells, in which all the operations adjacent to the input nodes are of stride two.
The architecture encoding therefore is (αnormal, αreduce),
where αnormal is shared by all the normal cells
and αreduce is shared by all the reduction cells.
To determine the architecture for final evaluation, we run DARTS four times with different random seeds and pick the best cell based on its validation performance obtained by training from scratch for a short period (100 epochs on CIFAR-10 and 300 epochs on PTB).
This is particularly important for recurrent cells, as the optimization outcomes can be initialization-sensitive (Fig. 3)
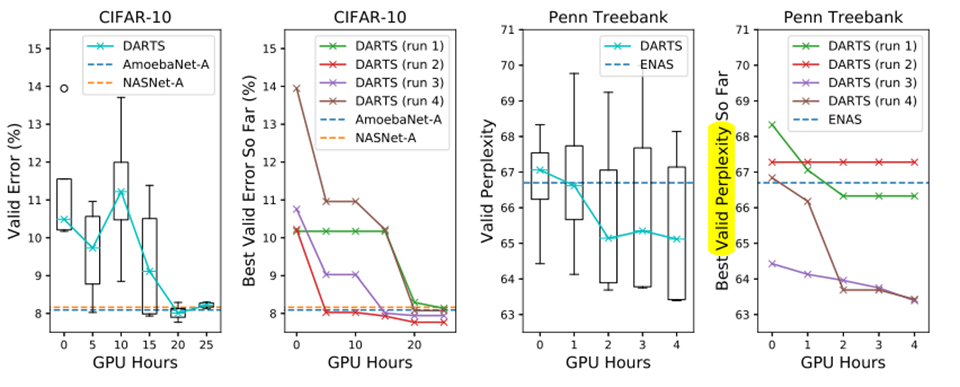
Arch Evaluation
- To evaluate the selected architecture, we randomly initialize its weights (weights learned during the search process are discarded), train it from scratch, and report its performance on the test set.
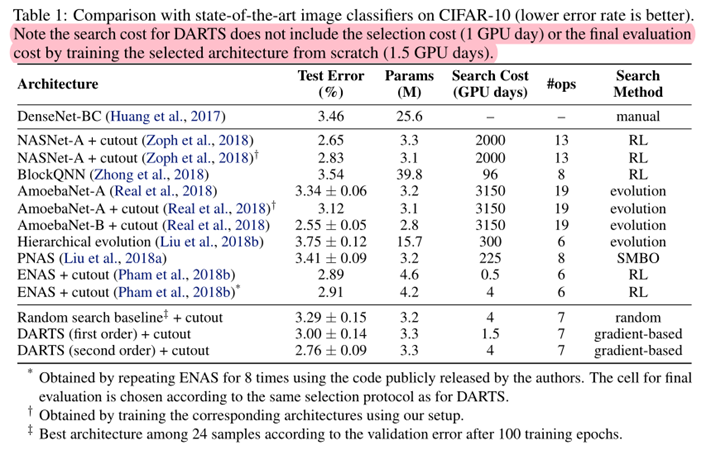
- To evaluate the selected architecture, we randomly initialize its weights (weights learned during the search process are discarded), train it from scratch, and report its performance on the test set.
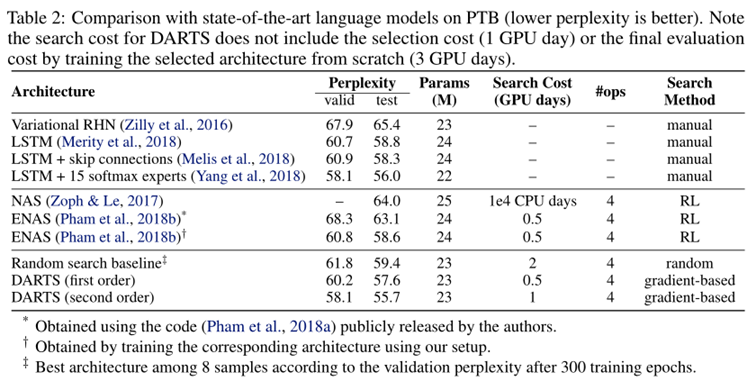
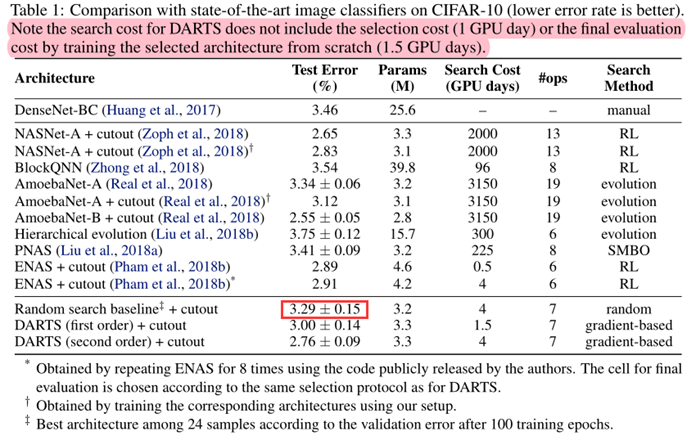
Result Analysis
- DARTS achieved comparable results with the state of the art while using three orders of magnitude less computation resources.
- (i.e. 1.5 or 4 GPU days vs 2000 GPU days for NASNet and 3150 GPU days for AmoebaNet)
- The longer search time is due to the fact that we have repeated the search process four times for cell selection. This practice is less important for convolutional cells however, because the performance of discovered architectures does not strongly depend on initialization (Fig. 3).
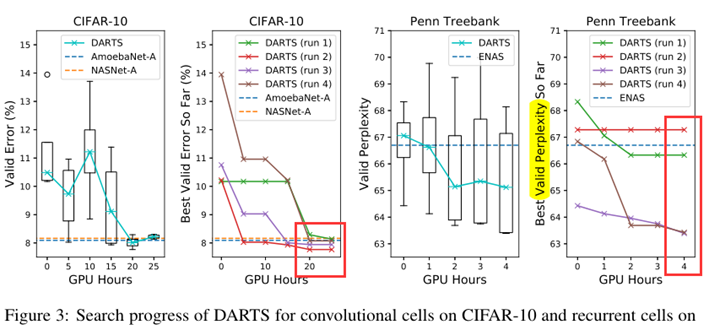
- It is also interesting to note that random search is competitive for both convolutional and recurrent models, which reflects the importance of the search space design.
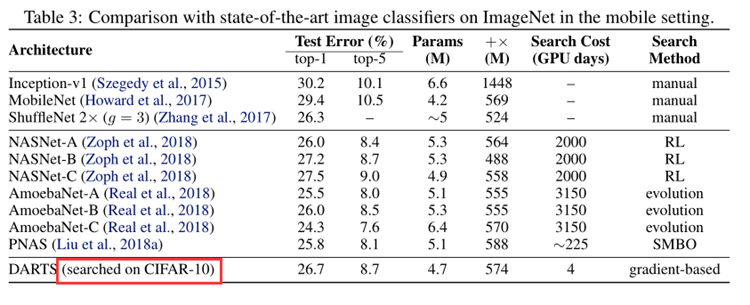
Results in Table 3 show that the cell learned on CIFAR-10 is indeed transferable to ImageNet.
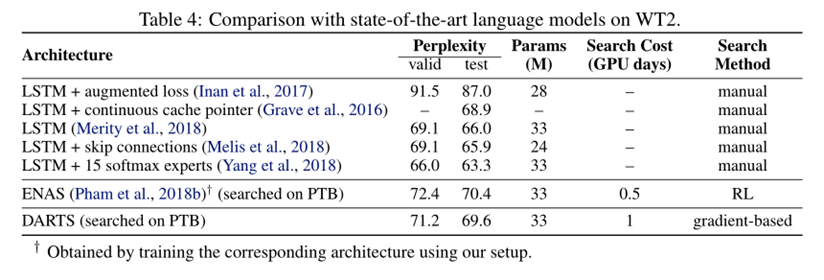
The weaker transferability between PTB and WT2 (as compared to that between CIFAR-10 and ImageNet) could be explained by the relatively small size of the source dataset (PTB) for architecture search.
The issue of transferability could potentially be circumvented by directly optimizing the architecture on the task of interest.
Conclusion
- We presented DARTS, a simple yet efficient NAS algorithm for both CNN and RNN.
- SOTA
- efficiency improvement by several orders of magnitude.
Improve
- discrepancies between the continuous architecture encoding and the derived discrete architecture. (softmax…)
- It would also be interesting to investigate performance-aware architecture derivation schemes based on the shared parameters learned during the search process.
Appendix
最新文章
- python中协程
- SQL Server 维护计划实现数据库备份(策略实战)
- 干货发布:VSS文件清理工具
- html5 EvnetSource 与 JSP页面结合使用
- BNUOJ 1037 精神控制
- c++ 中this底层
- To and Fro
- strcmp函数和strcpy函数
- Codeforces 526D - Om Nom and Necklace 【KMP】
- Python 可变对象和不可变对象
- 【ASP.NET Web API教程】2.3.7 创建首页
- Java版本
- Alamofire源码解读系列(九)之响应封装(Response)
- SpringBoot配置拦截器
- c# 事件和EventManager
- Effective STL 读书笔记
- 使用console进行 性能测试 和 计算代码运行时间
- DevExpress 数据与展示的不同
- c++之boost share_ptr
- linux rpm命令之查询包安装与否、包详细信息、包安装位置、文件属于哪个包、包依赖