zookeeper3.4.5集群安装
机器配置:
|
机器 |
Hostname |
user |
|
192.168.169.139 |
node139 |
hadoop |
|
192.168.169.140 |
node140 |
hadoop |
|
192.168.169.141 |
node141 |
hadoop |
root用户先新建用户hadoop
useradd hadoop
passwd hadoop
输入密码并确认密码即可
1、安装局部jdk
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

3台机器的hadoop用户中均需要安装并配置环境变量(jdk配置路径保持相同,解压后文件夹名称保持相同)
2、关闭防火墙
依次执行:
chkconfig iptables off(永久关闭,但需重启,所以执行下面语句进行临时关闭)
service iptables stop(临时关闭)
service iptables status(防火墙状态进行查看)
3、修改主机hostname
vi /etc/sysconfig/network(需重启生效)
echo ***(例如:node139)> /proc/sys/kernel/hostname(即时生效,需重新打开一个shell窗口方能看到)
4、配置静态的DNS域名
手动配置三台机器的域名,实现三台机器之间通过域名即可访问。
在node139机器上,使用root账号通过Xshell工具登录系统,修改hosts文件,
输入命令:vi /etc/hosts
增加3台主机的域名配置:
|
192.168.169.139 node139 192.168.169.140 node140 192.168.169.141 node141 |
保存退出即可
以上1-4步骤每台服务器均需操作
5、配置时钟同步ntpd服务
为使集群相关机器所有时间均保持相同,故而进行配置,很重要。
现在将139服务器作为服务端,root用户登录
修改配置:
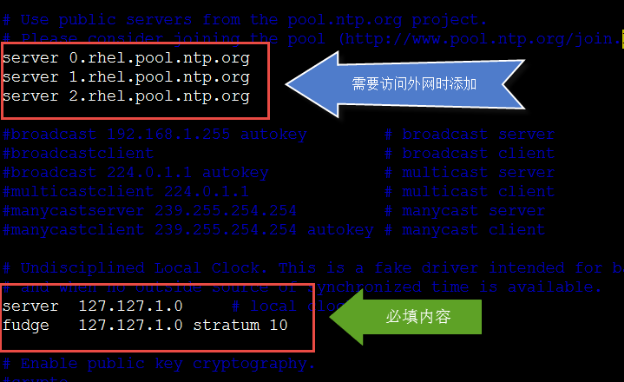
vim /etc/ntp.conf
取消下面注释
|
server 127.127.1.0 fudge 127.127.1.0 stratum 10 (外部时间服务器不可用时,以本地时间作为时间服务) |
6、同样的root用户在客户端140和141服务器上面修改配置文件
vim /etc/ntp.conf
添加一行服务端的server,并取消下面标注的两行注释
|
server node139 server 127.127.1.0 fudge 127.127.1.0 stratum 10 |
7、启动ntp服务端(node139)上的ntp服务,启动后,一般需要5-10分钟左右的时候才能与外部时间
服务器开始同步时间(因此不急着执行9-11步骤,否则会报20 Mar 23:11:31 ntpdate[61783]: no server
suitable for synchronization found)。
输入命令: service ntpd start
8、输入命令 ps -ef | grep ntp 查看ntpd进程是否启动
9、客户端时间同步,输入命令 ntpdate node139 查看时间服务器同步时间 (node140和node141均执行)
10、输入命令hwclock -w 更新客户端bios时钟(node140和node141均执行)
11、输入命令 crontab -e 将时间同步设置为定时任务(node140和node141执行),添加下面内容
|
0-59/10 * * * * ntpdate node139 && hwclock -w |
注解:增加一个10分钟一次的时间同步任务
12、zookeeper集群安装(node139服务器hadoop用户)
上传zookeeper-3.4.5-cdh5.5.4.tar.gz包至hadoop用户主目录,解压,解压后删除tar包
上传包完毕后依次执行
安装包下载地址
链接:https://pan.baidu.com/s/1V4klTVidPEAkkn8W_f8_Ow
密码:koye
tar -zxvf zookeeper-3.4.5-cdh5.5.4.tar.gz
rm -rf zookeeper-3.4.5-cdh5.5.4.tar.gz
13、进入到zookeeper的安装目录
cd zookeeper-3.4.5-cdh5.5.4/

14、新建data和logs文件夹
mkdir data
mkdir logs
15、复制zoo_sample.cfg文件
cd conf/
cp zoo_sample.cfg zoo.cfg

16、修改zoo.cfg文件
vi zoo.cfg
|
tickTime=2000 initLimit=5 syncLimit=2 dataDir=/home/hadoop/cm/zookeeper-3.4.5-cdh5.5.4/data clientPort=2181 server.1=node139:2888:3888 server.3=node141:2888:3888 maxClientCnxns=60 minSessionTimeout=4000 maxSessionTimeout=300000 |

注释:
tickTime:心跳时间
initLimit:多少个心跳时间内,允许其他server连接并初始化数据
syncLimit:多少个tickTime内,允许follower节点同步
dataDir:存放内存数据文件目录,根据实际环境修改
dataLogDir:存放日志文件目录,根据实际环境修改
clientPort:监听端口,使用默认2181端口
server.x:配置集群主机信息,[hostname]:[通信端口]:[选举端口],根据自己的主机信息修改
maxClientCnxns:最大并发客户端数,用于防止DOS的,设置为0是不加限制
minSessionTimeout:最小的客户端session超时时间(单位是毫秒)
maxSessionTimeout:最大的客户端session超时时间(单位是毫秒)
17、将本机安装目录,通过scp全部拷贝至另外2台机器。
输入命令:
scp -r zookeeper-3.4.5-cdh5.5.4/ hadoop@node140:/home/hadoop/cm/
scp -r zookeeper-3.4.5-cdh5.5.4/ hadoop@node141:/home/hadoop/cm/
输入yes和密码就能完美复制过去
18、在三台服务器的zookeeper安装目录下的data文件夹下面新建文件myid
touch myid
vi myid
分别输入数字1、2、3,对应上面配置文件的server后面的数字


19、Zookeeper的启动停止
分别进入三台服务器的zookeeper安装目录,输入命令bin/zkServer.sh start 启动Zookeeper服务

20、进入节点,执行命令为:
bin/zkCli.sh -server 192.168.169.139:2181 回车
ls / (查看当前 ZooKeeper 中所包含的内容,输入命令quit 退出Zookeeper服务)
21、启动zookeeper服务后可以通过jps命令查看zookeeper进程,进程名为QuorumPeerMain
22、在zookeeper安装目录下输入命令 bin/zkServer.sh status 各个节点的状态
23、如果需要停止zookeeper服务,则在zookeeper安装目录上输入命令 bin/zkServer.sh stop
最新文章
- WangSql 1.0源码共享
- mongoDB01 介绍
- windows 下双网卡在不同网络切换设置
- C#(二维数组/集合)
- C 实现一个跨平台的定时器 论述
- css3 calc():css简单的数学运算-加减乘除
- 【UE】
- [11-1] adaboost DTree
- Android @+id与@id的区别
- 百度地图之UI控制
- Ubuntu16.04 install mysql5.X
- 特殊计数序列——第二类斯特林(stirling)数
- linux 解决Unable to fetch some archives, maybe run apt-get update or try with --fix-missing?
- 使用postman进行并发测试
- js模拟ctrl+c的问题
- ENQUIRE the predecessor to the World Wide Web.
- Iterator和Iterable的区别以及使用
- ASP.NET Web API 框架研究 Controller创建过程与消息处理管道
- fresco中设置占位/加载失败的图片 无效
- Java volatile关键字解惑