ID生成器之——别人家的方案and自家的方案
“叮咚,叮咚……”,微信提示音一声接一声,声音是那么的频繁,有妖气,待俺去看一看。
这天刚吃完午饭,打开微信,发现我们的技术讨论组里有 100 多条未读消息,心想,是不是系统出问题了?怎么消息那么频繁?
于是迅速的爬楼,历时 1 秒 23,爬到楼顶,虚惊一场。了解消息的来龙去脉,大体意思:下午两点,研发一组在第二会议室开会,会议主题是:开发一个适合多个业务场景的分布式 ID 生成器。
到了两点,我们都来到第二会议室,开始了激烈讨论。
可能你们都知道,ID 是某个体系中唯一的编码,用来标识事务,比如:身份标识号、账号、唯一编码、专属号码。
ID 生成器又是什么呢?说白了就是生成 ID 工具,而在这里我们说的 ID 生成器,是一个服务(下同)。
为什么要开发分布式 ID 生成器?
原因大体有两点:
1. 许多业务系统需要对大量的订单、消息进行进行唯一标识,如:金融、电商、支付等。
2. 每个部门都开发一套 ID 生成器,总体上增加了工作量,增加公司的成本,不利于维护、管理。
分布式 ID 生成器有哪些要求?
1. 全局唯一性:不能出现重复的 ID 号,既然是唯一标识,这是最基本的要求。
2. 递增:比较低要求的条件为趋势递增,即保证下一个 ID 一定大于上一个 ID,而比较苛刻的要求是连续递增,如1001,1002,1003 等等。根据我们自己的业务,我们选择的是趋势递增(连续递增,会暴露出系统实际订单量)。
3. 高可用:ID 生成事关重大,一旦挂掉会导致整个系统崩溃,给公司带来巨大的损失,需要保证 ID 的正常、稳定生成。
4. 高性能:必须要在压测下表现良好,如果达不到要求则在高并发环境下依然会导致系统瘫痪。
5. 灵活多变:每个业务场景对 ID 的要求也各不相同,ID 生成要做到灵活多变可配置,尽可能多的满足需求。
针对以上那么多要求,我们到底要怎么做?看看前辈们都是怎么做的吧,目前业内有几种常见的解决方案。
一、UUID(用的最多)方案
UUID:通用唯一识别码(Universally Unique Identifier)的标准型式包含 32 个 16 进制数字,以连字号分为五段,形式为 8-4-4-4-12 的 36 个字符,示例:550e8400-e29b-41d4-a716-446655440000。
优点:本地生成,全局唯一,没有网络消耗。
缺点:UUID 太长,通常以 36 长度的字符串表示,对 MySQL 索引不利,如果作为数据库主键,在 InnoDB 引擎下,UUID 的无序性可能会引起数据位置频繁变动,严重影响性能;UUID 不能标识业务含义,可读性差;不满足递增要求;不够灵活。
二、Twitter 的雪花算法 SnowFlake 方案
这种方案大致来说是一种以划分命名空间(UUID 也算,由于比较常见,所以单独分析)来生成 ID 的一种算法,这种方案把 64-bit 分别划分成多段,分开来标示机器、时间等,比如在 snowflake 中的 64-bit 分别表示如下图所示:
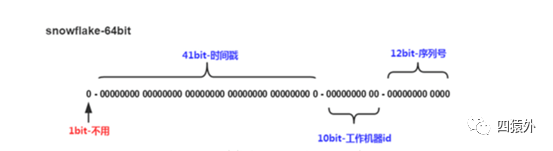
第一位为未使用,接下来的 41 位为毫秒级时间(41 位的长度可以使用 69 年),然后是 5 位 datacenterId 和 5 位 workerId (10 位的长度最多支持部署 1024 个节点) ,最后 12 位是毫秒内的计数(12 位的计数顺序号支持每个节点每毫秒产生 4096 个 ID 序号)一共加起来刚好 64 位,为一个 Long 型 (转换成字符串长度为 18) 。示例:323893460451070160,323893460455264256。
优点:整体上按照时间自增排序;全局唯一;效率高。
缺点:有序,但不连续;不能同时满足多个系统对ID的需求,不够灵活。
三、数据库自增序列生成方案
以 MySQL 举例,利用给字段设置 auto_increment_increment和 auto_increment_offset 来保证 ID 自增,每次业务使用下列 SQL 读写 MySQL 得到 ID 号。
优点:简单,利用现有数据库系统的功能实现;成本小,有 DBA 专业维护;ID 号自增,可以实现一些对 ID 有特殊要求的业务。
缺点:强依赖 DB,当 DB 异常时整个系统不可用,属于致命问题;配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证;主从切换时的不一致可能会导致重复发号。
ID 发号性能瓶颈限制在单台 MySQL 的读写性能。
四、基于 ZooKeeper 和本地缓存的方案
使用 ZooKeeper 作为分段节点协调工具,每台服务器首先从 Zookeeper 缓存一段,如 1 – 2000 的 ID,此时 Zookeeper 上保存最大值 2000,每次获取的时候都会进行判断,如果 ID <= 2000,则更新本地的当前值,如果为 2001,则会将 Zookeeper 上的最大值更新至 4000,本地缓存段更新为 2001 - 4000,更新的时候使用分布式锁来实现。
优点:全局唯一,效率高。
缺点:维护成本较高,不能同时满足多个系统对 ID 的需求,不够灵活。
五、我们的方案
看了许多业内解决方案,有些方案已经基本上可以满足我们的需求,但是不够灵活。我们需要一种灵活、多变、可配置的方案。
经过一番讨论,我们选择了自己造轮子,核心思想:
使用数据库双 buffer 优化方案,每次从数据库拿取一个号段,当该号段下发 50% 时,如果下一个号段未更新,则启动另一个线程去提前更新新号段,当该号段已全部下发完成,且下一个号段准备完成,则切换到下一个号段,就这样一次一次的循环。
举个栗子:第一次取一个号段 100,000 - 110,000(1),当该号段下发到 105,000 时,去检查 120,000 号段是否更新,如果未更新,启动一个线程去更新号段120,000 - 130,000(2),当(1)号段已经下发完成,切换到(2)号段。
这样做的好处是不用频繁的访问数据库,保证了效率,在数据库宕机的一段时间内,服务仍然可生成 ID 。
这样就灵活了吗?
NO,这提高性能、效率的方式,要想做到灵活,我们需要设计一张数据库表,表中要区别不同的业务类型,可以设置ID 的前缀规则、后缀规则、长度、步长、最大 ID,保证 ID 灵活、多变、可配置。
数据库表结构设计:
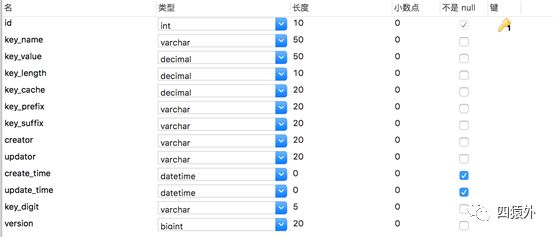
key_name:区分业务
key_length:ID 长度
key_cache:缓存数量
key_prefix:前缀规则
key_subffix:后缀规则
key_digit:key 生成规则,支持 10 进制、36 进制或者 62 进制
数据库表测试数据:

测试服务器配置:Linux 2 核 4G 内存 X 2
步长设置为 1000,缓冲池设置为 1000,每秒大约可生成 16,675,231 次。
分布式 ID 生成器的方案还有很多,各有各的优点,需要你们根据自己的业务场景去选择,“不选贵的,只选对的”。
希望这篇文章对你们有帮助,欢迎关注我的公众号。

最新文章
- DEDECMS之一 安装配置
- Swift2.1 语法指南——嵌套类型
- [转] - MC、MC、MCMC简述
- mysql中OPTIMIZE TABLE的作用
- linux命令之 用户和群组
- UVA 11858 Frosh Week 逆序对统计
- 用PowerShell代替批处理吧!
- bash脚本退出代码解释
- 菜鸟Scrum敏捷实践系列(三)用户故事的组织---功能架构的规划
- ListView在异步加载动态图片时,往往最后一项或几项被遮盖(IM场景居多)
- 前端MVC Vue2学习总结(一)——MVC与vue2概要、模板、数据绑定与综合示例
- dygod.net
- 根据学习廖雪峰老师的git教程做的笔记
- 【强化学习】python 实现 saras lambda 例一
- python字符串内建函数
- hdu 2089 数位dp
- SRM483
- Sizeof与Strlen的区别【转】
- 多个sshkey 指定key来clone仓库
- 咏南WEB框架群集