spark-2.1.1 yarn(高可用)搭建
一、概述
spark分布式搭建方式大致分为三种:standalone、yarn、mesos。三种分类的区别这里就不一一介绍了,不明白可自行了解。standalone是官方提供的一种集群方式,企业一般不使用。yarn集群方式在企业中应用是比较广泛的,这里也是介绍yarn的集群安装方式。mesos安装适合于超大型集群。
集群节点分配:
hadoop01:Zookeeper、NameNode(active)、ResourceManager(active)
hadoop02:Zookeeper、NameNode(standby)
hadoop03:Zookeeper、 ResourceManager(standby)
hadoop04: DataNode、 NodeManager、 JournalNode、 spark
hadoop05: DataNode、 NodeManager、 JournalNode、 spark
hadoop06: DataNode、 NodeManager、 JournalNode、 spark
二、安装
说明一下:
①选spark的时候要注意与hadoop版本对应。因为hadoop用的是2.7的,所以spark选的是spark-2.1.1-bin-hadoop2.7
②因为spark基于yarn来管理,spark只能安装在NodeManager节点上。
③spark安装放在/home/software目录下。
1、hadoop基于yarn(ha)的搭建,这里介绍步骤了。在我的上一个教程里有详细介绍。
2、安装scala,并配置好环境变量。
3、在NodeManager节点上解压spark文件。
tar -xvf spark-2.1.1-bin-hadoop2.7
3、修改spark-2.1.1-bin-hadoop2.7/conf/spark-env.sh,在文件尾部加上以下内容,其中HADOOP_CONF_DIR是必填项
export JAVA_HOME=/home/jack/jdk1.8.0_144
export SCALA_HOME=/home/jack/scala-2.12.3
export HADOOP_HOME=/home/software/hadoop-2.7.4
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.4/etc/hadoop
export SPARK_MASTER_PORT=7077
export SPARK_EXECUTOR_CORES=2
export SPARK_EXECUTOR_MEMORY=1024m
export SPARK_EXECUTOR_INSTANCES=1
4、修改spark-2.1.1-bin-hadoop2.7/conf/slave文件,添加以下内容:
hadoop04
hadoop05
hadoop06
5、在hdfs上传spark的jar包,并修改/home/software/spark-2.1.1-bin-hadoop2.7/conf/spark-defaults.conf(可不做)
①hadoop fs -mkdir /spark_jars
②hadoop fs -put /home/software/spark-2.1.1-bin-hadoop2.7/jars/* /spark_jars
③修改/home/software/spark-2.1.1-bin-hadoop2.7/conf/spark-defaults.conf,添加以下内容:
spark.yarn.jars=hdfs://hadoop01:9000/spark_jars/*
6、完成以上操作就完成了spark基于yarn的安装。下面是验证部分:
在安装有spark的节点上执行以下命令:
spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 1 \
--num-executors 3 \
/home/software/spark-2.1.1-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.1.jar \
10
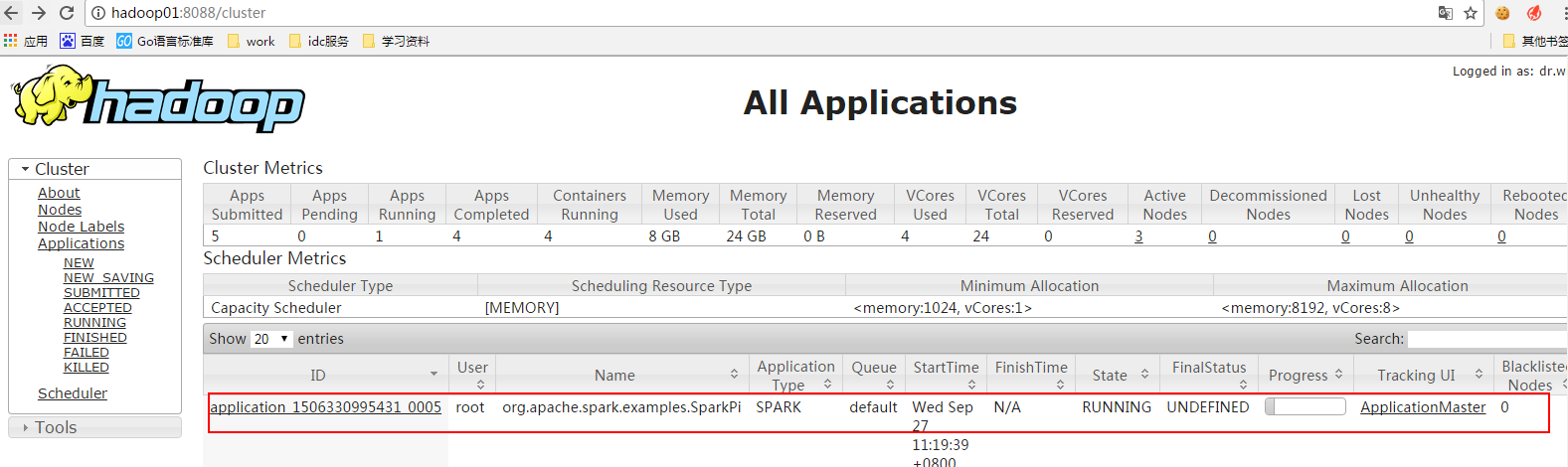
能看以上三张图就说明安装成功了!
备注:如果执行spark-shell --master yarn --deploy-mode client失败,报rpc连接失败,解决方法如下:
在hadoop的配置文件yarn-site.xml中加入:
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
报错的原因是:内存资源给的过小,yarn直接kill掉进程,则报rpc连接失败、ClosedChannelException等错误。
最新文章
- mongoose 和 mongoDB
- Android刷机教程之LG Nexus 5X线刷官方Nexus系列教程
- httpclient学习
- 烂泥:NFS存储与VSphere配合使用
- 网站程序版本号信息也可能造成bd快照严重滞后
- Redis基础知识之—— hset 和hsetnx 的区别
- objectARX判断当前坐标系
- 二叉树的基本操作(C)
- hancher57公众号突破3000人
- linux重新部署mysql和tomcat时乱码问题
- 【转载】什么是Windows USB设备路径,它是如何格式化的?
- 补充:pyhton 2 和3中的beyts类型
- CML\LVDS
- Spring Boot默认Initializer(1)——ConfigurationWarningsApplicationContextInitializer
- Wireless Penetration Testing(命令总结)
- python爬取今日头条关键字图集
- Socket,ServerSocket,WebSocket
- vue之路由嵌套,子路由
- 完整的Django入门指南学习笔记3
- Python之路-python基础一