Transformer 详解
感谢:https://www.jianshu.com/p/04b6dd396d62
Transformer模型由《Attention is all your need》论文中提出,在seq2seq中应用,该模型在Machine Translation任务中表现很好。
动机
常见的seq2seq问题,比如摘要提取,机器翻译等大部分采用的都是encoder-decoder模型。而实现encoder-decoder模型主要有RNN和CNN两种实现;
CNN
cnn 通过进行卷积,来实现对输入数据的特征提取,不同的卷积核对应于不同的特征,通过CNN的层级链接实现对目标从局部到整体的感知。

CNN主要用在图像领域,nlp里也有应用,但是不是主流。
cnn很成熟,也有一些缺陷,比如学习一句话中任意两个词语的关系时,需要多层来实现,这样关系的学习需要对数次
RNN
深度学习最早在cnn上实现了大跃进,但是在一些场景下,比如系统的输出和系统之前的状态也有关系,这就需要网络有一定的记忆功能,这时引入了RNN。RNN在进行预测时,会将系统的历史状态也作为一个输入参与,从而实现利用历史信息进行预测。
RNN 擅长处理变长序列, 在nlp中用的较多。

但是rnn也存在一些问题
- 训练和预测数据依次送入模型,并行化难度大
- 长程依赖虽然通过lstm等有所解决,但是还是不够。
- 对于层次化信息的效果建模不佳
核心问题
针对rnn和cnn的缺陷,怎么解决这些问题呢?(问题如下)
- 并行化
- 提升长程依赖的学习能力
- 层次化建模
Transformer结构
针对于上面rnn和cnn的问题,google的人提出了一种新的网络结构用来解决他们的问题。
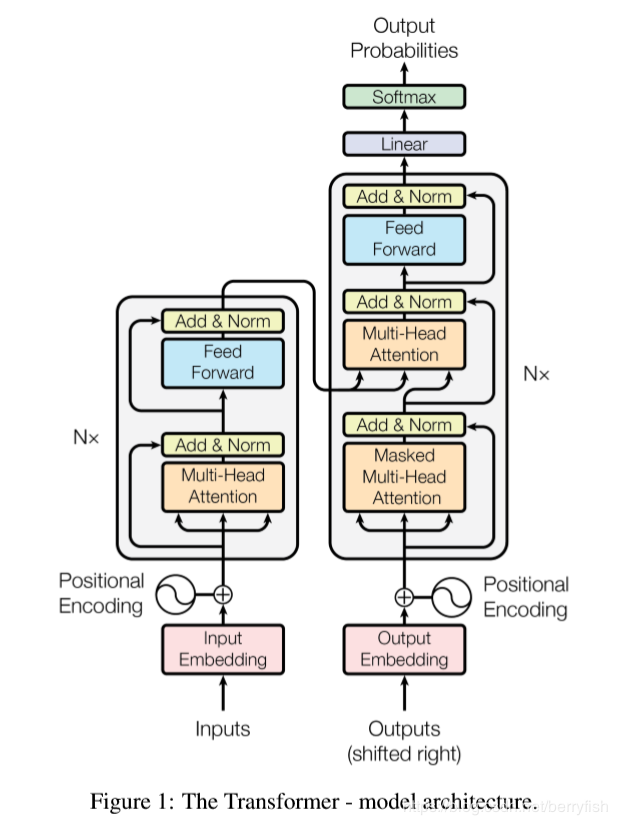
- encoder
途中左侧部分是encoder块,encoder中6层相同结构堆叠而成,在每层中又可以分为2个子层,底下一层是multihead self-attention层,上面是一个FC feed-forward层,每一个子层都有residual connection,,然后在进行Layer Normalization. 为了引入redisual connenction简化计算,每个层的输入维数和embedding层保持一致。 - decoder
同样是一个6层的堆叠,每层有三个子层,其中底下两层都是multihead self-attention层,最底下一层是有mask的,只有当前位置之前的输入有效,中间层是encode和decode的连接层,输出的self-attention层和输入的encoder输出同时作为MSA的输入,实现encoder和decoder的连接,最上层和encoder的最上层是一样的,不在单说,每个子层都有有residual connection,和Layer Normalization
亮点
self-Attention
传统的encoder-decoder实现
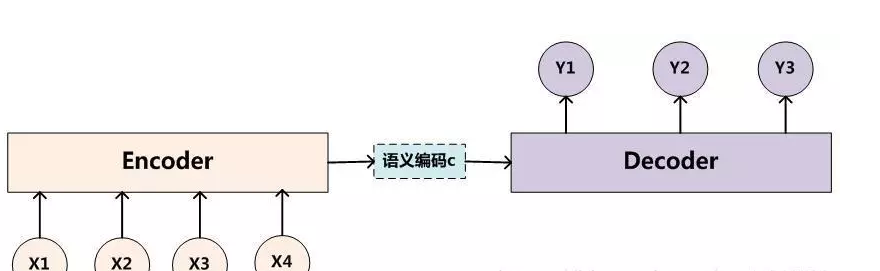
传统的编解码结构中,将输入输入编码为一个定长语义编码,然后通过这个编码在生成对应的输出序列。它存在的一个问题在于:输入序列不论长短都会被编码成一个固定长度的向量表示,而解码则受限于该固定长度的向量表示。
针对这个问题,《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》这个论文引入了attenion。他的网络结构和传统的区别在与,encoder的输出不是一个语义向量,是一个语义向量的序列,然后在解码阶段,会有选择的从向量序列中选择一个子集,这个子集怎么选取,子集元素占比的多少就是attention解决的问题。


Attention本质可以被描述为一个查询(query)到一系列(键key-值value)对的映射,如下图
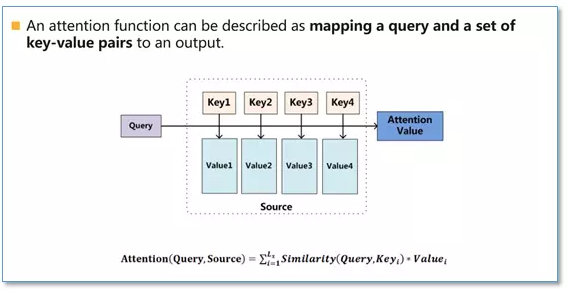
在计算attention时主要分为三步,第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;然后第二步一般是使用一个softmax函数对这些权重进行归一化;最后将权重和相应的键值value进行加权求和得到最后的attention。目前在NLP研究中,key和value常常都是同一个,即key=value。
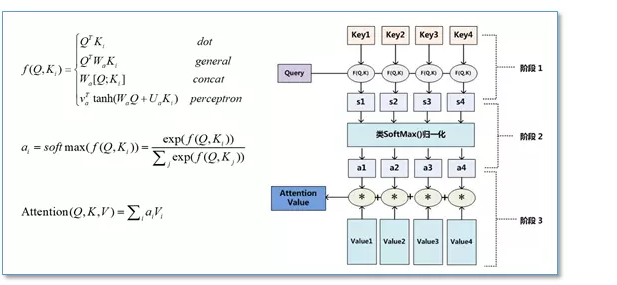
但是在Transformer的Attenion函数称为scaled dot-Product Attention,
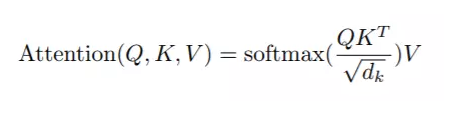
是在点积attension的基础上除了一个 √dk.论文中提到点积和Additive Attension的复杂度差不多,但是借助于优化的Matrix乘法,dot-Product在内存占用和运行速度上更优。之所以引入 √dk, 论文认为如果 key的维数 dk 特别大的话,那么有可能点积有可能变的很大,导致后面的softmax函数进入一个梯度很小的范围,不利于训练。
MultiHead Attention
上面讨论了Transformer中的Attentioin的原理,但是会有一个问题,就是计算时会分为两个阶段,第一个阶段计算出softmax部分,第二部分是在乘以 Value部分,这样还是串行化的,并行化不够。
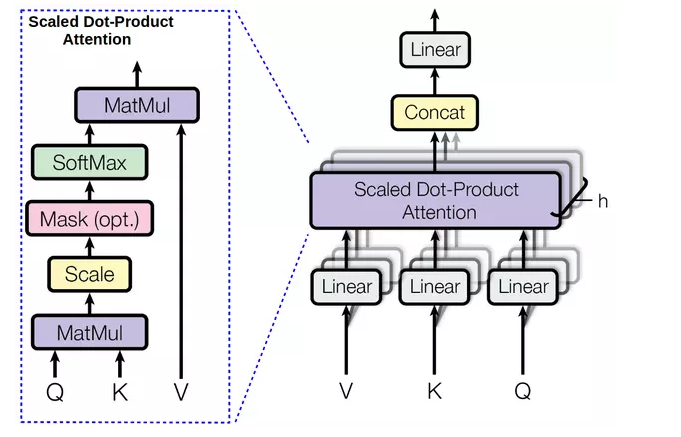
论文中采用MultiHeadAttention,对query,key,value各自进行一次不同的线性变换,然后在执行一次softmax操作,这样可以提升并行度,论文中的head数是8个。
同时不同的head学习到词语间的不同关系
position Encoding
语言是有序的,在cnn中,卷积的形状包含了位置信息,在rnn中,位置的先后顺序其实是通过送入模型的先后来保证。transformer抛弃了cnn和rnn,那么数据的位置信息怎么提供呢?
Transformer通过position Encoding来额外的提供位置信息,每一个位置对应一个向量,这个向量和word embedding求和后作为 encoder和decoder的输入。这样,对于同一个词语来说,在不同的位置,他们送入encoder和decoder的向量不同。
Transformer中的
PE(pos,2i) = sin(pos / 100002i/dmodel )
PE(pos,2i+i) = cos(pos / 100002i/dmodel )
总结一下
- 最后在看一下整个Transformer
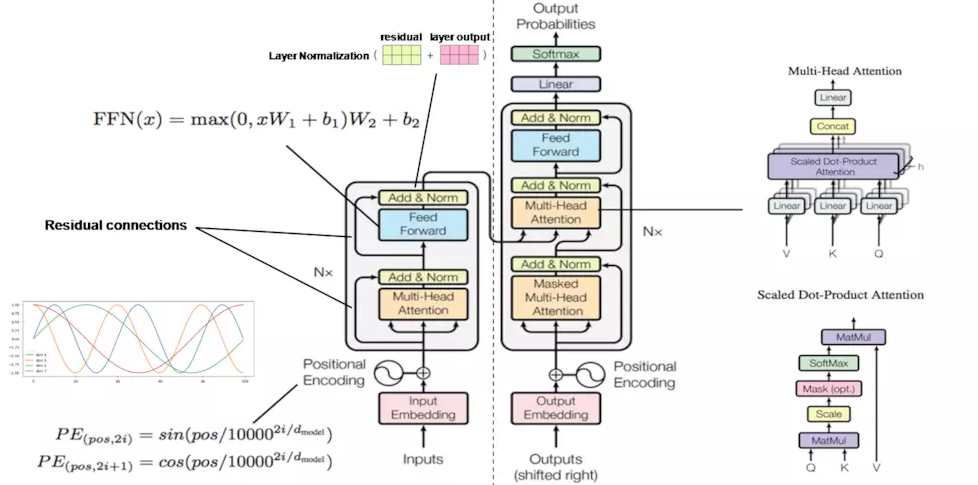
- 整体的训练过程

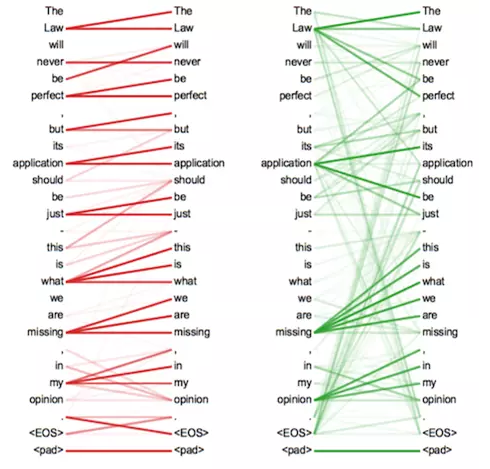
self-attension的一个效果
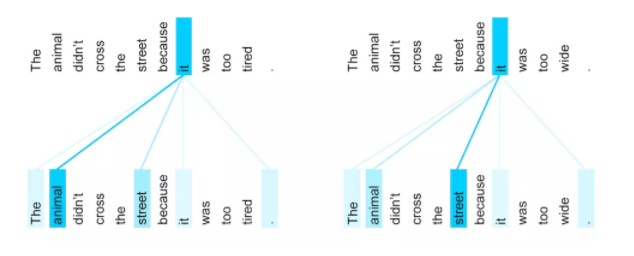
- 从效果上来看it在两个很相似的句子中,能够发现自己和不同的词语关系的变化。
最新文章
- CodeIgniter-Lottery - php ci 抽奖辅助函数
- 北大poj-1005
- gradle构建android项目
- WIN7实现多人远程一台电脑
- noip2010提高组题解
- Web技术导论复习大纲
- Windows上右键git菜单出来的原因
- Delphi 的动态数组
- ios正在使用NSDateComponents、NSDate、NSCalendar它的结论是在当前时间是在一段时间在一天。
- 自己实现一个IOC(控制翻转,DI依赖注入)容器
- 1.SpringBoo之Helloword 快速搭建一个web项目
- 利用QuickCHM制作chm
- pwn易忘操作原理笔记
- Jmeter之Redis读写
- 备份原有yum源,设置为自建yum源的脚本
- mysql新建数据库、新建用户及授权操作
- MII、GMII、RMII、SGMII、XGMII 接口区别
- function module 调用类对象
- matlab handle plot
- opencv core组件进阶