梯度提升树GBDT总结
提升树的学习优化过程中,损失函数平方损失和指数损失时候,每一步优化相对简单,但对于一般损失函数优化的问题,Freidman提出了Gradient Boosting算法,其利用了损失函数的负梯度在当前模型的值:
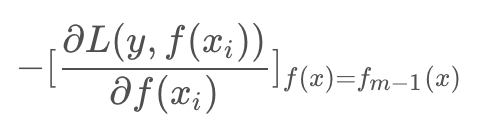
作为回归问题提升树算法的残差近似值,去拟合一个回归树。
函数空间的数值优化
优化目标是使得损失函数最小,(N是样本集合大小):

GBDT是一个加法模型: fm(x) 是每一次迭代学习的到树模型

对于其每一步迭代:
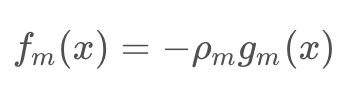
其中
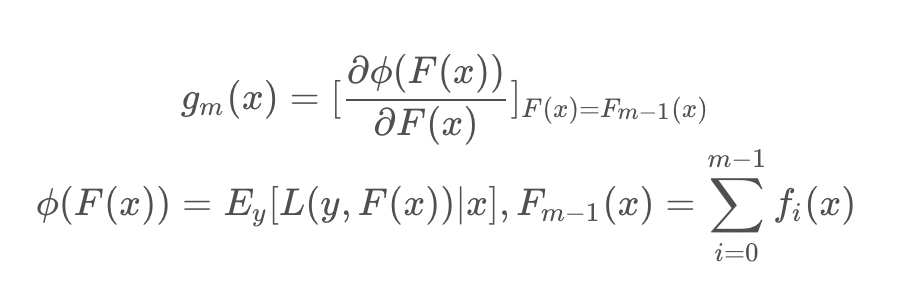
其实 L(y,F(x)) 就是损失函数,Φ(F(x)) 是当前x下的损失期望,gm(x) 是当前x下的函数梯度。最终 fm(x) 学习的是损失函数在函数空间上的负梯度。
对于权重 ρm 通过线性搜索求解:
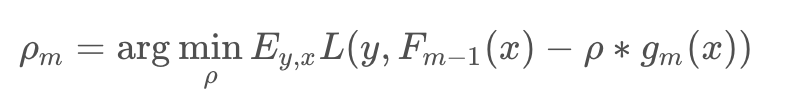
理解:每一次迭代可以看做是采用梯度下降法对最优分类器 F*(x) 的逐渐比较,每一次学习的模型 fm(x) 是梯度,进过M步迭代之后,最后加出来的模型就是最优分类器的一个逼近模型,所以 fm(xi) 使用单步修正方向 -gm(xi):
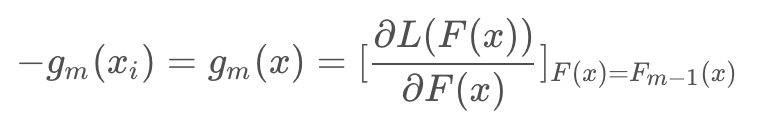
这里的梯度变量是函数,是在函数空间上求解(这也是后面XGBoost改进的点),注意以往算法梯度下降是在N维的参数空间的负梯度方向,变量是参数。这里的变量是函数,更新函数通过当前函数的负梯度方向来修正模型,使它更优,最后累加的模型近似最优函数。
算法描述
输入:训练数据集 T={(x1,y1),(x2,y2),···,(xN,yN)}
输出:回归树 fM(x)
1. 初始化

2. 对 m=1,2,…M
a. 对 i=1,2,…,N ,计算
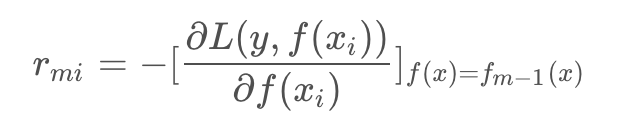
b. 对 rmi 拟合一颗回归树,得到第m棵树的叶结点区域 Rmj, j=1,2,…,J ,即一棵由J个叶子节点组成的树
c. 对 j=1,2,…,J ,计算
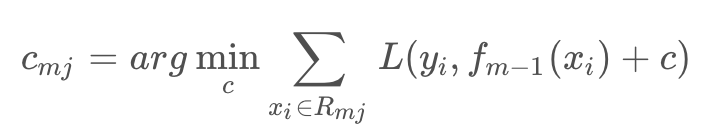
上面两步相当于回归树递归在遍历所有切分变量j和切分点s找到最优j,s,然后在每个节点区域求最优的c
d. 更新
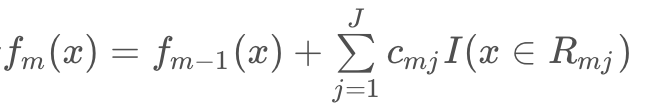
3. 得到回归树
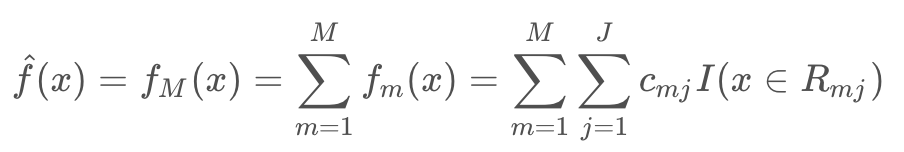
在回归树生成时,建树选择分裂点必须要遍历所有数据在每个特征的每个切分点的值,如果是连续特征就计算复杂度非常大,也是GBDT训练主要耗时所在。
参考
GBDT原理-Gradient Boosting Decision Tree
最新文章
- SecondaryNameNode的工作流程
- 根据对象的某一属性进行排序的js代码(如:name,age)
- 淘宝技术牛p博客整理
- ffmpeg将图片合成视频
- freemaker时间格式转换,精确到毫秒
- oracle一条sql语句统计充值表中今天,昨天,前天三天充值记录
- 利用传入的Type类型来调用范型方法的解决方案
- $('li','div') $('div li') $('div li')
- ※C++随笔※=>☆C++基础☆=>※№→C++中 #include<>与#include""
- 16. 使用Exhibitor管理ZooKeeper
- Mysql-单表查询的操作和注意事项
- 《HTTP - 跨域》
- fatal: could not read Username for 'https://git.dev.tencent.com' 解决方法
- ffmpeg源码编译安装(Compile ffmpeg with source) Part 2 : 扩展安装
- datatable转换为list<model> 映射
- Python GIL锁
- [转]How to Improve Entity Framework Add Performance?
- BINLOG和REDO/UNDO LOG的区别
- Sterling B2B Integrator与SAP交互 - 02 安装配置
- Vue 动态组件渲染问题分析
热门文章
- python numpy 删除array指定位置的元素
- YoloV3 训练崩溃
- world 页面横向
- 报错处理(UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' in position 2: ill egal multibyte sequence)
- $(selector).each() 和$each() 的区别
- 三:MVC之Lambda表达式
- LoadRunner(5)
- springboot同时支持访问html5和jsp时,导致后台ResponseBody返回中文乱码
- python_连接MySQL数据库(未完)
- SendMessage到底是如何工作的?