python_并发编程——消费者和生产者模型
2024-08-23 00:11:19
消费者和生产者模型
from multiprocessing import Process,Queue
import time
import random class Producer(Process):
def __init__(self,name,food,q):
super().__init__()
self.name = name
self.food = food
self.q = q
def run(self):
for i in range(1,11):
time.sleep(random.randint(1,3)) #1到3秒生产一个数据
f = '{}生产了第{}个{}'.format(self.name,i,self.food)
print(f)
self.q.put(f) class Consumer(Process):
def __init__(self,name,q):
super().__init__()
self.name = name
self.q = q def run(self):
while True:
food = self.q.get()
if food is None:
print('{}获取了一个空~结束'.format(self.name))
break #如果进程获取到空值 则跳出结束循环
else:
print('{}吃了{}'.format(self.name,food))
time.sleep(random.randint(1, 3)) if __name__ == '__main__':
q = Queue(20)
p1 = Producer('wdc','包子',q)
p2 = Producer('yhf','馒头',q)
c1 = Consumer('qqq',q)
c2 = Consumer('www',q)
p1.start()
p2.start()
c1.start()
c2.start()
p1.join() #感知p1和p2的结束
p2.join()
q.put(None) #给队列中添加两个空值,供消费者最后获取
q.put(None)
结果: ,这种方法虽然能够实现这种功能,但是如果再增加消费者的话,就要再后面继续加q.put(None)。
,这种方法虽然能够实现这种功能,但是如果再增加消费者的话,就要再后面继续加q.put(None)。
改进:
from multiprocessing import Process,JoinableQueue
import time
import random class Producer(Process):
def __init__(self,name,food,q):
super().__init__()
self.name = name
self.food = food
self.q = q
def run(self):
for i in range(1,11):
time.sleep(random.randint(1,3)) #1到3秒生产一个数据
f = '{}生产了第{}个{}'.format(self.name,i,self.food)
print(f)
self.q.put(f)
self.q.join() #阻塞,直到一个队列中的所有数据全部被处理完毕。在这里的作用就是在这里等待生产的所有的食物被吃完,再继续进行 class Consumer(Process):
def __init__(self,name,q):
super().__init__()
self.name = name
self.q = q def run(self):
while True:
food = self.q.get()print('{}吃了{}'.format(self.name,food))
time.sleep(random.randint(1, 3))
self.q.task_done() #如果是JoinableQueue,一般get()之后都要和task_done()结合使用:累次一个计数器,每取出一个数据,就做一个计数器减1 if __name__ == '__main__':
q = JoinableQueue(20)
p1 = Producer('wdc','包子',q)
p2 = Producer('yhf','馒头',q)
c1 = Consumer('qqq',q)
c2 = Consumer('www',q)
p1.start()
p2.start()
c1.daemon = True #将c1和c2都设置成守护进程,主进程的代码执行结束,守护进程自动结束。
c2.daemon = True
c1.start()
c2.start()
p1.join() #感知p1和p2的结束
p2.join()
结果: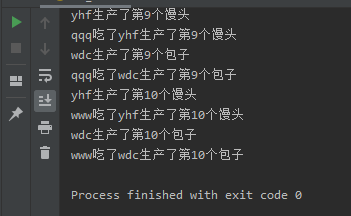
改进后的执行过程:
在消费者这一端:
每次获取一个数据,处理一个数据,发送一个记号:标志一个数据被处理成功
在生产者这一端:
每次生产一个数据,且每依次的数据都放在队列当中,当生产者生产完毕之后,发送一个join信号,表示已经停止生产数据了且在这里阻塞,等待消费者处理队列中的数据,当数据都被处理完时,join的阻塞结束。
总结:
最新文章
- c中的进制与内存分析
- [No000016]为什么假期计划总是做不到?
- PHPstorm设置连接FTP,进行文件上传、下载、比较
- bt和wifi的共存
- Mac OSX 下用 Homebrew 安装 MongoDB 并配置到 WebStorm 中
- 12. Integer to Roman
- deep learning学习环境Theano安装(win8+win7)
- leetcode—jump game
- 51Nod 1201 整数划分 (经典dp)
- datetime方法
- 警惕!MySQL成数据勒索新目标
- vuex使用报错
- js版贪吃蛇
- C# 找出泛型集合中的满足一定条件的元素 List.Wher()
- ORACLE数据库学习之SQL性能优化详解
- childNodes遍历DOM节点树
- Data Persistence
- pandas聚合aggregate
- 【JVM】jvm至jstack命令
- SSH:Struts + Spring + Hibernate 轻量级Java EE企业框架