统计--VARCHAR与NVARCHAR在统计预估上的区别
最近遇到一个问题,当查询使用到模糊查询时,由于预估返回行数过高,执行计划认为索引查找+Key Lookup的成本过高,因此采用Clustered Index Scan的方式,消耗大量逻辑IO,执行计划较差。
经过测试,发现对于模糊查询,NVARCHAR和VARCHAR的预估返回行数差距很大,因此拿出来供大家一起测试。
首先生成测试数据,分别创建TB101和TB102的表,表上有相同的聚集索引和非聚集索引,表中有100w数据,创建测试数据脚本如下:
DROP TABLE TB101
GO
DROP TABLE TB102
GO
SELECT
CAST(NCHAR(19968+20902*RAND(RID))+NCHAR(19968+20902/2*RAND(RID))+NCHAR(19968+20902/3*RAND(RID)) AS varchar(40)) AS RName
,*
INTO TB101
FROM(
SELECT ROW_NUMBER()OVER(ORDER BY T1.OBJECT_ID DESC) AS RID,T1.* FROM sys.all_objects T2
CROSS JOIN sys.all_columns T1
) AS T
WHERE T.RID<1000000
GO
SELECT * INTO TB102 FROM TB101
GO
ALTER TABLE TB102
ALTER COLUMN RName NVARCHAR(40)
GO
CREATE UNIQUE CLUSTERED INDEX IDX_RID ON TB101(RID)
GO
CREATE UNIQUE CLUSTERED INDEX IDX_RID ON TB102(RID)
GO
CREATE INDEX IDX_Name ON TB101(RName)
GO
CREATE INDEX IDX_Name ON TB102(RName)
GO EXEC sp_spaceused 'TB101'
EXEC sp_spaceused 'TB102'
GO
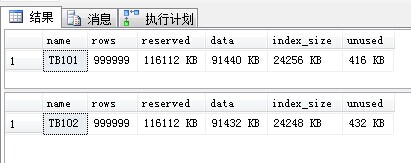
两表使用空间相同,数据相同。
测试前先更新下统计:
--更新统计
UPDATE STATISTICS TB101 WITH FULLSCAN
GO
UPDATE STATISTICS TB102 WITH FULLSCAN
开始测试1
SELECT RName FROM TB101
WHERE RName LIKE '你好%'
其执行计划为: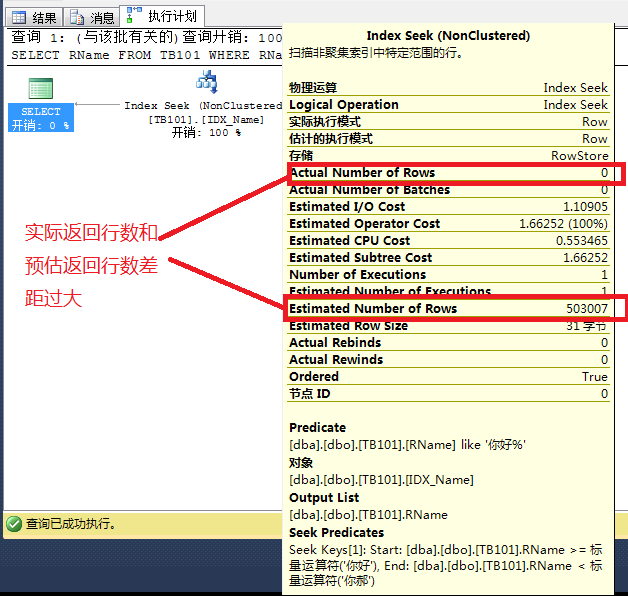
测试2:
SELECT RName FROM TB102
WHERE RName LIKE N'你好%'

感谢网友“ 害怕飞的鸟”的提醒,我们测试了以中文开头的模糊查询,需要测试以字母开头的模糊查询。
因此重新创建测试用例(生成新的测试数据目的为了避免查询值落在统计的两端,原理请参考大神高继伟的SQL Server 统计信息(Statistics)-概念,原理,应用,维护)
准备测试数据:
SELECT
CAST(NCHAR(65+25*RAND(RID))+NCHAR(24*RAND(RID))+NCHAR(19968+20902/2*RAND(RID))+NCHAR(19968+20902/3*RAND(RID)) AS varchar(40)) AS RName
,*
INTO TB103
FROM(
SELECT ROW_NUMBER()OVER(ORDER BY T1.OBJECT_ID DESC) AS RID,T1.* FROM sys.all_objects T2
CROSS JOIN sys.all_columns T1
) AS T
WHERE T.RID<1000000
GO
SELECT * INTO TB104 FROM TB103
GO
ALTER TABLE TB104
ALTER COLUMN RName NVARCHAR(40)
GO
CREATE UNIQUE CLUSTERED INDEX IDX_RID ON TB103(RID)
GO
CREATE UNIQUE CLUSTERED INDEX IDX_RID ON TB104(RID)
GO
CREATE INDEX IDX_Name ON TB103(RName)
GO
CREATE INDEX IDX_Name ON TB104(RName)
GO
测试1:
SELECT RName FROM TB103
WHERE RName LIKE 'A你好%'

测试2:
SELECT RName FROM TB104
WHERE RName LIKE N'A你好%'

通过上面四个测试,可以得出以下结论:
1. 当字段的数据类型为NVARCHAR时,无论模糊查询以中文还是英文字母开头,预估返回行数和实际返回行数相差不多
2. 当字段的数据类型为VARCHAR且模糊查询以英文字母开头,预估返回行数和实际返回行数相差不多
3. 当字段的数据类型为VARCHAR且模糊查询以中文开头,预估返回行数和实际返回行数相差较大。
--==============================================================
当预估返回行数与实际返回行数相差较大时,就很容易生成较差的执行计划,如对于查询:
SELECT * FROM TB101
WHERE RName LIKE '你好%'
由于预估索引查找会返回50w的数据,查询优化器引擎认为如果使用索引查找+Key Lookup就会消耗上200W+的逻辑IO, 效率会远低于表扫描,因此有了下面的执行计划:
而实际上,经过索引查找后,只会返回少量的数据行,这些行做Key Lookup也只会消耗少量的逻辑IO,因此索引查找+Key Lookup是最高效的。
解决办法:
对于这种问题,可以有几种办法处理:
1. 强制索引查找
SELECT * FROM TB101 WITH(FORCESEEK)
WHERE RName LIKE '你好%'
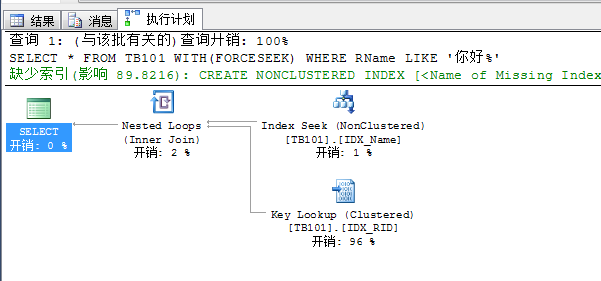
2. 使用隐式转化
SELECT * FROM TB101
WHERE RName LIKE N'你好%'

经过一次隐式转换后,预估返回行数出奇地下降下来,生成了正确的执行计划(看来隐式转换也是有存在价值地哦)
3. 如果不想修改程序的话,可以考虑使用参数化和执行计划指南来实现
--=========================================================================================
总结(以下结论未经过大神认证,请自行组鉴别正确性):
1. 当字段的数据类型为NVARCHAR时,无论模糊查询以中文还是英文字母开头,预估返回行数和实际返回行数相差不多
2. 当字段的数据类型为VARCHAR且模糊查询以英文字母开头,预估返回行数和实际返回行数相差不多
3. 当字段的数据类型为VARCHAR且模糊查询以中文开头,预估返回行数和实际返回行数相差较大。
4. 隐式转换未必会导致表扫描或索引扫描,也未必会导致执行计划质量不优。
--===========================================================


最新文章
- sublime 相关配置
- 将本地项目提交到coding上托管
- 四种常见的 POST 提交数据方式
- js for in对象key排序
- MySQL: ON DUPLICATE KEY UPDATE 用法 避免重复插入数据
- Redis未授权访问缺陷让服务器沦为肉鸡
- Android系统Surface机制的SurfaceFlinger服务的启动过程分析
- OleContainer操作Excel以二进制方式读写数据库
- monkeyscript - 定制化monkey流程
- ubuntu批量更改文件权限
- getopts的使用
- 协议无关组播-密集模式 PIM-DM
- idea 和eclipse的debug调试快捷键对比
- Redis常见面题
- Android 扩大view点击范围
- 利用扩展方法重写JSON序列化和反序列化
- ASP.NET MVC 手机短信验证
- JAVA数据类型中的char类型
- C语言调用Intel处理器CPUID指令的实例
- sonarQube6.1 升级至6.2