kettle大数据量读写mysql性能优化
修改kettleDB连接设置
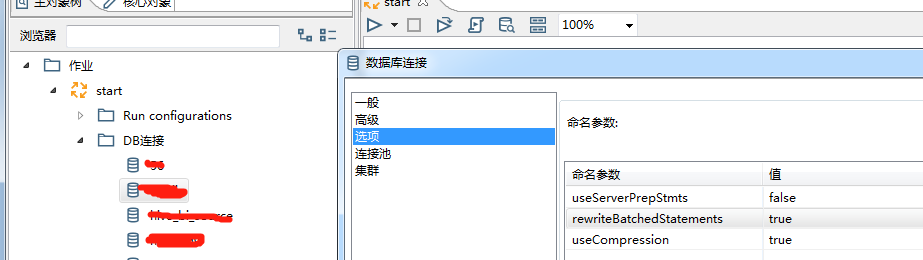
1. 增加批量写的速度:
useServerPrepStmts=false
rewriteBatchedStatements=true
useCompression=true
2. 增加读的速度:
useServerPrepStmts=true
cachePrepStmts=true
参数说明:
1)useCompression=true,压缩数据传输,优化客户端和MySQL服务器之间的通信性能。
2)rewriteBatchedStatements=true ,开启批量写功能
将会使大批量单条插入语句:
INSERT INTO t (c1,c2) VALUES ('One',1);
INSERT INTO t (c1,c2) VALUES ('Two',2);
INSERT INTO t (c1,c2) VALUES ('Three',3);
改写成真正的批量插入语句:
INSERT INTO t (c1,c2) VALUES ('One',1),('Two',2),('Three',3);
3)useServerPrepStmts=false 关闭服务器端编译,sql语句在客户端编译好再发送给服务器端,发送语句如上。
如果为true,sql会采用占位符方式发送到服务器端,在服务器端再组装sql语句。
占位符方式:INSERT INTO t (c1,c2) VALUES (?,?),(?,?),(?,?);
此方式就会产生一个问题,当列数*提交记录数>65535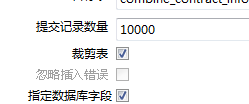
时就会报错:Prepared statement contains too many placeholders,
这是由于我把“提交记录数量”设为10000,而要插入记录的表字段有30个,所以要进行批量插入时需要30*10000=300000 > 65535 ,故而报错。
解决方案:
方案1:把DB连接中的 rewriteBatchedStatements 给设置为false(或者去掉),不过这个操作会影响数据的插入速度。
方案2:更改表输出的设计。确保30个输出字段的和提交记录数量的乘积不超过65535。比如把提交记录数量由10000更改为450(30*2000=60000< 65535)
当然我们的目的是为了提高数据库写速度,所以当rewriteBatchedStatements =true时useServerPrepStmts=false必须配合使用。
mysql参数调优可以参考如下文档
https://dev.mysql.com/doc/connectors/en/connector-j-reference-configuration-properties.html
数据丢失问题:
性能提升后,遇到另外个问题,86万数据丢失了130多条,kettle无报错,各种mysql参数设置之后都无效果,耗时近一天,最终查到是重复数据导致。
估计是因为重复数据在mysql写不进去导致该批次数据写失败,但是kettle无报错这个就比较坑。
解决办法就是:1)取消数据表主键或者唯一索引 ,当然这是治标不治本的做法。2)根本的做法就是排查重复数据,从源头杜绝重复数据
参考文档:
https://blog.csdn.net/smooth00/article/details/69389424?utm_source=itdadao&utm_medium=referral
http://www.jackieathome.net/archives/169.html
最新文章
- UWP toast
- 13.allegro 颜色设置[原创]
- Zookeeper基本知识
- Citrix服务器虚拟化之三十 XenApp 6.5发布流式应用程序
- bzoj1878
- Win7 64位安装MySQL
- Phonegap 安卓的自动升级与更新。当版本为4.0的时候
- [译]Java垃圾回收是如何工作的
- ClassLoader类加载解惑
- WPF 10天修炼 第九天 - 几何图形
- 无知小子踏入python web大门
- 使用TPC-DS工具生成数据
- docker_macvlan
- css的小知识3
- python内置模块之collections(六)
- Kubernetes中的nodePort,targetPort,port的区别和意义(转)
- Camera2点击对焦实现2
- Lazarus的二维码解决方案
- FreeRTOS基础篇教程目录汇总
- 堆排序 思想 JAVA实现