Kafka项目实战-用户日志上报实时统计之分析与设计
1.概述
本课程的视频教程地址:《Kafka实战项目之分析与设计》
本课程我通过一个用户实时上报日志案例作为基础,带着大家去分析Kafka这样一个项目的各个环节,从而对项目的整体设计做比较合理的规划,最终让大家能够通过本课程去掌握类似Kafka项目的分析与设计。下面,我给大家介绍本课程包含的课时内容,如下图所示:

接下来,我们开始第一课时的学习:《项目整体概述》。
2.内容
2.1 项目整体设计
项目整体概述主要讲解一个项目产生的背景,以及该项目背后的目的,从而让大家更好的去把握项目的需求。
本课时所涉及的主要知识点,如下图所示:

那么,接下来,我就先从背景来给大家简述一个项目,背景包含一下知识点,如下图所示:

前面我已经给大家说明了,这是一个实时统计项目,我们可以实时的访问记录, 通过实时流式计算后,得到用户实时的访问行迹。这个和离线计算有所区别,离线计算任务,不能立马得到我们想要的结果。
那么,这样一个项目我们能得到什么好处,举个例子:
业绩部门的同事需要知道当天的用户实时浏览行迹,而针对这一需求,我们可以通过实时计算后,将统计后的结果 通过图表可视化出来,让业绩部门的同事可以非常清晰的知道,公司的用户对公司的那些业务模块赶兴趣,需求量比较大, 那么业绩部门的同事,可以这一块重点投入,对那些不是很赶兴趣,需求量较小的模块,业绩部门的同事可以投入的成本相对低一些。
以上便是我为大家介绍的项目背景,下面我给大家介绍项目的目的。
项目的目的所包含的内容,如下图所示:

关于详细的目的内容,这里我就不多做赘述了。《观看地址》
2.2 Producer 模块分析
Producer模块分析一课给大家介绍数据生产环节,我带着大家去分析生产数据来源,让大家掌握数据如何收集到 Kafka 的 Producer 模块。
其主要知识点包含以下内容,如下所示:

下面,我们先去分析数据来源。我们知道,在日志记录中一条日志记录代表用户的一次活动形迹,下面我我从实时日志记录中抽取的一条用户记录,如下所示:
121.40.174.237 yx12345 [/July/ :: +] chrome appid_5 "http://www.***.cn/sort/channel/2085.html"
那么通过观察分析这条记录,我们可以从示例数据中得到那些信息量,这里我给大家总结到一张图上了,如下图所示:

在分析了日志记录的信息量,我们接下来去看看是如何收集到这些数据的,整个收集数据的流程是怎么样的,下面我用一张图来给大家,如下图所示:

从图中,我们可以看出,数据的产生的源头是用户,从图的左边开始看起,用户通过自己手上的终端(有可能是: PC机,手机,pad等设备去访问公司的网站),而这里访问的记录都会被实时的记录到服务器,我们在部署网站的的节点上添加 Flume的Agent代理,将这些实时记录集中收集起来,然后我们在Flume的Sink组件处添加输送的目标地址,这里我们是要将这些 实时的记录输送到Kafka集群的,所以在Sink组件处填写指向Kafka集群的信息,这样收集的实时记录就被存储在Kafka的 Producer端,然后,这部分数据我们就可以在下一个阶段,也就是消费阶段去消费这些数据。
以上就是整个实时数据的采集过程,由用户产生,Flume收集并传输,最后存放与Kafka集群的Producer端等待被消费。
关于具体细节,这里就不赘述了。《观看地址》
2.3 Consumer 模块分析
该课时我给大家介绍数据消费环节,带着大家从消费的角度去分析消费的数据源,让大家掌握数据如何在Kafka中被消费。
其主要知识点包含以下内容,如下所示:

那么,下面我先带着大家去分析消费数据来源,关于消费数据来源的统计的KPI指标,如下图所示:

从图中,我们可以看出,由以下KPI指标:
- 业务模块的访问量:这里通过记录中的App Id来统计相关指标。
- 页面的访问量:关于PV,这里我们可以使用浏览记录来完成这部分的指标统计。
- 当天时段模块的访问量:而时间段的访问量,可以通过用户访问的时间戳,来完成这部分的指标统计。
- 访问者的客户端类型:在每条访问记录中,都含有对应的访问浏览设备类型,我们提取这部分内容来完成相应的统计指标。
以上便是我给大家分析消费数据的相关信息所设计的内容。
接下来,我带着大家去看看本课时的另一个比较重要的知识点,那就是关于数据源的消费流程。这里,我用一张图来给大家描述了整个消费过程,如下图所示:
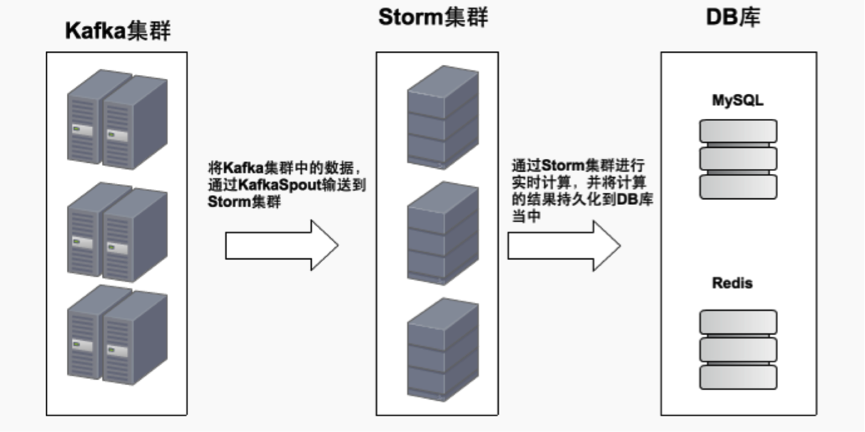
我们先从图的最左边看起,这个是Kafka的集群,在这个集群中,存放着我们即将要被消费的数据,这里,我们通过KafkaSpout 将Kafka和Storm联系起来,将Kafka集群中要消费的数据,通过KafkaSpout输送到Storm集群,然后数据进入到Storm集群后, 通过Storm的实时计算模型,按照业务指标做对应的计算,并将计算之后的结果持久化到DB库当中去,这里同时采用MySQL和Redis 来做持久化。
以上,便是我给大家描述的如何去消费Kafka集群中数据的流程。《观看地址》
2.4 项目整体设计
该课时我给大家介绍设计一个项目的整体架构和流程开发,以及 KPI 的设计,让大家能够通过本课时去掌握一个项目的设计流程。
其主要知识点包含以下内容,如下所示:

下面,我先给大家去分析本项目的详细设计流程,这里我绘制了一张图来描述整个项目设计流程的相关信息,如下图所示:

从图的最左边开始,依次是:
- 数据源:这部分数据在用户访问公司网站的时候就会产生对应的记录,我们只需要在各个网站节点添加对应的Flume的Agent代理即可。
- 数据收集:这里我们使用Flume集群去收集访问的日志记录,在收集完数据后,进入到下一阶段。
- 数据接入:在该模块下,使用Kafka来充当一个消息数据的核心中间件,通过Flume的Sink组件,将数据 发送到Kafka集群,这样在Kafka的生产端就有了数据,这些数据等待去被消费。那么接下来,通过KafkaSpout 将Kafka集群和Storm集群关联起来,将Kafka集群中的数据,由KafkaSpout输送到Storm集群,这样消费端的数据就流向了Storm集群。
- 流式计算:在数据进入到Storm集群后,通过Storm的实时计算模型,将数据按照业务需要完成对应的指标计算,并将统计的 结果持久化到DB库当中。
- 持久化层:在持久化层,这里选用MySQL和Redis来做持久化存储,统计结果出来后,进入到下一阶段。
- 数据接口层:这里我们可以编写一个RPC服务,统一的将统计结果共享出去,这里RPC服务所采用的是Thrift,完成数据的共享。
- 可视化层:这里由前端统一查询Thrift数据共享接口,将统计结果展示出来,完成数据的可视化。
以上,便是我给大家介绍本项目的整个流程设计的相关内容。关于其他的细节内容,这里就不多赘述了。《观看地址》
3.总结
本课程我们对项目进行了整体分析,并指导大家去分析 Kafka 的 Producer 模块和 Consumer 模块,以及帮助大家去设计项目的开发流程等知识,我们应该掌握以下知识点,如下图所示:

4.结束语
这就是本课程的主要内容,主要就对 Kafka 项目做前期准备,对后续学习 Kafka 项目实战内容奠定良好的基础。
如果本教程能帮助到您,希望您能点击进去观看一下,谢谢您的支持!
转载请注明出处,谢谢合作!
本课程的视频教程地址:《Kafka实战项目之分析与设计》
最新文章
- JDK Collection 源码分析(1)—— Collection
- HBase Shell操作
- codevs1225 八数码难题
- S盒
- Failed to load libGL.so in android
- 学习总结(annotation)
- 纯CSS3代码实现表格奇偶行异色,鼠标悬浮变色
- OPENGL 地形
- struts2整合spring出现的Unable to instantiate Action异常
- HDU 2653 - Waiting ten thousand years for Love
- redis的适应场景
- 自学Zabbix3.4-资产清单inventory
- Bootstrap-datepicker3官方文档中文翻译---Methods/方法(原文链接 http://bootstrap-datepicker.readthedocs.io/en/latest/index.html)
- 获取Xcode工程所有的类名
- 用软件工程分析开源项目octave的移植
- Java基础95 过滤器 Filter
- webpack学习总结(一)
- Charles在Mac中抓包使用说明
- IIS 无法识别的属性“targetFramework”---解决之道
- HQS——Half Quadratic Splitting半二次方分裂