【Lua篇】静态代码扫描分析(二)词法分析
2024-08-28 21:49:19
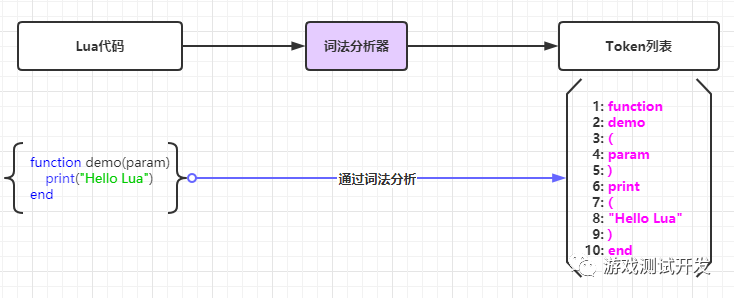
一、词法分析
词法分析(英语:lexical analysis)是计算机科学中将字符序列转换为单词(Token)序列的过程。进行词法分析的程序或者函数叫作词法分析器(Lexical analyzer,简称Lexer),也叫扫描器(Scanner)。词法分析器一般以函数的形式存在,供语法分析器调用。
二、Lua词法分析器
首先需要读取Lua文件中的内容,然后逐字符读取进行判断组合成一个一个的单词。判断单词就需要了解Lua语言中的数据类型,具体如下:
1. 变量标识符
- 单个字符 例如a = 1中的“a”
- 多个字符 例如 player
- 下划线开头 例如 _key
- 字符和数字组合 例如 key123、_key23
2. 数字
- 整数 例如 123、0、2021
- 小数 例如 3.1415926、.41
- 十六进制 例如 0x0044、0XFF1A、0xab12
- 科学计数法 例如 2e-2、0.2e+1
3. 字符串
- 双引号 "Hello Lua"
- 单引号 'abcd'
- 双中括号(多行) [[xxzz]]
4. 关键字
本质上可以和标识符合并,然后读取出来后再进行匹配。
5. 操作符号
- 算术运算 +、-、*、/、%
- 比较运算 >、<、==、>=、<=
- 赋值运算 “=”
- 位运算
- 字符串连接符 “..”
6. 注释
- 单行注释 以 “--”开始 到 行末
- 多行注释 “--[[” 开始 到 “]]” 结束
大体了解了Lua语言的组成后,就可以开始编写词法分析程序了,下面展示了部分代码用于说明整个词法分析的过程。
1) 首先需要写字符的处理方法。
get_char 用于从字符流中取出下一个字符;
peek_char 返回下一个字符但不从字符流中取出;
put_char 将取出的字符放回去。
1 def get_char(self):
2 """ 取出下1个字符 """
3 if self._Index + 1 < self._FileSize:
4 self._Index += 1
5 return self._StreamBuff[self._Index]
6 else:
7 return None
8 def peek_char(self):
9 """ 获取下1个字符,但不取出 """
10 if self._Index + 1 < self._FileSize:
11 return self._StreamBuff[self._Index + 1]
12 return None
13 def put_char(self):
14 """ 回退获取的字符 """
15 if self._Index > -1:
16 self._Index -= 1
2) 识别并组成一个Token单词。
循环获取字符,并进行逐个条件判断,最终形成一个单词(Token)。需要注意数字和字符的组合、减号、小数点等的判断。
1 def parse_read_token(self):
2 c = self.get_char()
3 token_str = ""
4 token_type = TokenType.L_EOF
5 while c is not None:
6 if c in TokenType.SkipWords:
7 c = self.get_char()
8 continue
9 elif c.isdigit(): # ....
10 elif c.isalpha() or c == '_':
11 elif c == '.': # ....
12 elif c == '\"' or c == "\'": # 字符串
13 elif c == '[': # 区分[ 和 [[
14 elif c == '{': # ....
15 elif c == '(': # ....
16 elif c == ']': # ....
17 elif c == '}': # ....
18 elif c == ')': # ....
19 elif c in TokenType.Operators: # ....
20 else: # error
21 c = self.get_char()
22 return Token(token_type, token_str)
3)循环读取全部的Token直到文件字符数据流结尾。
1 def parse(self):
2 while True:
3 token = self.parse_read_token()
4 if token.tokenType == TokenType.L_ERROR:
5 return False
6 elif token.tokenType == TokenType.L_EOF:
7 break
8 elif token.tokenType != TokenType.L_COMMENT:
9 self.mTokens.append(token)
10 return True
三、总结
通过上面的几步就可以完成对Lua文件中的字符流进行分析,然后组成Token流。Token流将会是语法分析的输入内容。以上就是Lua词法分析的内容,写完分析程序后还需要多调试,使用不同风格编写的Lua代码文件进行测试。
文章来自我的公众号,大家如果有兴趣可以关注,具体扫描关注下图。

最新文章
- arcgis api for js入门开发系列八聚合效果(含源代码)
- 理解 Neutron FWaaS - 每天5分钟玩转 OpenStack(117)
- [转]《Hadoop基础教程》之初识Hadoop
- iOS开发UI篇—常见的项目文件介绍
- Terminal的快捷键 for Terminal for Mac OS 10.10, Linux/GNU(Ubuntu, deepin, elementory os,CentOS)
- [转载]新功能:用微软的Live Writer离线写博文
- McAfee VirusScan Enterprise
- UVa 1648 (推公式) Business Center
- entity framework in mysql
- svn is alread locked
- SUN-LDAP6.3_RHEL 5.0-卸载LDAP
- 纯CSS3实现loading正在加载。。。
- springmvc报406错误
- 【翻译】在Ext JS 5应用程序中如何使用路由
- [SQL]LeetCode595. 大的国家 | Big Countries
- python Django cookie和session
- Java:内省(Introspector)
- 利用itext生成pdf的简单例子
- ES基本查询
- WIN10系统如何关闭用户账户控制