Mybatis3源码笔记(六)SqlSession执行过程
2024-10-11 21:01:06
前几篇大致分析了初始化的过程,今天打算走一个SqlSession具体执行过程。
@Test
void shouldSelectAllAuthors() {
try (SqlSession session = sqlMapper.openSession(TransactionIsolationLevel.SERIALIZABLE)) {
List<Author> authors = session.selectList("org.apache.ibatis.domain.blog.mappers.AuthorMapper.selectAllAuthors");
assertEquals(2, authors.size());
}
}
1.首先sqlMapper就是上面几篇的分析得来了,就不累述了。
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
//取出Environment
final Environment environment = configuration.getEnvironment();
//根据你xml中的配置,创建事务工厂来生成事务
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//生成executor跟底层的Statement来打交道,用来真正执行CRUD.
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}

事务管理分成上图两种,一种是传统的JDBC事务管理,一种是交给自身的容器去调用控制。
2.Executor的生成也很有趣。用到了许多设计模式,说到这,感觉看源码能把平时躺在冰冷纸面上的设计模式一个个鲜活的展示出来,也算是真的学以致用,而且mybaits的源码说实在的已经算是比较简单的了,spring的源码真是让人头大。
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
//典型的工厂模式,三种类型的executor
if (ExecutorType.BATCH == executorType) {
//批量执行器
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
//可重用执行器(用到了享元模式,用到statementMap来缓存同一生命周期内的statement。)
executor = new ReuseExecutor(this, transaction);
} else {
//默认的简单执行器
executor = new SimpleExecutor(this, transaction);
}
//开启二级缓存的话,再外面再包一层CachingExecutor,装饰者模式
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
//插件机制,其实就是一个动态代理的拦截器链,用到了一个责任链模式,留到后篇详解
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
executor接口的实现类的关系如下图:
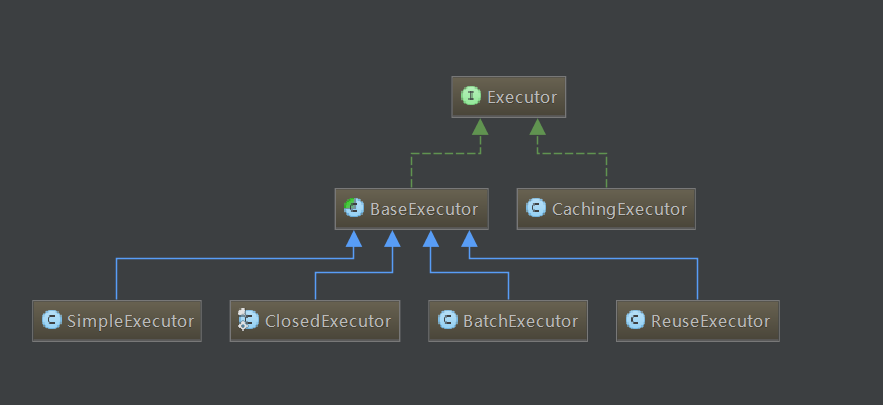
BaseExecutor采用了设计模式中的模板模式,把一些共通的方法写在里面,抽象了一些方法留给子类自己实现。
3.看下具体的select操作。
private <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds, ResultHandler handler) {
try {
//取出configuration中保存的MappedStatement对象
MappedStatement ms = configuration.getMappedStatement(statement);
//wrapCollection把入参进行一个封装,如果是集合类型做转换成ParamMap
return executor.query(ms, wrapCollection(parameter), rowBounds, handler);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
具体我们走二级缓存从CachingExecutor的query里看看代码的实现。
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
//取得BoundSql
BoundSql boundSql = ms.getBoundSql(parameterObject);
//根据statementId + rowBounds + 传递给JDBC的SQL + 传递给JDBC的参数值生成CaccheKey
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
//获得MappedStatement中关联的Cache,默认情况下,一个mapper文件下的命名空间对应一个cache,如果要多个mapper共享一个cache,要用到cache-ref
Cache cache = ms.getCache();
if (cache != null) {
//判断是否要强制刷新缓存
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
//验证不支持有OUT类型的参数
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
//根据key从对应的cache中拿value
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
//缓存没命中,走DB
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
//同时把对应的数据放入缓存
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
//不支持缓存,直接走DB
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
MyBatis查询数据的顺序是:二级缓存 ———> 一级缓存 ——> 数据库。既然说到缓存了,干脆就整理下。以下是MyBatis的缓存机制大致图解:
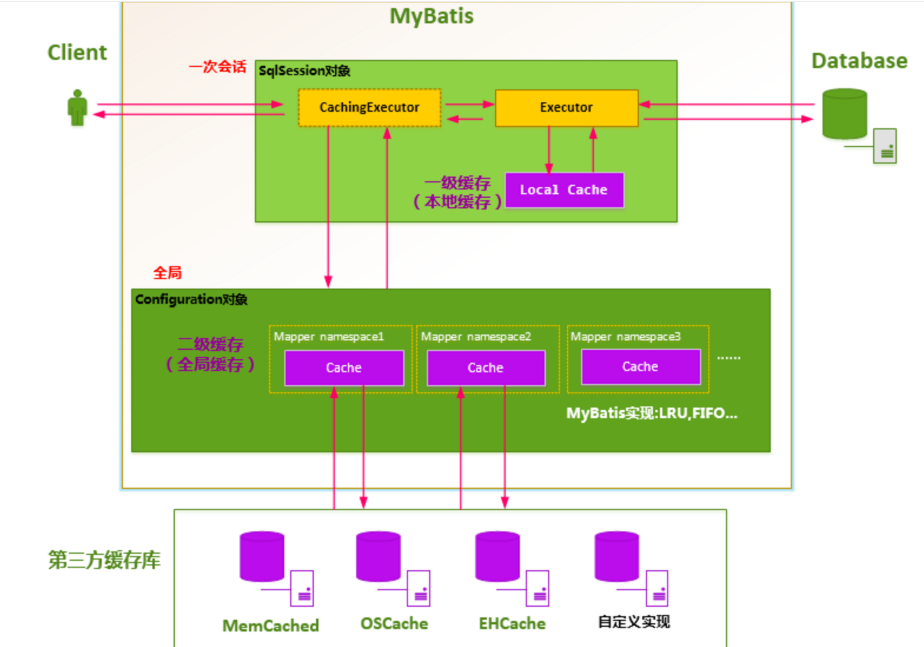
先说下二级缓存,Cache的默认实现类是PerpetualCache,其实就是个普通map。
- 二级缓存的作用域是全局的,二级缓存在SqlSession关闭或提交之后才会生效。一级缓存的生命周期是在sqlsession的生命周期内。
- 映射语句文件中的所有 select 语句的结果将会被缓存。映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
- 缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。这个我们在解析
addMappedStatement时就有对应的代码。
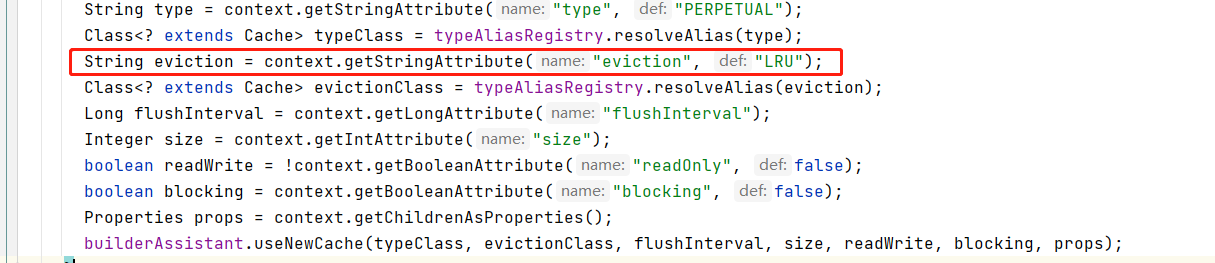
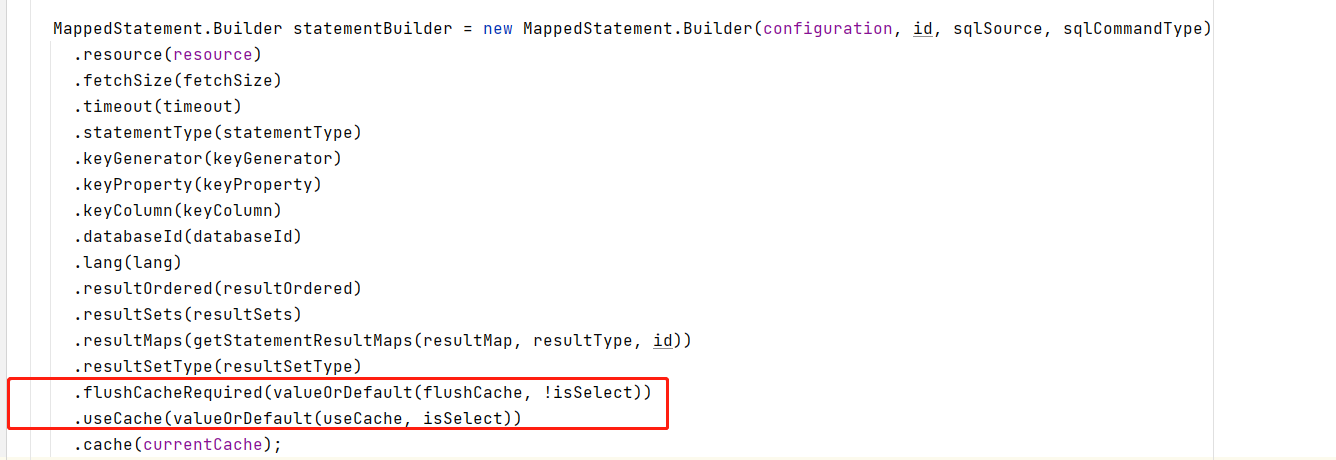

4.我们看下CachingExecutor中缓存是如何保存。
public class CachingExecutor implements Executor {
//真正执行数据库操作的executor
private final Executor delegate;
//缓存事务管理器
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
...
TransactionalCacheManager为什么称为缓存事务管理器,是因为他是事务执行和二级缓存之间的过渡器,说白了我们从DB中拿到的数据到底放不放到二级缓存内,是不一定的。因为事务在执行期间内是可以回滚的,没到commit那一刻,都有回滚的可能性。这也就是上面说的第一条,二级缓存的作用域是全局的,二级缓存在SqlSession关闭或提交之后才会生效。具体我们来跟一下代码。
public class TransactionalCacheManager {
//管理了一个HashMap,key是=Cache,value=TransactionalCache,Cache是我们从`Configuration`里解析出来的,一个配置文件里的Cache肯定是全局共享的。
//TransactionalCache就是那个二级缓存事务缓冲区,它完全就是为二级缓存做了一个静态代理,实现了相同的Cache接口。
private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap<>();
public void clear(Cache cache) {
getTransactionalCache(cache).clear();
}
public Object getObject(Cache cache, CacheKey key) {
return getTransactionalCache(cache).getObject(key);
}
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}
public void commit() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.commit();
}
}
//
public void rollback() {
for (TransactionalCache txCache : transactionalCaches.values()) {
txCache.rollback();
}
}
private TransactionalCache getTransactionalCache(Cache cache) {
return transactionalCaches.computeIfAbsent(cache, TransactionalCache::new);
}
}
//为二级缓存做了一个静态代理,实现了相同的Cache接口
public class TransactionalCache implements Cache {
private static final Log log = LogFactory.getLog(TransactionalCache.class);
//真正的二级缓存
private final Cache delegate;
private boolean clearOnCommit;
//缓冲区待向二级缓存传输的数据
private final Map<Object, Object> entriesToAddOnCommit;
//二级缓存中没命中的数据
private final Set<Object> entriesMissedInCache;
public TransactionalCache(Cache delegate) {
this.delegate = delegate;
this.clearOnCommit = false;
this.entriesToAddOnCommit = new HashMap<>();
this.entriesMissedInCache = new HashSet<>();
}
@Override
public Object getObject(Object key) {
// issue #116(从二级缓存里取数据)
Object object = delegate.getObject(key);
//没命中
if (object == null) {
entriesMissedInCache.add(key);
}
// issue #146
if (clearOnCommit) {
return null;
} else {
return object;
}
}
@Override
public void putObject(Object key, Object object) {
//先放入缓存缓冲区
entriesToAddOnCommit.put(key, object);
}
@Override
public Object removeObject(Object key) {
return null;
}
@Override
public void clear() {
clearOnCommit = true;
entriesToAddOnCommit.clear();
}
public void commit() {
if (clearOnCommit) {
delegate.clear();
}
//commit时刷新缓冲区数据往二级缓存放
flushPendingEntries();
reset();
}
public void rollback() {
//回滚时清空缓冲区数据
unlockMissedEntries();
reset();
}
private void reset() {
clearOnCommit = false;
entriesToAddOnCommit.clear();
entriesMissedInCache.clear();
}
//刷新缓冲区数据往二级缓存放,代码很清楚
private void flushPendingEntries() {
for (Map.Entry<Object, Object> entry : entriesToAddOnCommit.entrySet()) {
delegate.putObject(entry.getKey(), entry.getValue());
}
for (Object entry : entriesMissedInCache) {
if (!entriesToAddOnCommit.containsKey(entry)) {
delegate.putObject(entry, null);
}
}
}
...
6.分析完二级缓存,转回正文,我们继续跟踪下真正的query查询。
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
//是否需要清空一级缓存
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
//resultHandler为Null的时候,从一级缓存localCache里拿数据
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
//针对存储过程做进一步处理
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
//一级缓存没命中,从DB里拿
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
//STATEMENT类型不缓存,需要清空缓存
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
//占位开始执行
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//DB查询
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
//执行结束,清空占位
localCache.removeObject(key);
}
//更新一级缓存
localCache.putObject(key, list);
//存储过程类型,不作解释
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
doQuery方法是用的模板方法,我们用默认的简单的SimpleExecutor看下具体的实现。
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
//拿出configuration对象
Configuration configuration = ms.getConfiguration();
//生成StatementHandler
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//生成Statement
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
StatementHandler是走的代理模式的RoutingStatementHandler类,根据不同的StatementType生成不同的StatementHandler
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
//根据不同的type生成不同的StatementHandler
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
//又见到老朋友插件的过滤器链
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
public class RoutingStatementHandler implements StatementHandler {
private final StatementHandler delegate;
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
//工厂模式生成不同的SimpleStatementHandler
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
//从boundSql取出sql
String sql = boundSql.getSql();
//执行sql
statement.execute(sql);
//进行resultSet转换
return resultSetHandler.handleResultSets(statement);
}
最新文章
- [.NET] 打造一个很简单的文档转换器 - 使用组件 Spire.Office
- Windows平台分布式架构实践 - 负载均衡 上
- 6. Samba服务和防火墙配置笔记
- python subprocess 自动运行实验室程序
- JAVA学习博客---2015-6
- Appium学习实践(三)测试用例脚本以及测试报告输出
- C和指针笔记 3.8 static关键字
- spring 标注
- Java基础-新建项目、包和类
- Java的redis 操作类-优化通用版本
- js函数绑定同时,如何保留代码执行环境?
- app.config 配置多项 配置集合 自定义配置
- 【转】java jvm 线程 与操作系统线程
- 装修工人如何在网上"找活"
- FTP方式部署Azure Web App
- 在LINUX(Ubuntu 18.04.x、CentOS)下配置MySQL8.0.x
- maven向本地仓库导入jar包
- Centos7之系统优化
- Codeforces 1105C Ayoub and Lost Array (计数DP)
- [ERR] Node is not empty. Either the node already knows other nodes (check with C