Redis 设计与实现 10:五大数据类型之有序集合
2024-09-02 21:12:56
有序集合 sorted set (下面我们叫zset 吧) 有两种编码方式:压缩列表 ziplist 和跳表 skiplist。
编码一:ziplist
zset 在 ziplist 中,成员(member)和分数(score)是挨在一起的,元素按照分数从小到大存储。
举个例子,我们用以下命令创建一个zset:
redis> ZADD key 26.1 z 1 a 2 b
(integer) 3
那么这个zset的结构大致如下:
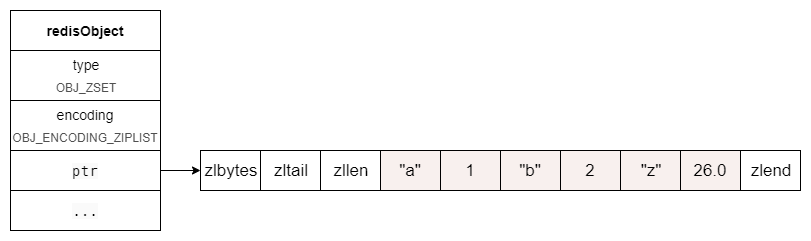
下面我们来分析一下 zscore 命令的源码,进一步了解 zset 是如何利用 ziplist 存储的
int zsetScore(robj *zobj, sds member, double *score) {
// ...
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
if (zzlFind(zobj->ptr, member, score) == NULL) return C_ERR;
}
// ...
return C_OK;
}
unsigned char *zzlFind(unsigned char *zl, sds ele, double *score) {
// eptr 是 member 的指针,sptr 是 score 的指针
unsigned char *eptr = ziplistIndex(zl,0), *sptr;
// 遍历 ziplist
while (eptr != NULL) {
// 因为 member 和 score 是挨着存储的,所以获取 member 的下一个节点就是 score 啦
sptr = ziplistNext(zl,eptr);
serverAssert(sptr != NULL);
// 对比当前的 member 和要查询的 member 是否相等
if (ziplistCompare(eptr,(unsigned char*)ele,sdslen(ele))) {
// 如果相等,则获取分数
if (score != NULL) *score = zzlGetScore(sptr);
return eptr;
}
// 不相等则继续往下遍历
eptr = ziplistNext(zl,sptr);
}
return NULL;
}
// 获取分数
double zzlGetScore(unsigned char *sptr) {
unsigned char *vstr;
unsigned int vlen;
long long vlong;
char buf[128];
double score;
serverAssert(sptr != NULL);
// ziplistGet 通过 sptr 指针获取值。根据节点的编码(前文有说到ziplist节点的编码) 对参数赋值
// 如果是字符串,则赋值到 vstr; 如果是整数,则赋值到 vlong。
serverAssert(ziplistGet(sptr,&vstr,&vlen,&vlong));
if (vstr) {
// 如果是字符串,那么存的就是浮点数
memcpy(buf,vstr,vlen);
buf[vlen] = '\0';
// 字符串转换成浮点数
score = strtod(buf,NULL);
} else {
// 整数类型就直接赋值
score = vlong;
}
return score;
}
编码二:skiplist
skiplist 的中文名叫 "跳表"或者"跳跃表"。
下面是跳表的结构图 (图片来自 《Redis 设计与实现》图片集 )
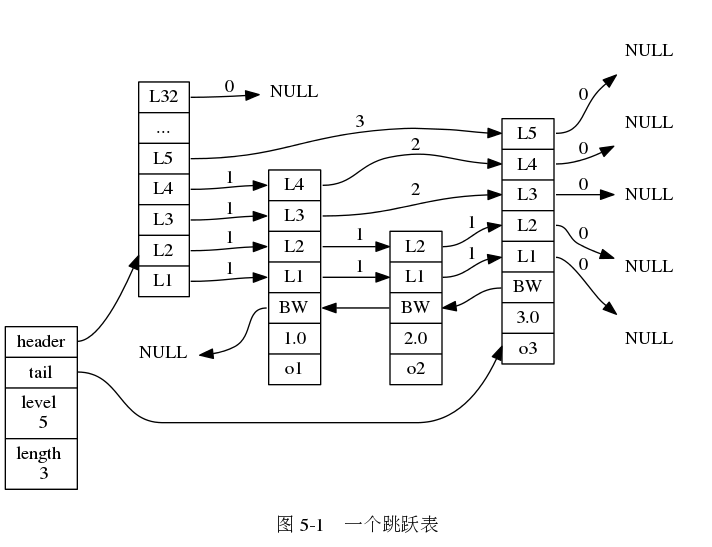
- 图中最左部分就是
zskiplist结构,其代码实现如下(server.h):
typedef struct zskiplist {
// 头指针和尾指针,指向头尾节点
struct zskiplistNode *header, *tail;
// 跳表的节点数(不包含头结点,空跳表也会包含头结点)
unsigned long length;
// 所有节点中,最大的层数
int level;
} zskiplist;
- 图中右边的四个节点,就是跳表节点
zskiplistNode,其代码实现如下(server.h):
typedef struct zskiplistNode {
// 成员
sds ele;
// 分数
double score;
// 后退指针,指向前一个节点
struct zskiplistNode *backward;
// 层,每个节点可能有很多层,每个层可能指向不同的节点
struct zskiplistLevel {
// 前进指针,指向下一个节点
struct zskiplistNode *forward;
// 跟下一个节点之间的跨度
unsigned long span;
} level[];
} zskiplistNode;
跳表最重要的一个地方就是层 level,为什么这么说呢?
假设zset 用链表有序存储,如果我们要查找数据,只能从头到尾遍历,时间复杂度是 \(O(n)\),效率很低。

有什么办法提高效率呢?我们可以在上面添加一层索引。
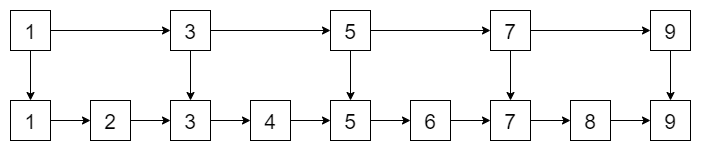
可以看出,我们遍历的性能变高了。例如我们想找到 6,先遍历第一层,5 到 7 之间,再往下探,就能找到 6 了!
有读者就发现了,如果数据量很大,那找起来也很慢。
是的,那么怎么解决呢?再往上加索引呗!
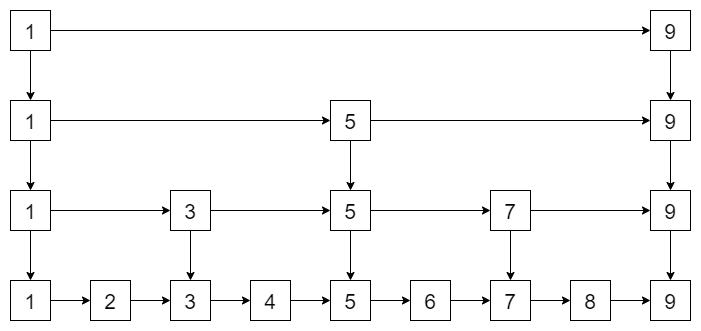
这不,链表就变成了跳表了!而上面说的层,就是这些索引啦!最终跳表的查找时间复杂度是 \(O(logn)\)
我们来看看 zrange 命令的核心实现,来感受一下跳表的遍历吧
zskiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank) {
zskiplistNode *x;
unsigned long traversed = 0;
int i;
// 层头结点开始
x = zsl->header;
// 层从高到低
for (i = zsl->level-1; i >= 0; i--) {
// 只要遍历的数没有达到 rank,就一直遍历
while (x->level[i].forward && (traversed + x->level[i].span) <= rank)
{
// 每次加上层的跨度
traversed += x->level[i].span;
// 往前走
x = x->level[i].forward;
}
// 如果这一层走完还没到 rank,那就往下层走,如果还是找不到就继续走,直到走到最底层
if (traversed == rank) {
return x;
}
}
return NULL;
}
最新文章
- android AES 加密
- 如何把Qlik Sense嵌入到Web应用中
- 写一个脚本,自动启动tomcat
- C#基础系列——小话泛型
- 我的android学习经历23
- php不解析的排查步骤
- Spring笔记——Spring+JDBC组合开发
- MYSQL基础01(新增,修改,删除)
- Android SharedPreferences登录记住密码
- 网络资源(1) - Hadoop视频
- Python的迭代器与生成器
- 201521123072《Java程序设计》第1周学习总结
- nginx location反向代理不对等时的处理
- Redis 安全配置
- php 代码中的箭头“ ->”是什么意思
- elasticsearch中文发行版 安装
- 德哥的PostgreSQL私房菜 - 史上最屌PG资料合集
- log4写完日志不会自动释放
- php使用inotify实现队列处理
- Ubuntu下录制屏幕并转换成gif【转】