producer内存管理分析
1 概述
kafka producer调用RecordAccumulator#append来将消息存到本地内存。消息以TopicPartition为key分组存放,每个TopicPartition对应一个Deque;RcordBatch的消息实际存储在MemoryRecords中;MemoryRecords有Compressor和ByteBuffer两个主要的属性,消息就是存储在ByteBuffer中,Compressor用来将消息写进到ByteBuffer中。消息在生产内存中的模型大致如下:
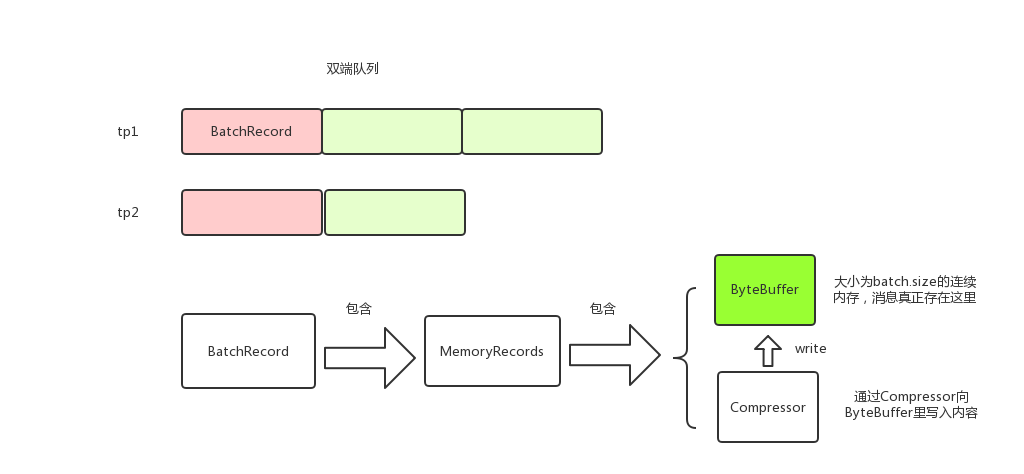
2 RecordAccumulator#append
producer调用send方法的时候,调用RecordAccumulator#append将消息存放到内存中。这里需要注意的是,append获取了两次锁,这样做是为了减少锁的范围。
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
appendsInProgress.incrementAndGet();
try {
Deque<RecordBatch> dq = getOrCreateDeque(tp); // 获取tp对应的Deque<RecordBatch>
synchronized (dq) { // 关键, 获取Deque<RecordBatch>的锁才操作
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
Deque<RecordBatch> dq = getOrCreateDeque(tp); // 获取tp对应的Deque<RecordBatch>
RecordBatch last = dq.peekLast(); // 往最后一个RecordBatch添加
if (last != null) { // 尝试添加,后面会详细讲
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds());
if (future != null) //添加成功就返回了
return new RecordAppendResult(future, dq.size() > 1 || last.records.isFull(), false);
}
}
// 没有添加成功,说明最后一个RecordBatch空间不足或者last == null
// 关键, 如果消息体大于batchsize,那么会创建消息体大小的RecordBatch,即RecordBatch不一定和batchsize相等
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
// 从BufferPool中分配内存,后面会详细讲
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) { // 重新获取锁,因为allocate的时候不需要锁dq,这里也是尽量减少锁粒度的一种思想
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordBatch last = dq.peekLast();
if (last != null) { // 可能在重新获取锁之前其他线程释放了内存,所以这里重新获取下
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds());
if (future != null) {
free.deallocate(buffer);
return new RecordAppendResult(future, dq.size() > 1 || last.records.isFull(), false);
}
}
// 还没有获取到RecordBatch则申请内存创建新的RecordBatch
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}
} finally {
appendsInProgress.decrementAndGet();
}
}
3 Compressor
上述代码调用RecordBatch#tryAppend尝试将消息放到RecordBatch,而RecordBatch#tryAppend又调用MemoryRecords#append。
public long append(long offset, long timestamp, byte[] key, byte[] value) {
if (!writable)
throw new IllegalStateException("Memory records is not writable");
int size = Record.recordSize(key, value);
compressor.putLong(offset);
compressor.putInt(size);
long crc = compressor.putRecord(timestamp, key, value);
compressor.recordWritten(size + Records.LOG_OVERHEAD);
return crc;
}
这里的关键是compressor,来分析下Compressor,以putInt为例,实际上是调用了DataOutputStream#writeInt方法
public void putInt(final int value) {
try {
appendStream.writeInt(value); // appendStream是DataOutputStream类型
} catch (IOException e) {
throw new KafkaException("I/O exception when writing to the append stream, closing", e);
}
}
看下Compressor是如何初始化的:
public Compressor(ByteBuffer buffer, CompressionType type) {
// ...
// create the stream
bufferStream = new ByteBufferOutputStream(buffer);
appendStream = wrapForOutput(bufferStream, type, COMPRESSION_DEFAULT_BUFFER_SIZE);
}
static public DataOutputStream wrapForOutput(ByteBufferOutputStream buffer, CompressionType type, int bufferSize) {
try {
switch (type) {
case NONE:
return new DataOutputStream(buffer); // 封装了ByteBufferOutputStream
case GZIP:
return new DataOutputStream(new GZIPOutputStream(buffer, bufferSize));
case SNAPPY:
try {
OutputStream stream = (OutputStream) snappyOutputStreamSupplier.get().newInstance(buffer, bufferSize);
return new DataOutputStream(stream);
} catch (Exception e) {
throw new KafkaException(e);
}
case LZ4:
try {
OutputStream stream = (OutputStream) lz4OutputStreamSupplier.get().newInstance(buffer);
return new DataOutputStream(stream);
} catch (Exception e) {
throw new KafkaException(e);
}
default:
throw new IllegalArgumentException("Unknown compression type: " + type);
}
} catch (IOException e) {
throw new KafkaException(e);
}
}
从上面代码可以看到,和ByteBuffer直接关联的是ByteBufferOutputStream;而DataOutputStream封装了ByteBufferOutputStream,负责处理压缩数据,直观上来看如下图:
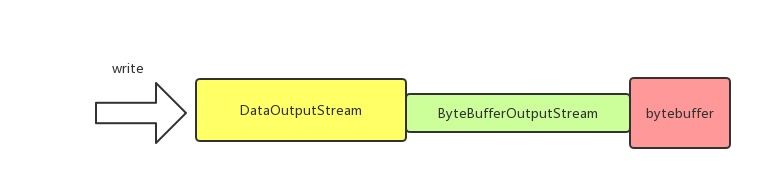
4 BufferPool
BufferPool用于管理producer缓存池,使用配置项buffer.memory来指定缓存池的大小,默认是32M。
4.1 allocate
BufferPool#allocate用于从缓存池中申请内存。BufferPool维护了一个ByteBuffer的双端队列free,表示空闲的ByteBuffer,只有大小为batch.size的内存申请才会从free中去拿去,也就是说free中维护的ByteBuffer都是batch.size大小。
BufferPool几个关键属性
private final long totalMemory;
private final int poolableSize; // 一块连续内存的大小,等于batch.size
private final ReentrantLock lock;
private final Deque<ByteBuffer> free; // 空闲的ByteBuffer列表,每个ByteBuffer都是batch.size大小,只有申请的内存等于batch.size大小才会从free中获取
private final Deque<Condition> waiters;
private long availableMemory; // 还有多少内存可以用,即buffer.memory-已用内存
// ...
}
public ByteBuffer allocate(int size, long maxTimeToBlockMs) throws InterruptedException {
if (size > this.totalMemory)
throw new IllegalArgumentException("Attempt to allocate " + size
+ " bytes, but there is a hard limit of "
+ this.totalMemory
+ " on memory allocations.");
this.lock.lock();
try {
if (size == poolableSize && !this.free.isEmpty()) // 关键,只有大小等于batch.size的时候才会从free中获取
return this.free.pollFirst();
int freeListSize = this.free.size() * this.poolableSize;
// 剩余总内存够用,但是不能从free中获取,则将free释放一些,然后申请对应大小的内存
if (this.availableMemory + freeListSize >= size) {
freeUp(size); // 释放
this.availableMemory -= size;
lock.unlock();
return ByteBuffer.allocate(size);
} else {
// 关键,剩余总内存不够了,则会阻塞,直到有足够的内存
int accumulated = 0;
ByteBuffer buffer = null;
Condition moreMemory = this.lock.newCondition();
long remainingTimeToBlockNs = TimeUnit.MILLISECONDS.toNanos(maxTimeToBlockMs);
this.waiters.addLast(moreMemory); // 添加到等待队列尾
while (accumulated < size) {
long startWaitNs = time.nanoseconds();
long timeNs;
boolean waitingTimeElapsed;
try {
waitingTimeElapsed = !moreMemory.await(remainingTimeToBlockNs, TimeUnit.NANOSECONDS); // 阻塞
} catch (InterruptedException e) {
this.waiters.remove(moreMemory);
throw e;
} finally {
long endWaitNs = time.nanoseconds();
timeNs = Math.max(0L, endWaitNs - startWaitNs);
this.waitTime.record(timeNs, time.milliseconds());
}
if (waitingTimeElapsed) {
this.waiters.remove(moreMemory);
throw new TimeoutException("Failed to allocate memory within the configured max blocking time " + maxTimeToBlockMs + " ms.");
}
remainingTimeToBlockNs -= timeNs;
// check if we can satisfy this request from the free list,
// otherwise allocate memory
if (accumulated == 0 && size == this.poolableSize && !this.free.isEmpty()) {
// just grab a buffer from the free list
buffer = this.free.pollFirst();
accumulated = size;
} else {
freeUp(size - accumulated);
int got = (int) Math.min(size - accumulated, this.availableMemory);
this.availableMemory -= got;
accumulated += got;
}
}
Condition removed = this.waiters.removeFirst(); // 从头部获取,后面详细讲
if (removed != moreMemory)
throw new IllegalStateException("Wrong condition: this shouldn't happen.");
// 如果分配后还有剩余空间,即唤醒后续的等待线程
if (this.availableMemory > 0 || !this.free.isEmpty()) {
if (!this.waiters.isEmpty())
this.waiters.peekFirst().signal(); // 唤醒头部
}
// unlock and return the buffer
lock.unlock();
if (buffer == null)
return ByteBuffer.allocate(size);
else
return buffer;
}
} finally {
if (lock.isHeldByCurrentThread())
lock.unlock();
}
}
对于allocate有几点需要注意
- 只有大小为batch.size的内存申请才会从free中获取,所以消息大小尽量不要大于batch.size,这样才能充分利用缓存池。为什么申请的内存会不等于batch.size呢,原因是在RecordAccumulator#append中有一句 int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value)), 即如果消息大小大于batch.size则会使用消息的大小申请内存。
- 下面代码可能有点疑惑, moreMemory是添加到waiters的尾部的,为什么获取的时候是从头部获取呢?这个原因是,线程唤醒只会唤醒waiters头部的线程,所以当线程被唤醒后,他肯定是已经在waiters头部了,也就是说排在他前面的线程都已经在他之前被唤醒并移除waiters了。
Condition removed = this.waiters.removeFirst(); // 从头部获取,后面详细讲
if (removed != moreMemory)
throw new IllegalStateException("Wrong condition: this shouldn't happen.");
- 申请的总内存查过buffer.memory的时候会阻塞或者抛出异常
4.2 deallocate
BufferPool#deallocate用于将内存释放并放回到缓存池。同allocate一样,只有大小等于batch.size的内存块才会放到free中。
public void deallocate(ByteBuffer buffer) {
deallocate(buffer, buffer.capacity());
}
public void deallocate(ByteBuffer buffer, int size) {
lock.lock();
try {
if (size == this.poolableSize && size == buffer.capacity()) {
buffer.clear();
this.free.add(buffer);// 只有大小等于batch.size的内存块才会放到free中
} else { // 否则的话只是availableMemory改变,无用的ByteBuffer会被GC清理掉
this.availableMemory += size;
}
Condition moreMem = this.waiters.peekFirst(); // 唤醒waiters的头结点
if (moreMem != null)
moreMem.signal();
} finally {
lock.unlock();
}
}
最新文章
- jquery ajax 请求参数详细说明 及 实例
- Redis ConnectionException
- <Oracle Database>数据库启动与关闭
- vuejs与服务器通信
- iOS开发小技巧--即时通讯项目:消息发送框(UITextView)高度的变化; 以及UITextView光标复位的小技巧
- 第11章 Windows线程池(2)_Win2008及以上的新线程池
- git 命令的学习
- 在xml中使用图片资源时,设置重复图片而不是拉伸平铺
- 【BZOJ】【4027】【HEOI2015】兔子与樱花
- 使用AE进行点的坐标投影变换
- linux 下C语言编程库文件处理与Makefile编写
- Mysql limit性能优化(小offset与大offset)
- Java二维数组的概念和使用方法
- CSS垂直居中技巧
- java面向对象编程(八)--抽象类、接口
- 网络编程懒人入门(八):手把手教你写基于TCP的Socket长连接
- Elastic 开发篇 javaAPI(4)
- 第36章 SDIO—SD卡读写测试
- android安卓系统上运行jar文件
- 【第十一章】 springboot + mongodb(简单查询)