PyTorch之初级使用
2024-09-18 20:56:11
- 使用流程
①. 数据准备; ②. 模型确立; ③. 损失函数确立; ④. 优化器确立; ⑤. 模型训练及保存 - 模块介绍
Part Ⅰ: 数据准备
torch.utils.data.Dataset
torch.utils.data.DataLoader
关于Dataset, 作为数据集, 需要实现基本的3个方法, 分别为: __init__、__len__、__getitem__. 示例如下,
1 class TrainingDataset(Dataset):
2
3 def __init__(self, X, Y_, transform=None, target_transform=None):
4 self.__X = X
5 self.__Y_ = Y_
6 self.__transform = transform
7 self.__target_transform = target_transform
8
9
10 def __len__(self):
11 return len(self.__X)
12
13
14 def __getitem__(self, idx):
15 x = self.__X[idx]
16 y_ = self.__Y_[idx]
17 if self.__transform:
18 x = self.__transform(x)
19 if self.__target_transform:
20 y_ = self.__target_transform(y_)
21 return x, y_关于DataLoader, 作为数据集封装, 将数据集Dataset封装为可迭代对象. 示例如下,
1 batch_size = 100
2 trainingLoader = DataLoader(trainingData, batch_size=batch_size, shuffle=True)Part Ⅱ: 模型确立
torch.nn
torch.nn.Module
网络模型由基类Module派生, 内部所有操作模块均由命名空间nn提供, 需要实现基本的2个方法, 分别为: __init__、forward. 其中, __init__方法定义操作, forward方法运用操作进行正向计算. 示例如下,1 class NeuralNetwork(nn.Module):
2
3 def __init__(self):
4 super(NeuralNetwork, self).__init__()
5 self.__linear_tanh_stack = nn.Sequential(
6 nn.Linear(3, 5),
7 nn.Tanh(),
8 nn.Linear(5, 3)
9 )
10
11
12 def forward(self, x):
13 y = self.__linear_tanh_stack(x)
14 return y
15
16
17 model = NeuralNetwork()Part Ⅲ: 损失函数确立
torch.nn
常见损失函数有: nn.MSELoss(回归任务)、nn.CrossEntropyLoss(多分类任务)等. 示例如下,1 loss_func = nn.MSELoss(reduction="sum")
Part Ⅳ: 优化器确立
torch.optim
常见的优化器有: optim.SGD、optim.Adam等. 示例如下,1 optimizer = optim.Adam(model.parameters(), lr=0.001)
Part Ⅴ: 模型训练及保存
有效整合数据、模型、损失函数及优化器. 注意, 模型参数之梯度默认累积, 每次参数优化需要显式清零. 示例如下,1 def train_loop(dataloader, model, loss_func, optimizer):
2 for batchIdx, (X, Y_) in enumerate(dataloader):
3 Y = model(X)
4 loss = loss_func(Y, Y_)
5
6 optimizer.zero_grad()
7 loss.backward()
8 optimizer.step()
9
10
11 epoch = 50000
12 for epochIdx in range(epoch):
13 train_loop(trainingLoader, model, loss_func, optimizer)
14
15
16 torch.save(model.state_dict(), "model_params.pth") - 代码实现
本文使用与Back Propagation - Python实现相同的网络架构及数据生成策略, 分别如下所示,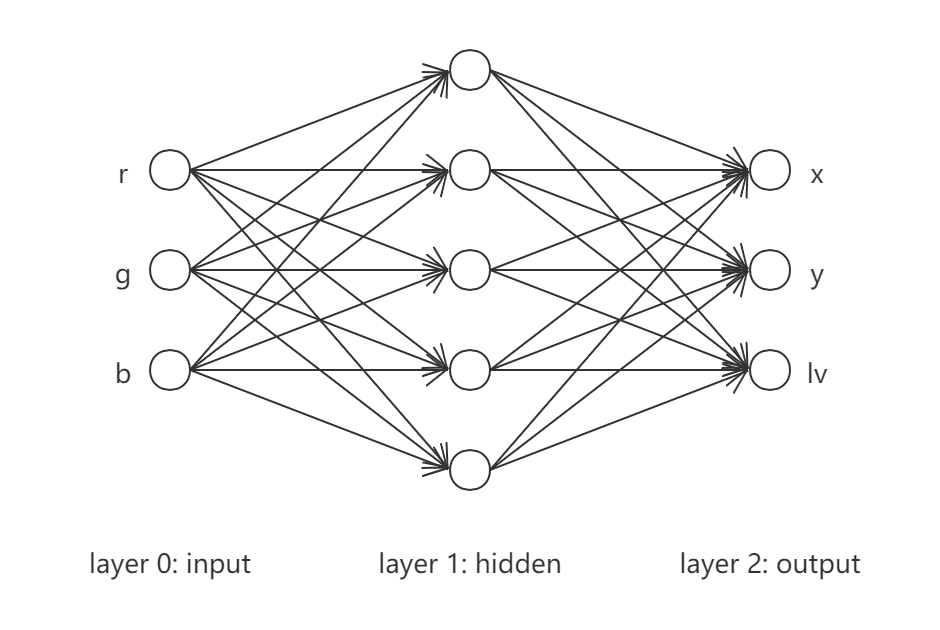
$$
\begin{equation*}
\left\{
\begin{split}
x &= r + 2g + 3b \\
y &= r^2 + 2g^2 + 3b^2 \\
lv &= -3r - 4g - 5b
\end{split}
\right.
\end{equation*}
$$
具体实现如下,

1 import numpy
2 import torch
3 from torch import nn
4 from torch import optim
5 from torch.utils.data import Dataset, DataLoader
6 from matplotlib import pyplot as plt
7
8
9 numpy.random.seed(1)
10 torch.manual_seed(3)
11
12
13 # 生成training数据
14 def getData(n=100):
15 rgbRange = (-1, 1)
16 r = numpy.random.uniform(*rgbRange, (n, 1))
17 g = numpy.random.uniform(*rgbRange, (n, 1))
18 b = numpy.random.uniform(*rgbRange, (n, 1))
19 x_ = r + 2 * g + 3 * b
20 y_ = r ** 2 + 2 * g ** 2 + 3 * b ** 2
21 lv_ = -3 * r - 4 * g - 5 * b
22 RGB = numpy.hstack((r, g, b))
23 XYLv_ = numpy.hstack((x_, y_, lv_))
24 return RGB, XYLv_
25
26
27 class TrainingDataset(Dataset):
28
29 def __init__(self, X, Y_, transform=None, target_transform=None):
30 self.__X = X
31 self.__Y_ = Y_
32 self.__transform = transform
33 self.__target_transform = target_transform
34
35
36 def __len__(self):
37 return len(self.__X)
38
39
40 def __getitem__(self, idx):
41 x = self.__X[idx]
42 y_ = self.__Y_[idx]
43 if self.__transform:
44 x = self.__transform(x)
45 if self.__target_transform:
46 y_ = self.__target_transform(y_)
47 return x, y_
48
49
50 RGB, XYLv_ = getData(1000)
51 trainingData = TrainingDataset(RGB, XYLv_, torch.Tensor, torch.Tensor)
52
53 batch_size = 100
54 trainingLoader = DataLoader(trainingData, batch_size=batch_size, shuffle=True)
55
56
57 class NeuralNetwork(nn.Module):
58
59 def __init__(self):
60 super(NeuralNetwork, self).__init__()
61 self.__linear_tanh_stack = nn.Sequential(
62 nn.Linear(3, 5),
63 nn.Tanh(),
64 nn.Linear(5, 3)
65 )
66
67
68 def forward(self, x):
69 y = self.__linear_tanh_stack(x)
70 return y
71
72
73 model = NeuralNetwork()
74 loss_func = nn.MSELoss(reduction="sum")
75 optimizer = optim.Adam(model.parameters(), lr=0.001)
76
77
78 def train_loop(dataloader, model, loss_func, optimizer):
79 JVal = 0
80 for batchIdx, (X, Y_) in enumerate(dataloader):
81 Y = model(X)
82 loss = loss_func(Y, Y_)
83
84 JVal += loss.item()
85
86 optimizer.zero_grad()
87 loss.backward()
88 optimizer.step()
89
90 JVal /= 2
91 return JVal
92
93
94 JPath = list()
95 epoch = 50000
96 for epochIdx in range(epoch):
97 JVal = train_loop(trainingLoader, model, loss_func, optimizer)
98 print("epoch: {:5d}, JVal = {:.5f}".format(epochIdx, JVal))
99 JPath.append(JVal)
100
101
102 torch.save(model.state_dict(), "model_params.pth")
103
104
105 fig = plt.figure(figsize=(6, 4))
106 ax1 = fig.add_subplot(1, 1, 1)
107
108 ax1.plot(numpy.arange(len(JPath)), JPath, "k.", markersize=1)
109 ax1.plot(0, JPath[0], "go", label="seed")
110 ax1.plot(len(JPath)-1, JPath[-1], "r*", label="solution")
111
112 ax1.legend()
113 ax1.set(xlabel="$epoch$", ylabel="$JVal$", title="solution-JVal = {:.5f}".format(JPath[-1]))
114
115 fig.tight_layout()
116 fig.savefig("plot_fig.png", dpi=100) - 结果展示
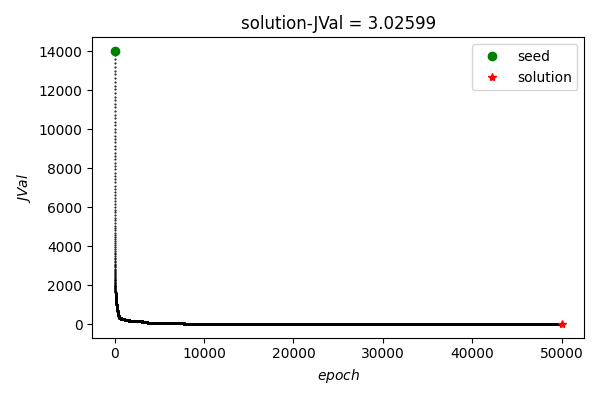 可以看到, 在training data上总体loss随epoch增加逐渐降低.
可以看到, 在training data上总体loss随epoch增加逐渐降低. 使用建议
①. 分batch处理训练数据, 可以提升训练初始阶段模型参数收敛速度;
②. 常规优化器推荐Adam, 具备自动步长调节的能力.- 参考文档
①. https://pytorch.org/tutorials/beginner/basics/intro.html
最新文章
- Font Squirrel
- Neutron分析(2)——neutron-server启动过程分析
- $(document).ready()使用讨论
- 一、记一次失败的 CAS 搭建 之 环境配置
- 23.allegro中钻孔[原创]
- 通过dataflow导入customer
- struts2+hibernate环境搭建
- HTML文档命名规则
- .NET CORE学习笔记系列(2)——依赖注入[6]: .NET Core DI框架[编程体验]
- leetcode:Single Number
- 50个最常用的Linux命令
- Ansible运维工具
- iTunes空间不足无法备份iphone的问题
- _itemmod_nopatch、_itemmod_nopatch_level、_itemmod_nopatch_spell、_itemmod_nopatch_src、_itemmod_nopatch_stat、_itemmod_nopatch_stat_prefix
- 《剑指offer》第四十九题(丑数)
- Tomcat修改版本号教程(CentOS)
- R子集subset
- sql server维护解决方案(备份、检查完整性、索引碎片整理)
- HDU1505 City Game 悬线法
- Oracle PUP(PRODUCT_USER_PROFILE)配置和使用