程序分析与优化 - 9 附录 XLA的缓冲区指派
本章是系列文章的案例学习,不属于正篇,主要介绍了TensorFlow引入的XLA的优化算法。XLA也有很多局限性,XLA更多的是进行合并,但有时候如果参数特别多的场景下,也需要进行分割。XLA没有数据切分的功能。当前最主流的编译器领域的编译优化功能还是mlir。
本文中的所有内容来自学习DCC888的学习笔记或者自己理解的整理,如需转载请注明出处。周荣华@燧原科技
9.1 什么是XLA
- XLA是Accelerated Linear Algebra的简称。
第一次看到Accelerated被简称为X的时候,有点奇怪,因为Accelerated里面可没有一个字母是X,但Accelerated的发音和X相同,这样简化之后可以避免一个简写中存在多个A的不协调,XLA读起来确实比ALA朗朗上口一点:)
- XLA - TensorFlow, compiled. Mar. 6th, 2017
- XLA是一种编译线性代数领域相关的编译器,主要用来加速TensorFlow的模型优化和目标代码生成
- 除了TensorFlow外,XLA也可以用在多种前端中,包括TensorFlow,Pytorch, JAX, Julia和Nx
- XLA的功能设计上其实与target arch无关的,所以也可以支持多种后端:CPU,GPU或者其他硬件
{kind=link}
在2017年XLA诞生的时候,那时给出的帧处理加速数据如下:
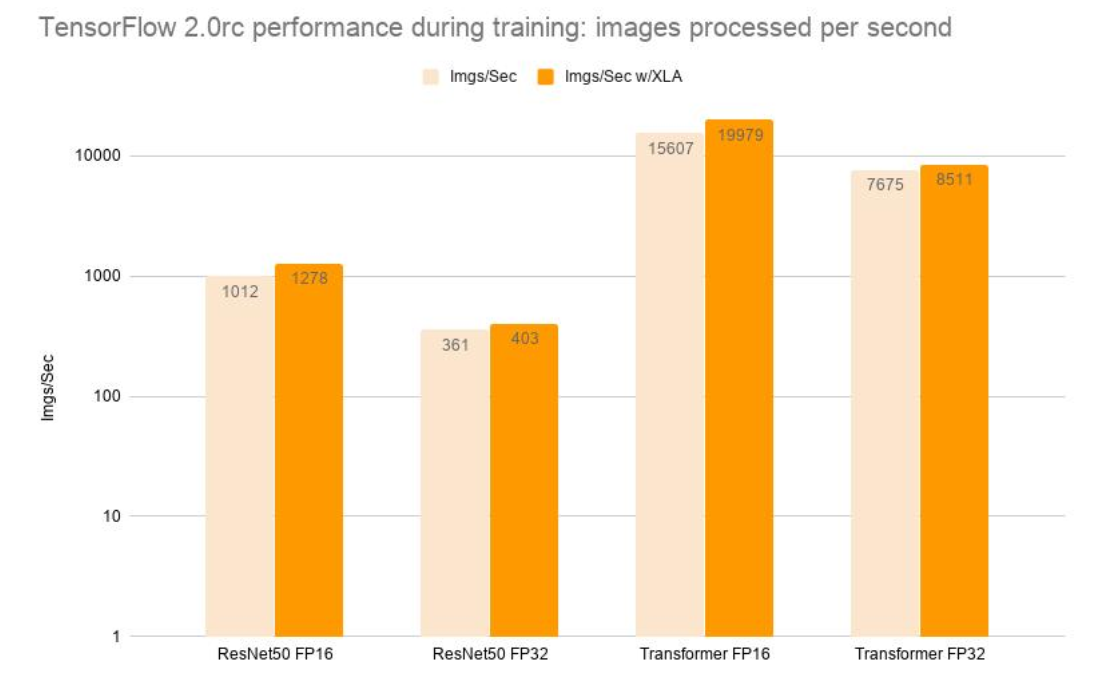
带来相应加速效果的主要因素是通过分析和调度内存使用,删除了一些中间表达的存储缓存,其中一个主要的方法就是缓冲区指派算法,也就是本文主要准备描述的。
XLA的设计理念是一种近似SSA的中间表达:
- 变量只能被初始化(除了初始化,不能额外修改)
- 更短的生命周期
- 清晰的Def-Use链
XLA: Optimizing Compiler for Machine Learning | TensorFlow中有个油管视频详细讲解了XLA的原理,通过这个也可以理解一下TensorFlow的原理:

tf.function → tf2xla桥 → 优化前的xla hlo → xla的一些列优化 → 优化后的hlo → 可执行binary → tf2xla桥 → tf runtime → target arch上执行
9.2 静态内存分配分析
9.2.1 为什么可以做分析
- 静态计算图本身的特性
- 张量在执行阶段只会使用固定的内存空间
- 静态计算图在执行前就可以静态推断
9.2.2 静态内存分析的优势
- 为算子提供通用的内存分配
- 重用前面算子的内存,减少重新分配和拷贝过程
- 减少额外的碎片和内存管理
9.2.3 静态内存分析的局限性
- 仅针对静态计算图有效
9.3 缓冲区管理的目标
- 尽可能重用内存
- 当内存不足以完成任务时报错
缓冲区定义:每个算子定义一个缓冲区
缓冲区申请、支配原则:
- 在生命周期上不相互干扰的缓冲区可以使用相互覆盖的内存
- 如果缓冲区和其他内存都冲突,需要重新申请内存并指派给它
- 所有申请的内存按组存放
9.4 缓冲区分析(有可以称为别名分析)
缓冲区分析的过程和指针分析的过程有很多类似的地方,所以很多地方又称为别名分析。
一个IR需要定义≥1个逻辑缓冲区
用{def, {}} 来定义一个缓冲区
缓冲区{b, {}} 和 {b, {1}}可以相互覆盖
来自不同IR的逻辑缓冲区可以复用同一块内存
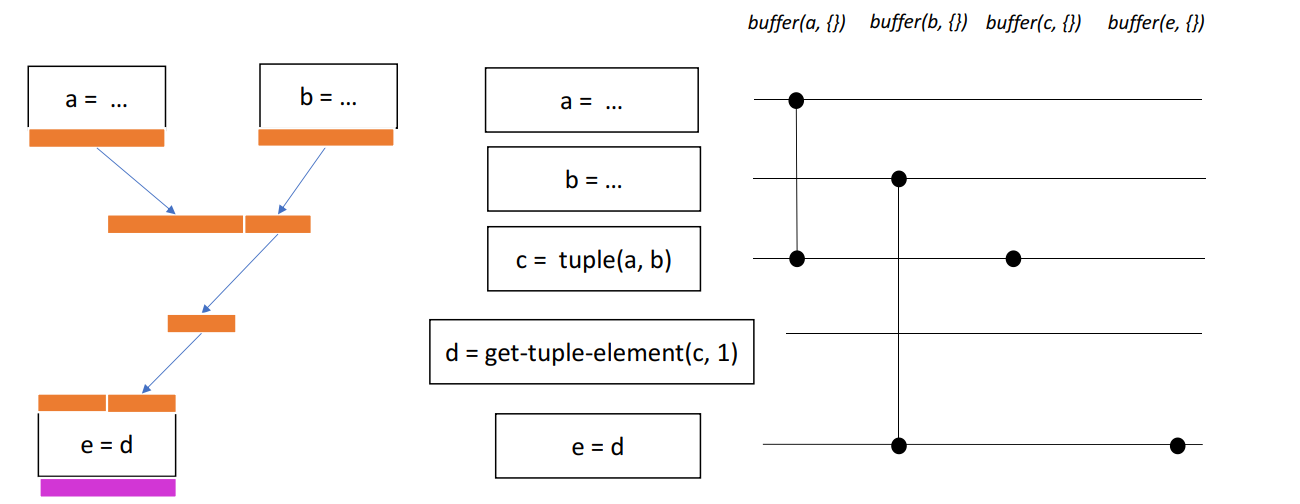
例如对下面的伪代码,可以知道d和b是别名关系,因为它们指向同一片内存:

9.4.1 定义所有指令的所有逻辑缓冲区
按拓扑顺序遍历(选择什么顺序?逆后根排序)计算图,为每个指令分配缓冲区,例如上面的伪代码,生成缓冲区如下:
1 Buffer(a, {}) : [ (a, {}) ]
2 Buffer(b, {}) : [ (b, {}) ]
3 Buffer(c, {}) : [ (c, {})]
9.4.2 HLO内部的别名分析后的结果
1 Buffer(a, {}) : [ (c, {0}), (a, {}) ]
2 Buffer(b, {}) : [ (c, {1}), (b, {}) , (d, {}) ]
3 Buffer(c, {}) : [ (c, {})]
9.4.3 跨HLO的别名分析
基于近似SSA的HLO语法定义,编译过程变得简单了很多(SSA化是很多编译中的主要工作)
9.4.4 基于上面伪代码的生命周期干扰分析
从下面生成的图来看,a和b互相干扰,不能公用缓冲区,e理论上是d的拷贝别名,所以和b也是别名关系。和寄存器分配不同的是,考虑到多线程执行场景,不同流中要用到的缓冲区不能分配到同一个组,所以a/b虽然和e在下面的计算图中没有干扰,但由于e是后面HLO的输入,所有e不能和当前计算图中的任意一个缓冲形成别名关系。
9.5 buffer指派的功能
9.5.1 将能够重用的buffer尽可能重用
没有生命期干扰的缓冲区都可以分配到同样的内存
9.5.2 缓冲区分配复合
将着色相同的缓冲区复合到一起申请(可能不同缓冲区占用某个实际缓冲区的不同部分,但大家相互之间的关系决定了它们可以相邻申请)
9.5.3 从全局分析去掉内存碎片
9.5.4 峰值内存压力预测
9.5.5 内存分配统计
最新文章
- 提升mysql性能的建议
- MicroERP开发技术分享:vsFlexGrid、scriptControl实现工资表自定义列与表间关系计算
- 一次熬夜解决的java乱码问题
- Good Sentences
- HW4.4
- infinitescroll 通过无限制分页(json方式完整代码)
- HDU 1576 A/B(数论)
- 利用fiddler将本地网页放到某个域下
- KoaHub.JS用于Node.js的可移植Unix shell命令程序代码
- Log Reservation
- HDU 6113 度度熊的01世界
- 微信小程序一:微信小程序UI组件、开发框架、实用库
- HAProxy+Nginx 负载均衡
- MyBatis(二):Select语句传递参数的集中方案
- 如何通过免费开源的ERP Odoo打造企业全员营销整体解决方案
- 响应式用法rem,需要加入这段JS
- Spark RDD 默认分区数量 - repartitions和coalesce异同
- Linux-centos安装node、nginx小记
- Android Logcat信息级别解读
- visual studio code 写c++代码
热门文章
- Em 和 Rem 的基本使用
- 【GPLT】 紧急救援(c++)
- 【基础】字符编码-ASCII、Unicode、utf-8
- GO 前后端分离开源后台管理系统 Gfast v2.0.4 版发布
- 【FAQ】接入HMS Core地图服务过程中常见问题总结
- Kafka核心组件详解
- 【Azure Developer】使用 adal4j(Azure Active Directory authentication library for Java)如何来获取Token呢
- Win10搭建Jenkins部署Java项目(本机和远程Win10部署)
- JS中的 && 、|| 、??、?. 运算符
- windows 10 21H1 顶部任务栏点击音量或其他图标不出弹框