论文笔记:DeepCF
Abstract
推荐系统可以看作用户和物品的匹配问题,不过user以及item两者的语义空间差异太大,直接匹配不太符合实际。主流的改进CF的方法有两类:基于表示学习的CF方法以及基于函数学习的表示方法。基于表示学习的CF模型将user和item转换到一个共通的语义空间来匹配。基于函数学习的CF尝试直接学习一个复杂的函数来对user和item进行匹配。
Introduction
DMF(Deep Matrix Factorization)用两个神经网络结构来替代线性的朴素MF中的embedding过程将user和item映射到一个共同的较低的语义空间。然而再评分预测问题上,MF方法依旧需要使用点积操作把latent factor线性的组合起来,对模型的表达是一种限制。NeuMF建立于(NCF模型)将user以及item的embedding作为MLP的输入,使用MLP来替代传统CF中的点积操作。MLP is very inefficient in catching low-rank relations,如果单纯的使用MLP来对评分进行预测,网络的学习会变得困难,这也是为什么NeuCF模型需要CF的结构来结合MLP学习。NeuCF的结构图如下所示:
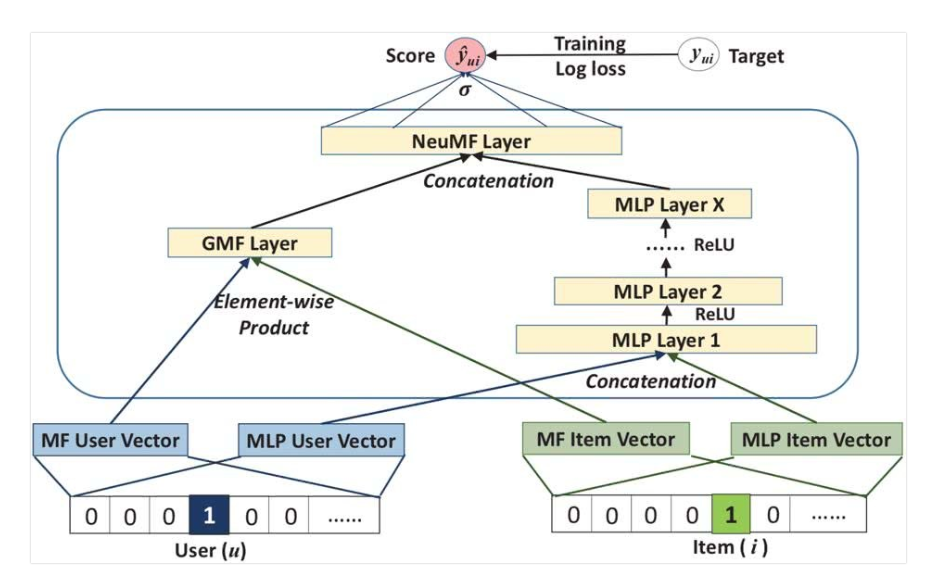
GMF部分是MF的扩展,用一层网络结构来学习user以及item的线性关系,MLP部分学习的是user以及item的非线性关系部分,两者结合能够有一个更好的效果。
DeeCF将基于表示的CF以及基于函数学习的CF结合起来。DeepCF主要的贡献如下:
(1)提出了一个结合表示学习和函数学习的DeepCF框架
(2)在DeepCF的框架下提出了基于朴素MLP的CFNet
(3)通过在实际生活中的大量实验验证了CFNet的有效性
Related Work
(1)隐式反馈数据集上的CF模型。基本假设,用户对其产生过行为我物品偏好值大于没有产生过行为的物品。
(2)基于表示学习的CF模型。这些模型的主要想法仍然是将用户和项目映射到一个可以直接比较的公共表示空间。基于表示的学习可以融合不同的数据源(比如一些辅助的文本信息,视频数据),但是基于表示的学习避免不了在评分预测问题上的点积操作。
(3)基于匹配函数的CF模型。NeuCF是一个代表,NeuCF使用MF来弥补MLP表示低纬联系的能力(简单理解为线性的表示)。基于匹配函数的CF模型需要关注的是the ability to learn low-rank relations
Preliminaries
(1)问题描述:我们用$Y\in \Re^{m{\times}n}$表示user-item的交互矩阵,当$y_{ui}=1$的时候表示用户$u$对物品$i$有过行为;当$y_{ui}=0$的时候表示用户$u$对物品$i$没有有过行为。隐式反馈主要的问题在于当$y_{ui}=1$我们不知道用户对该物品有多喜欢,当$y_{ui}=0$我们也不确定用户喜欢该物品且$y_{ui}=0$的情况巨多。论文采用负采样技术从未观测数据($y_{ui}=0$)中获取负样本。对于显性反馈上的推荐我们可以转换为计算交互矩阵的缺失值问题可以转换为评分预测问题。隐性数据的离散化以及二值性使得其不能使用直接效仿显性反馈上的推荐问题解决方法。为了解决这个问题,文章假设$y_{ui}$服从伯努利分布:
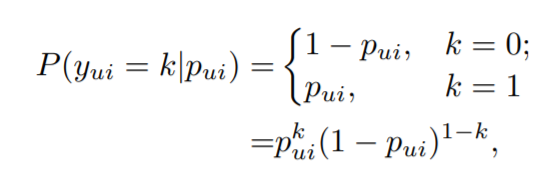
$p_{ui}$表示$y_{ui}$等于1的概率。这样处理交互矩阵Y,我们边可以将隐性数据的推荐问题转化为概率预测问题。
(2)模型的学习:根据(1)中的问题假设,用$\hat{y}_{ui}$来替换$p_{ui}$,则Y对应的似然函数如下:
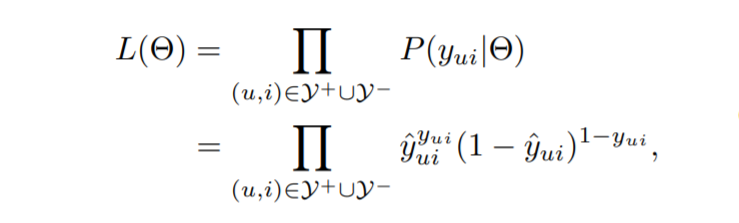
其中$y^+$对应有观测的数据,$y^-$对应未观测数据。MLE处理之后得到的损失函数如下所示:
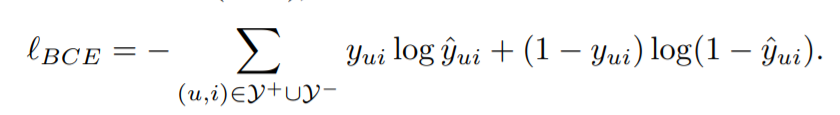
The Proposed Framework
基于表示学习的CF以及匹配函数学习的方法概念图如下所示:
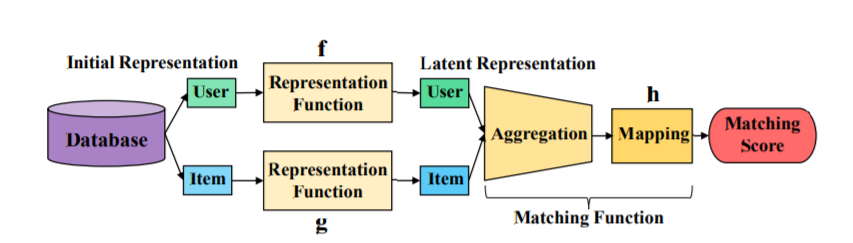
表示学习部分:DeepCF使用MLP作为表示函数,流程如下:
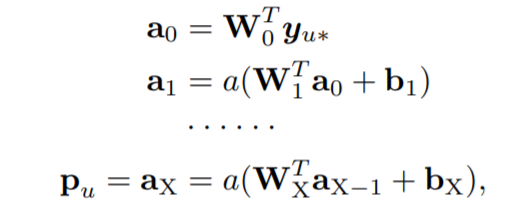
$W_x,b_x,a_x$对应的是矩阵权重,偏置向量以及第x层网络的激活值(激活函数为ReLU)。上述部分成为CFNet-rl
匹配函数学习:基于匹配函数学习的CF模型希望item以及user的特征向量是低维的特征向量,高维度的向量对于不易于匹配函数的学习,这也是这类方法采用linear embedding layer获取latent representations的主要原因。文章使用MLP来学习特征匹配函数。流程如下所示:
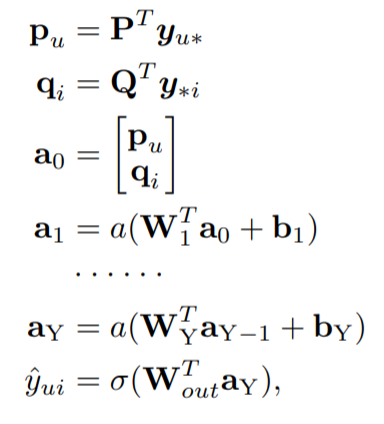
这里$P,Q$是linear embedding layers的参数矩阵。上述部分成为CFNet-ml
Fusion and Learning
DeepCF主要结构如下所示:
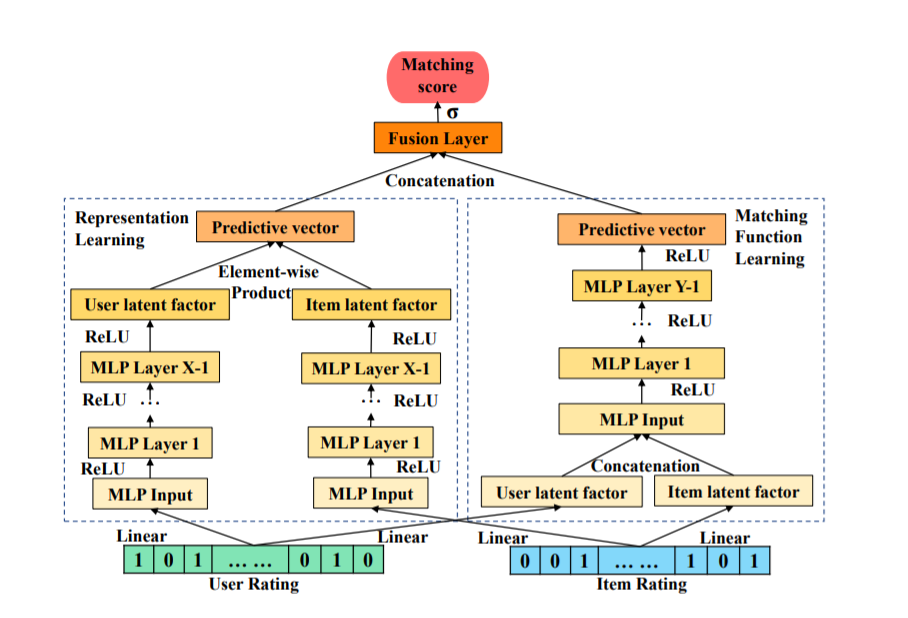
后记:补充一下两种评估方法:NDCG,Hit Ratio(HR)
Hit Ratio(HR)
在top-K推荐中,HR是一种常用的衡量召回率的指标,其计算公式如下:
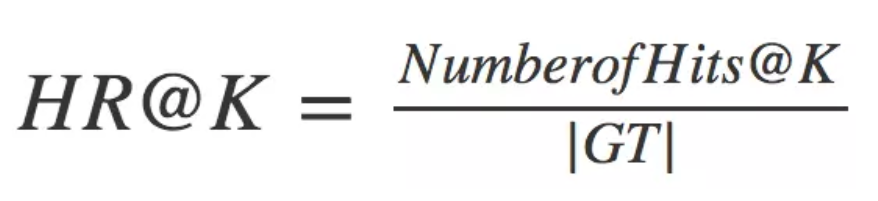
Normalized Discounted Cummulative Gain(NDCG)



NDCG解释来源于:http://sofasofa.io/forum_main_post.php?postid=1002561
最新文章
- CentOS如何查看硬盘品牌型号等具体信息
- Home 安转beta版软件
- WinCE小结
- ABAP DEMO
- 一步步写STM32 OS【二】环境搭建
- JAVA FILE or I/O学习 - File学习
- <一年成为Emacs高手>更新到20130706版
- 菜鸟进阶Android Touch事件传递(四)
- servlet请求转发与重定向的差别------用生活实例来形象说明两者的差别
- hbase 第一篇
- [CSS3] 学习笔记-CSS入门基本知识
- spring项目中service方法开启线程处理业务的事务问题
- Python——LOL官方商城皮肤信息爬取(一次练手)
- 在DataFrame数据表里面提取需要的行
- Java多线程面试题整理
- copy之深浅拷贝
- 设置IDEA中的web
- CASUAL_NCT
- 通过HttpClient调用服务
- android 设置为系统应用