Spark ML协同过滤推荐算法
一.简介
协同过滤算法【Collaborative Filtering Recommendation】算法是最经典、最常用的推荐算法。该算法通过分析用户兴趣,在用户群中找到指定用户的相似用户,综合这些相似用户对某一信息的评价,形成系统关于该指定用户对此信息的喜好程度预测。
二.步骤
1.收集用户偏好。
2.找到相似的用户或物品。
3.计算推荐。
三.用户评分
从用户的行为和偏好中发现规律,并基于此进行推荐,所以收集用户的偏好信息成为系统推荐效果最基础的决定因素。
数据预处理:
1.减噪
因为用户数据在使用过程中可能存在大量噪声和误操作,所以需要过滤掉这些噪声。
2.归一化
不同行为数据的差别比较大,通过归一化,数据归于大致均衡,计算时才能减少异常数据产生的影响。
组合不同用户行为方式:
1.将不同的行为分组
2.对不同行为进行加权
四.相似度计算
对用户的行为分析得到用户的偏好后,可以根据用户的偏好计算相似用户和物品,然后可以基于相似用户或相似物品进行推荐。我们可以将用户对所有物品的偏好作为一个矩阵来计算用户之间的相似度,或者将所有用户对物品的偏好作为一个矩阵来计算物品之间的相似度。
1.同现相似度
指在喜爱物品A的前提下,喜爱物品B的概率。当物品B喜爱率较高时可以使用(A交B)/sqrt(A或B)。
2.欧式距离
1/(1+d(x,y))
备注:d(x,y) 欧式距离
3.皮尔逊相关系数
皮尔逊相关系数一般用于计算两个定距变量间联系的紧密程度,它的取值为【-1~1】之间。
4.Cosine相似度【余弦相似度】
Cosine相似度广泛应用于计算文档数据的相似度。
5.Tanimoto系数
Tanimoto系数也被称为Jaccard系数,是Cosine相似度的扩展,也多用于计算文档数据的相似度。
五.代码实现
package big.data.analyse.ml import _root_.breeze.numerics.sqrt
import org.apache.log4j.{Level, Logger}
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.rdd.RDD /**
* 用户评分
* @param userid 用户
* @param itemid 物品
* @param pref 评分
*/
case class ItemPref(val userid : String,val itemid : String, val pref : Double) extends Serializable /**
* 相似度
* @param itemid_1 物品
* @param itemid_2 物品
* @param similar 相似度
*/
case class ItemSimilar(val itemid_1 : String, val itemid_2 : String, val similar : Double) extends Serializable /**
* 给用户推荐物品
* @param userid 用户
* @param itemid 物品
* @param pref 推荐系数
*/
case class UserRecommend(val userid : String, val itemid : String, val pref : Double) extends Serializable /**
* 相似度计算
*/
class ItemSimilarity extends Serializable{
def Similarity(user : RDD[ItemPref], stype : String) : RDD[ItemSimilar] = {
val similar = stype match{
case "cooccurrence" => ItemSimilarity.CooccurenceSimilarity(user) // 同现相似度
//case "cosine" => // 余弦相似度
//case "euclidean" => // 欧式距离相似度
case _ => ItemSimilarity.CooccurenceSimilarity(user)
}
similar
}
} object ItemSimilarity{
def CooccurenceSimilarity(user : RDD[ItemPref]) : (RDD[ItemSimilar]) = {
val user_1 = user.map(r => (r.userid, r.itemid, r.pref)).map(r => (r._1, r._2))
/**
* 内连接,默认根据第一个相同字段为连接条件,物品与物品的组合
*/
val user_2 = user_1.join(user_1) /**
* 统计
*/
val user_3 = user_2.map(r => (r._2, 1)).reduceByKey(_+_) /**
* 对角矩阵
*/
val user_4 = user_3.filter(r => r._1._1 == r._1._2) /**
* 非对角矩阵
*/
val user_5 = user_3.filter(r => r._1._1 != r._1._2) /**
* 计算相似度
*/
val user_6 = user_5.map(r => (r._1._1, (r._1._1,r._1._2,r._2)))
.join(user_4.map(r => (r._1._1, r._2))) val user_7 = user_6.map(r => (r._2._1._2, (r._2._1._1, r._2._1._2, r._2._1._3, r._2._2)))
.join(user_4.map(r => (r._1._1, r._2))) val user_8 = user_7.map(r => (r._2._1._1, r._2._1._2, r._2._1._3, r._2._1._4, r._2._2))
.map(r => (r._1, r._2, (r._3 / sqrt(r._4 * r._5)))) user_8.map(r => ItemSimilar(r._1, r._2, r._3))
}
} class RecommendItem{
def Recommend(items : RDD[ItemSimilar], users : RDD[ItemPref], number : Int) : RDD[UserRecommend] = {
val items_1 = items.map(r => (r.itemid_1, r.itemid_2, r.similar))
val users_1 = users.map(r => (r.userid, r.itemid, r.pref)) /**
* i行与j列join
*/
val items_2 = items_1.map(r => (r._1, (r._2, r._3))).join(users_1.map(r => (r._2, (r._1, r._3)))) /**
* i行与j列相乘
*/
val items_3 = items_2.map(r => ((r._2._2._1, r._2._1._1), r._2._2._2 * r._2._1._2)) /**
* 累加求和
*/
val items_4 = items_3.reduceByKey(_+_) /**
* 过滤已存在的物品
*/
val items_5 = items_4.leftOuterJoin(users_1.map(r => ((r._1, r._2), 1))).filter(r => r._2._2.isEmpty)
.map(r => (r._1._1, (r._1._2, r._2._1))) /**
* 分组
*/
val items_6 = items_5.groupByKey() val items_7 = items_6.map(r => {
val i_2 = r._2.toBuffer
val i_2_2 = i_2.sortBy(_._2)
if(i_2_2.length > number){
i_2_2.remove(0, (i_2_2.length - number))
}
(r._1, i_2_2.toIterable)
}) val items_8 = items_7.flatMap(r => {
val i_2 = r._2
for(v <- i_2) yield (r._1, v._1, v._2)
}) items_8.map(r => UserRecommend(r._1, r._2, r._3))
}
} /**
* Created by zhen on 2019/8/9.
*/
object ItemCF {
def main(args: Array[String]) {
val conf = new SparkConf()
conf.setAppName("ItemCF")
conf.setMaster("local[2]") val sc = new SparkContext(conf) /**
* 设置日志级别
*/
Logger.getRootLogger.setLevel(Level.WARN) val array = Array("1,1,0", "1,2,1", "1,4,1", "2,1,0", "2,3,1", "2,4,0", "3,1,0", "3,2,1", "4,1,0", "4,3,1")
val cf = sc.parallelize(array) val user_data = cf.map(_.split(",")).map(r => (ItemPref(r(0), r(1), r(2).toDouble))) /**
* 建立模型
*/
val mySimilarity = new ItemSimilarity()
val similarity = mySimilarity.Similarity(user_data, "cooccurrence") val recommend = new RecommendItem()
val recommend_rdd = recommend.Recommend(similarity, user_data, 30) /**
* 打印结果
*/
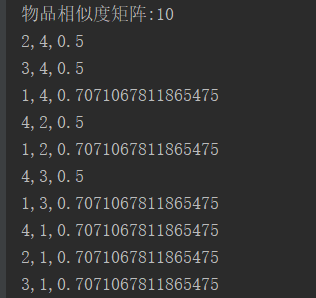
println("物品相似度矩阵:" + similarity.count())
similarity.collect().foreach(record => {
println(record.itemid_1 +","+ record.itemid_2 +","+ record.similar)
}) println("用户推荐列表:" + recommend_rdd.count())
recommend_rdd.collect().foreach(record => {
println(record.userid +","+ record.itemid +","+ record.pref)
})
}
}
六.结果

最新文章
- python通过protobuf实现rpc
- 【转】MipMap
- System.Web.HttpContext.Current.Session为NULL解决方法
- malloc error:初始值设定元素不是常量
- IIS7 rename application or site
- js判断是否安装pdf播放器
- HTML5自学笔记[ 19 ]canvas绘图实例之炫彩时钟
- Active Session History (ASH) Performed An Emergency Flush Messages In The Alert Log
- once
- DataBase First创建数据库
- 【HDU3371】Connect the Cities(MST基础题)
- 安卓开发之RecyclerView
- 《Intel汇编第5版》 汇编减法程序
- 开源Android-PullToRefresh下拉刷新源代码分析
- linux服务搭建----NFS服务搭建
- 服务器禁止ping
- centos7下kubernetes(12。kubernetes-service)
- SqlServer2012清除日志文件
- JS禁止右键查看源码,禁止复制,复制内容到剪切板
- form表单提交时action路劲问题
热门文章
- ESA2GJK1DH1K基础篇: 阿里云物联网平台: 云平台显示单片机采集的温湿度数据,控制设备继电器(基于GPRS模块,AT指令TCP_MQTT通信)
- [PHP] Elasticsearch 6.4.2 的安装和使用
- docker 创建私有镜像之 registry
- Spring Boot 知识笔记(热部署)
- Spring Boot进阶系列二
- 记遇到的Release和Debug下有些不同
- 分布式事务解决方案(一) 2阶段提交 & 3阶段提交 & TCC
- 2018-2019-2 网络对抗技术 20165318 Exp7 网络欺诈防范
- Kubernetes集群之清除集群
- Kafka Offset Monitor页面显示空白