Real-time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-identification
Real-time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-identification
2019-06-21 15:45:11
Paper: https://arxiv.org/abs/1809.04427
Code: https://github.com/longcw/MOTDT
1. Background and Motivation:
多目标跟踪的核心思想是数据连接(data association),但是受到不可靠检测结果的影响,MOT 的性能也受到了很大程度上的干扰。本文将 detection 和 tracking 的结果都用于数据的匹配,同时还将 person re-ID 任务中学习到的 feature,结合到 MOT。核心贡献主要为:
1). 通过将 detection 和 tracking 的结果组合为候选,以处理在线跟踪中不可靠检测的问题;
2). 采用了多级的数据连接策略,使用了空间信息和 person re-ID 的 feature;
3). 取得了不错的效果。
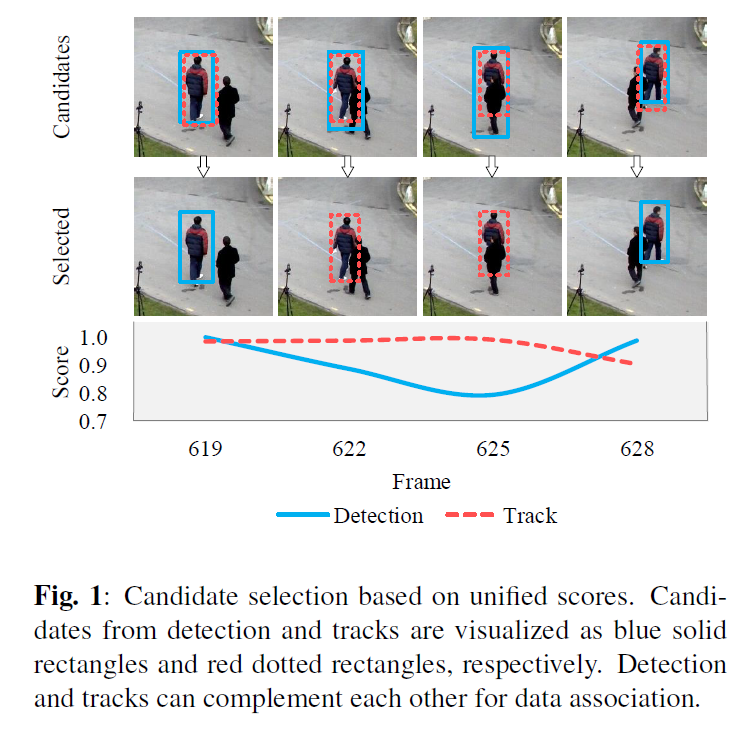
2. The Proposed Tracker:
2.1 Overview
作者用一个联合的 scoring function 首先衡量所有候选的得分;该 scoring function 是由:判别性训练的物体分类器和 tracklet confidence 构成的。
然后用 NMS(Non-Maximal supression)在预测的得分上进行处理。
在得到候选后,作者联合利用 appearance representation 和 spatial information 来进行数据连接。
2.2 Real-Time Object Classification:
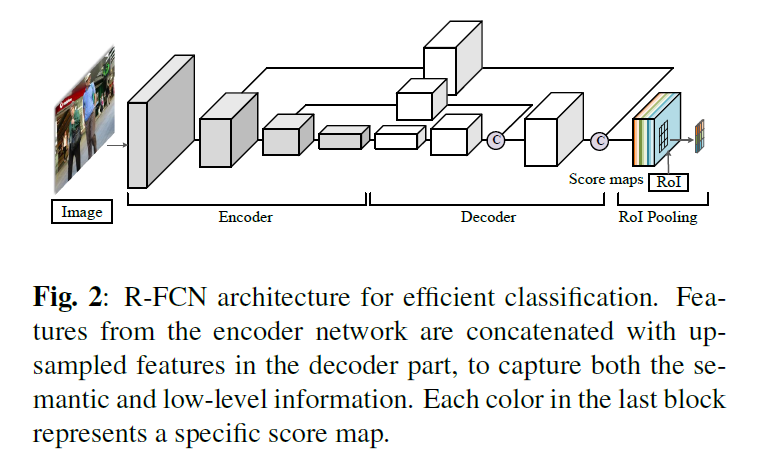
本文采用的 classifier 如图 2 所示。给定视频帧,整张图的 score map 可以通过 encoder-decoder 的全卷积网络得到。Encoder 部分是一个轻量级的卷积模块,Decoder 是用于增大输出 score map 的分辨率进行后续的分类。每一个需要分类的候选,被定义为:a region of interest (RoI) x = (x0, y0, w, h)。为了显示的编码空间信息,作者采用了 position-sensitive RoI pooling layer 并且从 $k^2$ position-sensitive score maps z 上预测分类概率。特别的,我们将 RoI 划分为 $k * k$ 个单元。RoI x 的最终得分为:
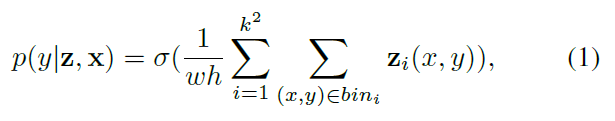
其中,$z_i$ 代表第 i 个 score map。
2.3 Tracklet Confidence and Scoring Function :
给定新的视频帧,我们用 Kalman filter 来预测目标的新位置。此外,Tracklet confidence 被设计用于衡量带有时序信息的 filter 的精度。
从连续的视频中,通过 candidates 的链接可以产生 tracklet。我们可以将 track 划分为多个 tracklets,因为单个的 track 是可以被打断的和被检索到的。
当 track 从丢失状态被检索回来时,Kalman filter 将会被重新初始化。所以,仅最后 tracklet 的信息被用于衡量 track 的置信度。此处,我们定义 $L_{det}$ 为 tracklet 相关的 detection 结果的个数,$L_{trk}$ 在上一次检测被连接后的 track 预测的个数。所以,tracklet confidence 被定义为:
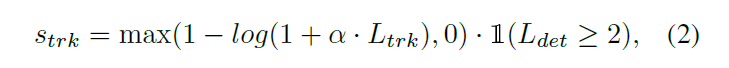
其中,空心字符 1 代表 1/0 的取值,当输入为真时,取值为 1,否则为 0。
候选 x 的联合 scoring function 为:
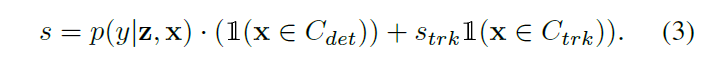
此处,$C_{det}$ 代表来自 detection 的候选,$C_{trk}$ 代表来自 tracks 的候选。
2.4 Appearance Representation with ReID Features :
采用现有的 person re-ID 模型,进行特征的学习,详情见 paper:
Liming Zhao, Xi Li, Jingdong Wang, and Yueting Zhuang, “Deeply-learned part-aligned representations for person reidentification,” in ICCV, 2017.
2.5 Hierarchical Data Association :
tracks 被用于处理丢失的检测结果(在拥挤的场景下)。由于受到 intra-category occlusion 的影响,这些预测会受到其他物体的干扰。为了避免将其他不需要的物体和背景结合到外观表达中,作者用不同的 feature 将 tracks 和 不同的 candidates 进行连接。
特别的,作者首先在 detection 结果上进行 data association(设置阈值)。
然后,作者基于 candidates 和 tracks 之间的 IoU 对剩余的 candidates 和 unassociated tracks 进行连接。
算法的整体流程如下所示:

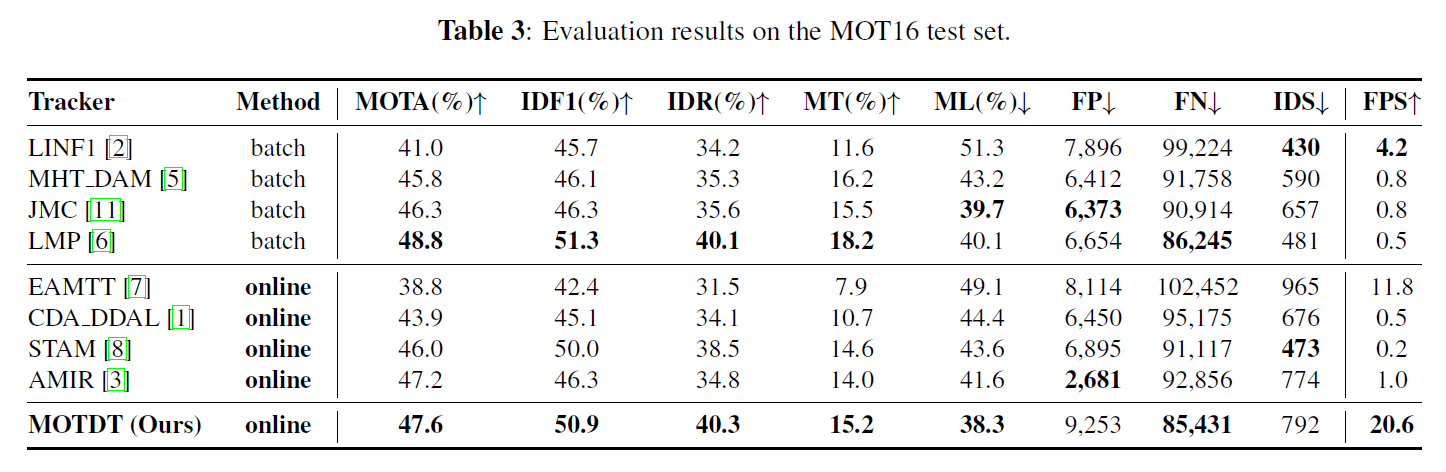
3. Experiments:

==
最新文章
- 一看就懂的ReactJs入门教程-精华版
- 【安全测试】sqlmap安装方法
- Unity3d之个性化皮肤
- poj1087 A Plug for UNIX(网络流最大流)
- web iphone css 兼容性
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
- delphi 调用百度地图WEBSERVICE转换GPS坐标 转
- 利用KeyVault来加强存储Azure Storage访问密钥管理
- AndroidManifest.xml 配置权限大全
- Redis 脚本
- Sugarcrm Email Integration
- android常见错误--INSTALL_FAILED_DEXOPT
- Html Meta 标签详解
- 达到J2EE在后台action控制接待javascript弹出的对话框
- Linux入门介绍
- Sublime text3 设置的中文翻译
- 前端工程之node基础
- PHP执行linux命令mkdir权限问题
- bzoj 4011
- vc6.0使用
热门文章
- Unity shader error: “Too many texture interpolators would be used for ForwardBase pass”
- 浅谈HDFS(三)之DataNote
- CentOS8-在hyper-V安装选项
- linux服务器中安装VSCode
- GCC编译流程浅析
- Eureka 中服务下线的几种方式
- java调用c++库
- 树莓派上 Docker 的安装和使用
- POJ - 3728:The merchant (Tarjan 带权并查集)
- dimensionality reduction动机---data compression(使算法提速)