miaosha
1:跨域请求配置
后端Controller 添加注解 @CrossOrigin(origins = {"*"},allowCredentials = "true")
前端ajax 请求添加xhrFields: { withCredentials: true }
2:跨域解决方案
1:jsonp
2:cors
3:node 转发
4:nginx 反向代理
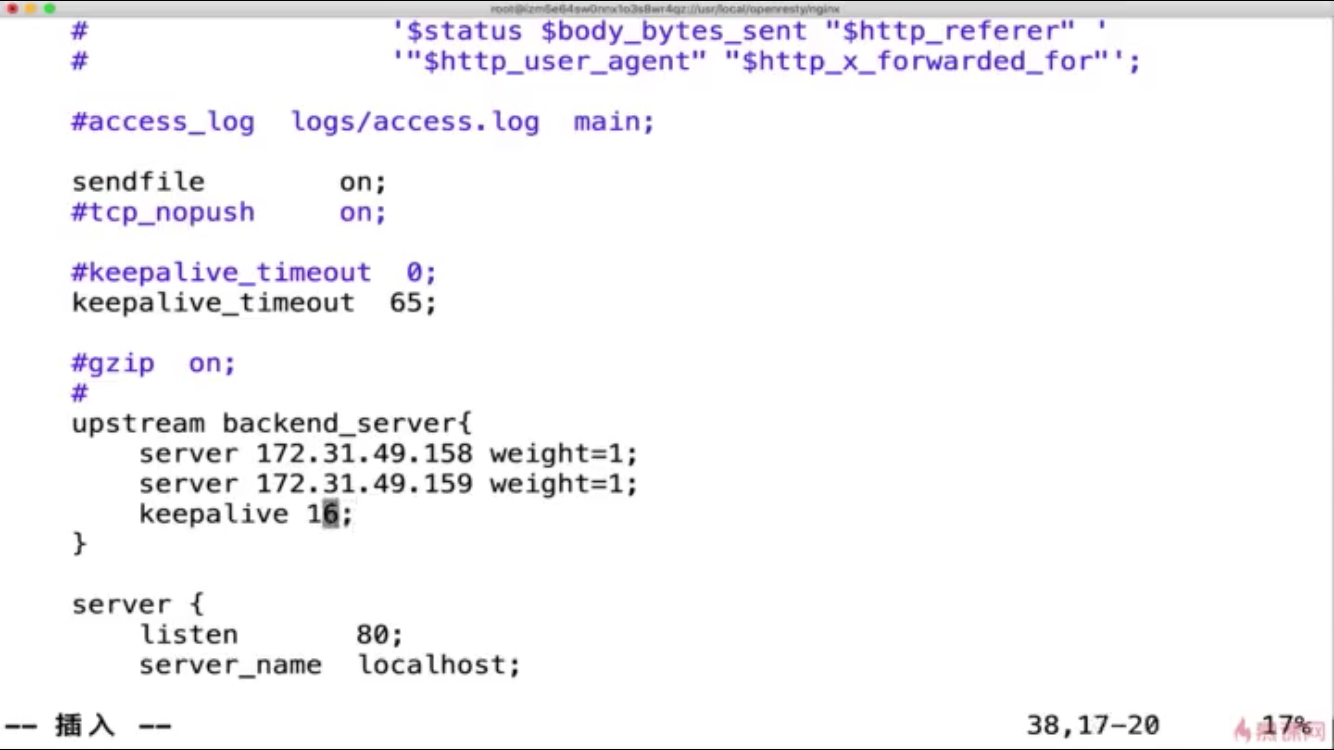
3:命令
telnet 172.36.189.36 9850 判断是否可用
ps -ef | grep mysql 查看服务
netstat -anp |grep 3306 查看端口
pstree -p 5240 查看当前进程下的线程
pstree -p 5240 | wc -l 查看当前进程下的线程数量
top -H 显示系统上正在运行的进程 load average 三个值
表示最近三个时间段的cpu运行情况 cpu
us 表示用户区域占用cpu状态 sy 表示内核区域占用cpu状态

4:启动脚本
deploy.sh 内容
nohup java -Xms400m -Xmx400m -XX:NewSize=200m -XXMaxNewSize=200m -jar miaosha.jar -spring.config.addition-location=
./deploy.sh & 启动即可
tail 可以查看启动日志内容
5:jmeter性能压测
1:线程组
2:http请求
3:查看结果树
4:聚合报告
6:默认内嵌的tomcat配置
server.tomcat.accept-count 等待队列长度 默认100
server.tomcat.max-connections 最大可被连接数 默认10000
server.tomcat.max-threads 最大工作线程数 默认200
server.tomcat.min-spare-threads 最小工作线程数 默认10
默认配置下 连接数超过10000出现拒绝连接情况
默认配置下 触发的请求超过200+100拒绝请求处理
建议配置
4核8g的服务器当线程数在800-1000以上的时候会花大量时间在cpu调度上
server.tomcat.accept-count=1000
server.tomcat.max-threads=800
server.tomcat.min-spare-threads=100
//当Spring容器内没有TomcatEmbeddedServletContainerFactory这个bean时,会吧此bean加载进spring容器中
@Component
public class WebServerConfiguration implements WebServerFactoryCustomizer<ConfigurableWebServerFactory> {
@Override
public void customize(ConfigurableWebServerFactory configurableWebServerFactory) {
//使用对应工厂类提供给我们的接口定制化我们的tomcat connector
((TomcatServletWebServerFactory)configurableWebServerFactory).addConnectorCustomizers(new TomcatConnectorCustomizer() {
@Override
public void customize(Connector connector) {
Http11NioProtocol protocol = (Http11NioProtocol) connector.getProtocolHandler(); //定制化keepalivetimeout,设置30秒内没有请求则服务端自动断开keepalive链接
protocol.setKeepAliveTimeout(30000);
//当客户端发送超过10000个请求则自动断开keepalive链接
protocol.setMaxKeepAliveRequests(10000);
}
});
}
}
7:mysql 权限
grant all privileges on *.* to joe@localhost identified by '1';
grant 权限1,权限2,…权限n on 数据库名称.表名称 to 用户名@用户地址 identified by ‘连接口令’;
flush privileges;
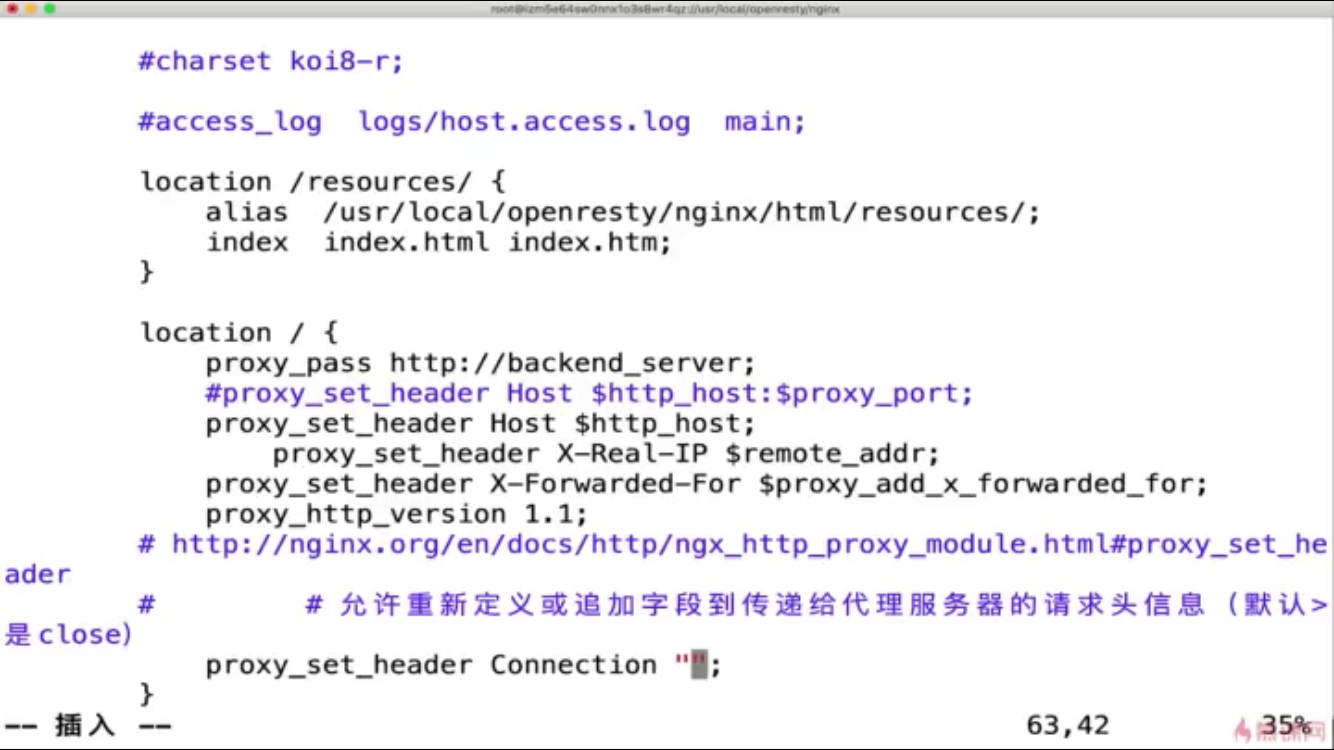
8:nginx 作为反向代理服务器 静态资源服务器
nginx 高效原因
epoll多路复用
master-worker 进程模型
协成机制
9:对于Redis中bind的正确的理解是:
bind:是绑定本机的IP地址,(准确的是:本机的网卡对应的IP地址,每一个网卡都有一个IP地址),而不是redis允许来自其他计算机的IP地址。
如果指定了bind,则说明只允许来自指定网卡的Redis请求。如果没有指定,就说明可以接受来自任意一个网卡的Redis请求。
举个例子:如果redis服务器(本机)上有两个网卡,每一个网卡对应一个IP地址,例如IP1和IP2。(注意这个IP1和IP2都是本机的IP地址)。
我们的配置文件:bind IP1。 只有我们通过IP1来访问redis服务器,才允许连接Redis服务器,如果我们通过IP2来访问Redis服务器,就会连不上Redis。
————————————————
bind 127.0.0.1的解释:(为什么只有本机可以连接,而其他不可以连接)
我们从ifconfig可以看出:lo网卡(对应127.0.0.1IP地址):是一个回环地址(Local Loopback),也就是只有本地才能访问到这个回环地址,而其他的计算机也只能访问他们自己的回环地址。
那么来自这个lo网卡的计算机只有本机,所以只有本机可以访问,而其他计算机不能访问。
————————————————
1.如果你的bind设置为:bind 127.0.0.1,这是非常安全的,因为只有本台主机可以连接到redis,就算不设置密码,也是安全的,除非有人登入到你的服务器上。
2.如果你的bind设置为:bind 0.0.0.0,表示所有主机都可以连接到redis。(前提:你的服务器必须开放redis的端口)。这时设置密码,就会多一层保护,只有知道密码的才可以访问。也就是任何知道密码的主机都可以访问到你的redis。
————————————————
10:tomcat访问日志开启

11:nginx 配置 反向代理 静态服务器 以及 nginx连接后端服务保持长连接
12:redis 存储会话
引入以下依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
<version>2.0.5.RELEASE</version>
</dependency>
</dependencies> 添加以下配置即可
@Component
@EnableRedisHttpSession(maxInactiveIntervalInSeconds = 3600)
public class RedisConfig {
}
13:CAP原则又称CAP定理
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.3.0</version>
</dependency> 相关配置
mq.nameserver.addr=115.28.67.199:9876
mq.topicname=TopicTest rocketmq product端代码
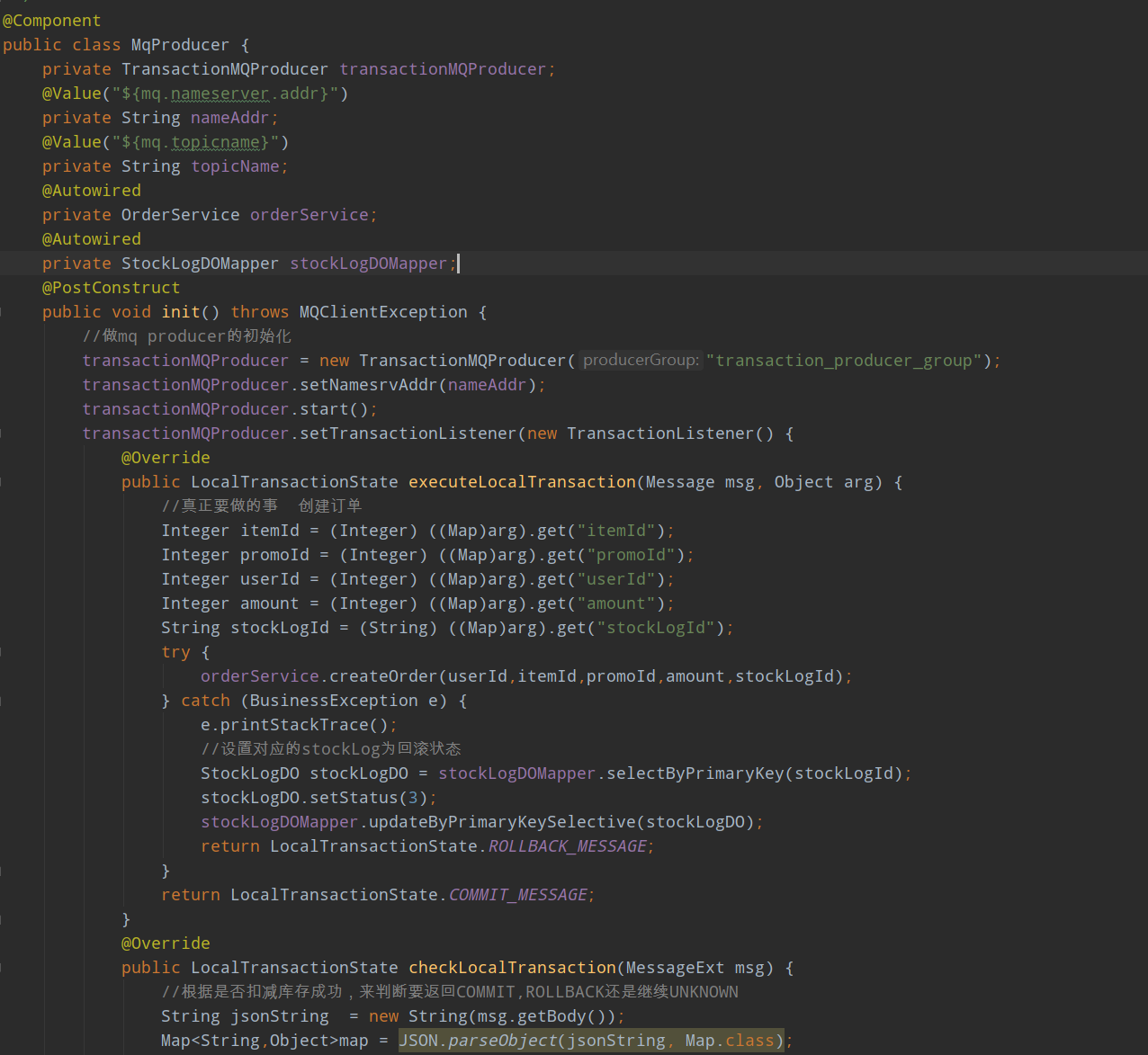
@Component
public class MqProducer {
private DefaultMQProducer producer;
private TransactionMQProducer transactionMQProducer;
@Value("${mq.nameserver.addr}")
private String nameAddr;
@Value("${mq.topicname}")
private String topicName;
@Autowired
private OrderService orderService;
@Autowired
private StockLogDOMapper stockLogDOMapper;
@PostConstruct
public void init() throws MQClientException {
//做mq producer的初始化
producer = new DefaultMQProducer("producer_group");
producer.setNamesrvAddr(nameAddr);
producer.start();
}
//同步库存扣减消息
public boolean asyncReduceStock(Integer itemId,Integer amount) {
Map<String,Object> bodyMap = new HashMap<>();
bodyMap.put("itemId",itemId);
bodyMap.put("amount",amount);
Message message = new Message(topicName,"increase",
JSON.toJSON(bodyMap).toString().getBytes(Charset.forName("UTF-8")));
try {
producer.send(message);
} catch (MQClientException e) {
e.printStackTrace();
return false;
} catch (RemotingException e) {
e.printStackTrace();
return false;
} catch (MQBrokerException e) {
e.printStackTrace();
return false;
} catch (InterruptedException e) {
e.printStackTrace();
return false;
}
return true;
}
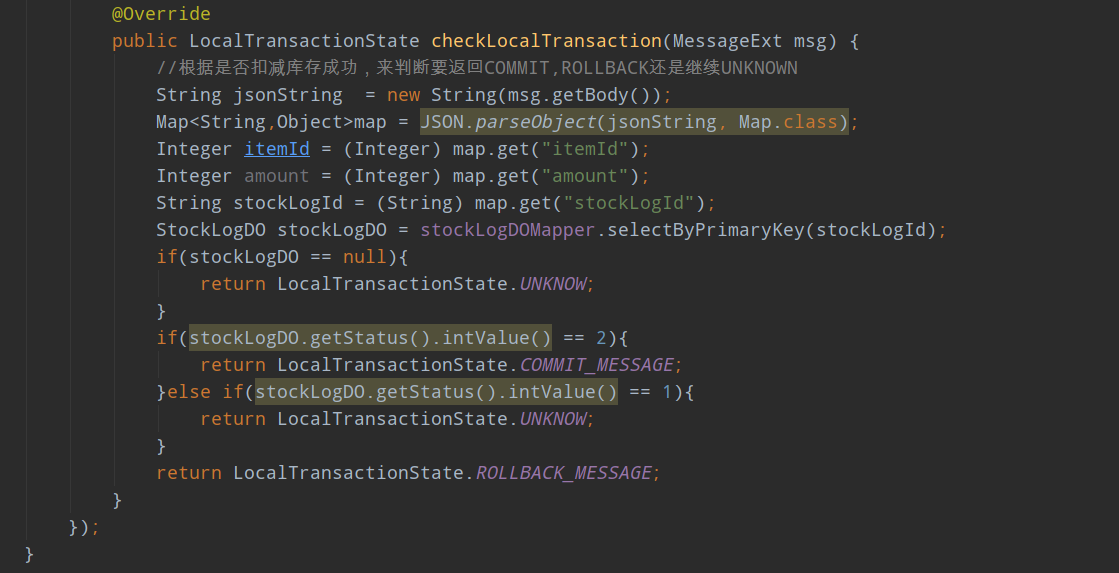
} rocketmq消费端代码
@Component
public class MqConsumer { private DefaultMQPushConsumer consumer;
@Value("${mq.nameserver.addr}")
private String nameAddr; @Value("${mq.topicname}")
private String topicName; @Autowired
private ItemStockDOMapper itemStockDOMapper; @PostConstruct
public void init() throws MQClientException {
consumer = new DefaultMQPushConsumer("stock_consumer_group");
consumer.setNamesrvAddr(nameAddr);
consumer.subscribe(topicName,"*"); consumer.registerMessageListener(new MessageListenerConcurrently() {
@Override
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
//实现库存真正到数据库内扣减的逻辑
Message msg = msgs.get(0);
String jsonString = new String(msg.getBody());
Map<String,Object>map = JSON.parseObject(jsonString, Map.class);
Integer itemId = (Integer) map.get("itemId");
Integer amount = (Integer) map.get("amount"); itemStockDOMapper.decreaseStock(itemId,amount);
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
}
}); consumer.start(); }
} 16:guava限流算法
guava限流算法使用
引入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>
private RateLimiter orderCreateRateLimiter;
@PostConstruct
public void init(){
orderCreateRateLimiter = RateLimiter.create(300);
}
这行代码,我们知道是创建一个每秒产生300个permit的速率器
if(!orderCreateRateLimiter.tryAcquire()){
throw new BusinessException(EmBusinessError.RATELIMIT);
}
17:限流方案
1:限并发
2;令牌桶算法
3;漏桶算法
限流粒度
1:接口维度
2:总维度
限流范围
1:集群限流 依赖redis以及其他中间件做统一计数器往往会产生性能瓶颈
2:单机限流 负载均衡的前提下单机平均限流效果更好
防刷方案
限制同一个会话的次数
限制同一个ip的次数
通过设备指纹 引入风控风险识别来做验证
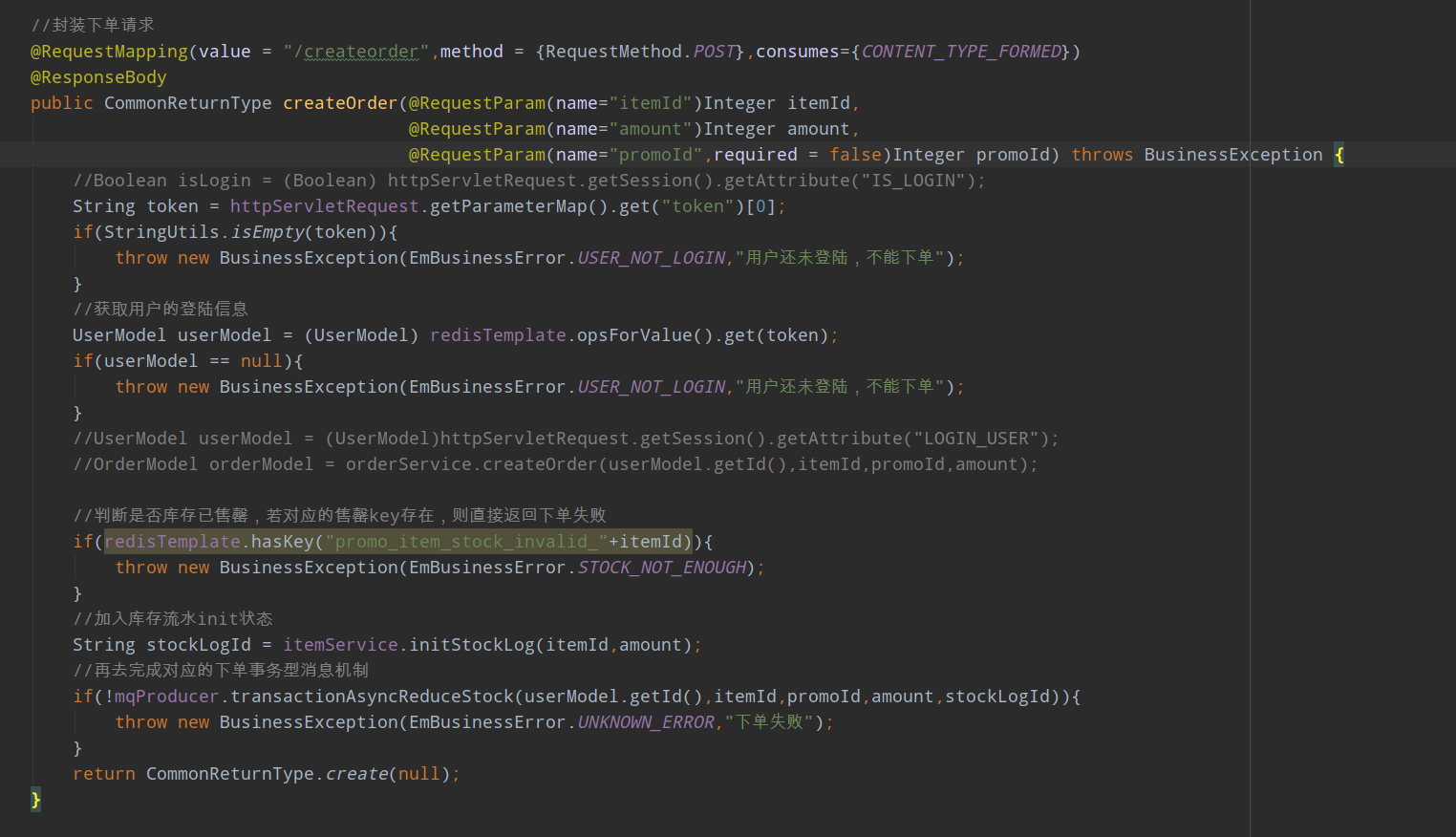
18:
依靠秒杀商品的库存 设置一个阈值 当超过这个阈值就拒绝 来控制大闸流量(因为生成的秒杀地址token也是蛮耗时的,所以这样可以避免生成过多的token)
依靠消息队列排队来限制并发流量 更细粒度可以设置消费端一次同时处理几条消息来限制并发
19: redis序列化代码
@Component
@EnableRedisHttpSession(maxInactiveIntervalInSeconds = 3600)
public class RedisConfig {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){
RedisTemplate redisTemplate = new RedisTemplate();
redisTemplate.setConnectionFactory(redisConnectionFactory); //首先解决key的序列化方式
StringRedisSerializer stringRedisSerializer = new StringRedisSerializer();
redisTemplate.setKeySerializer(stringRedisSerializer); //解决value的序列化方式
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class); ObjectMapper objectMapper = new ObjectMapper();
SimpleModule simpleModule = new SimpleModule();
simpleModule.addSerializer(DateTime.class,new JodaDateTimeJsonSerializer());
simpleModule.addDeserializer(DateTime.class,new JodaDateTimeJsonDeserializer()); objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL); objectMapper.registerModule(simpleModule); jackson2JsonRedisSerializer.setObjectMapper(objectMapper); redisTemplate.setValueSerializer(jackson2JsonRedisSerializer); return redisTemplate;
}
}
public class JodaDateTimeJsonDeserializer extends JsonDeserializer<DateTime> {
@Override
public DateTime deserialize(JsonParser jsonParser, DeserializationContext deserializationContext) throws IOException, JsonProcessingException {
String dateString =jsonParser.readValueAs(String.class);
DateTimeFormatter formatter = DateTimeFormat.forPattern("yyyy-MM-dd HH:mm:ss");
return DateTime.parse(dateString,formatter);
}
public class JodaDateTimeJsonSerializer extends JsonSerializer<DateTime> {
@Override
public void serialize(DateTime dateTime, JsonGenerator jsonGenerator, SerializerProvider serializerProvider) throws IOException {
jsonGenerator.writeString(dateTime.toString("yyyy-MM-dd HH:mm:ss"));
}
}
} 20:多级缓存
1:Redis缓存
2:热点数据内存缓存
3:nginx proxy cache缓存(key在内存中,value为文件 所以性能不是很高)
4:nginx lua 缓存
2:热点数据内存缓存
可以选择guava
可以控制大小和超时时间
可以配置lru缓存策越
线程安全
@Service
public class CacheServiceImpl implements CacheService {
private Cache<String,Object> commonCache = null;
@PostConstruct
public void init(){
commonCache = CacheBuilder.newBuilder()
//设置缓存容器的初始容量为10
.initialCapacity(10)
//设置缓存中最大可以存储100个KEY,超过100个之后会按照LRU的策略移除缓存项
.maximumSize(100)
//设置写缓存后多少秒过期
.expireAfterWrite(60, TimeUnit.SECONDS).build();
}
@Override
public void setCommonCache(String key, Object value) {
commonCache.put(key,value);
}
@Override
public Object getFromCommonCache(String key) {
return commonCache.getIfPresent(key);
}
}
21:nginx处理阶段

nginx lua插载点
- Init_by_lua:系统启动时调用
- init_worker_by_lua:worker进程启动时调用
- set_by_lua:nginx变量使用复杂lua return
- rewrite_by_lua:重写url规则
- access_by_lua:权限验证阶段
- content_by_lua:内容输出节点
content_by_lua:内容输出节点
目的
拦截url为/staticitem/get的请求
实现
1.在/usr/local/Cellar/openresty/1.15.8.1/lua/目录下新建staticitem.lua脚本
staticitem.lua
ngx.say("hello static item lua");意思就是:
以HTTP response的形式返回字符串"hello static item lua"
2.修改nginx.conf
location /staticitem/get {
content_by_lua_file /usr/local/Cellar/openresty/1.15.8.1/lua/staticitem.lua;
}实验
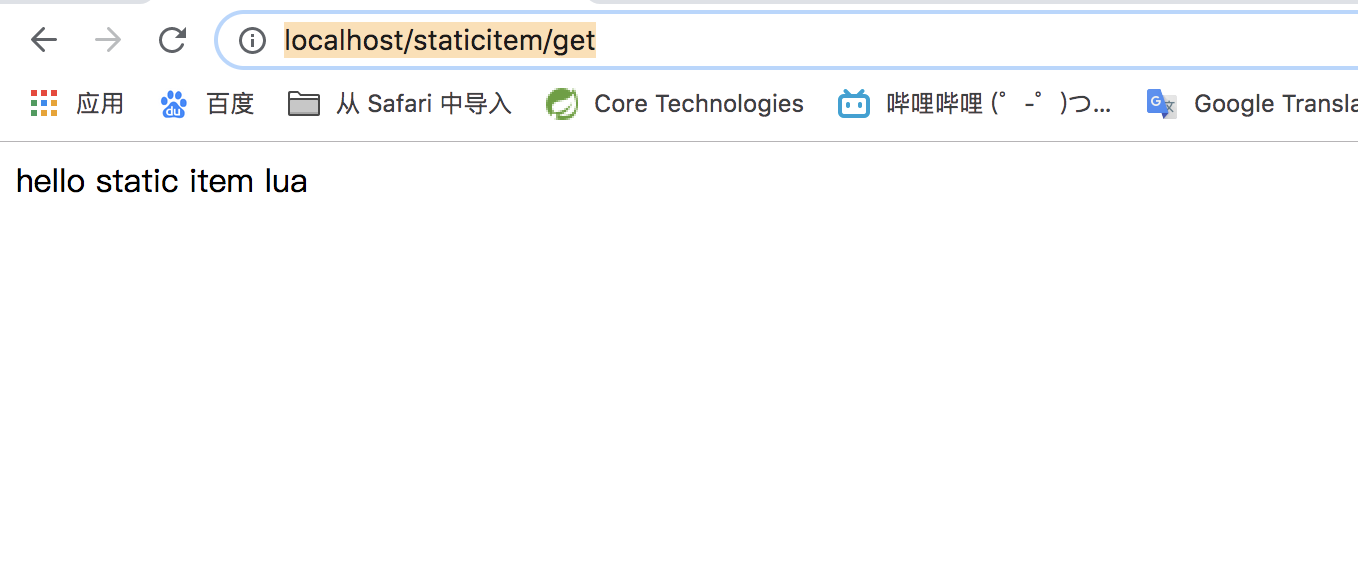
好处
nginx可以拦截nginx.conf中的location请求,将url路由到我们配置lua脚本做相应的处理。比如上面的例子中nginx就可以将/staticitem/get请求对应到我们编写的taticitem.lua,最终向浏览器返回hello static item lua
OpenResty
OpenResty
- OpenResty由Nginx核心+很多第三方模块组成,默认集成Lua开发环境,使得Nginx可以作为一个Web Server使用。
- 借助于Nginx的事件驱动模型和非阻塞IO,可以实现高性能的Web应用程序
- OpenResty提供了大量组件如mysql、redis、memcached等等,使在nginx上开发Web应用程序更方便更简单
实战
- OpenResty hello world
- shared dic:共享内存字典,所有进程可见,lru淘汰(替换到nginx自己的基于文件系统的proxy cache)
- OpenResty对redis的支持
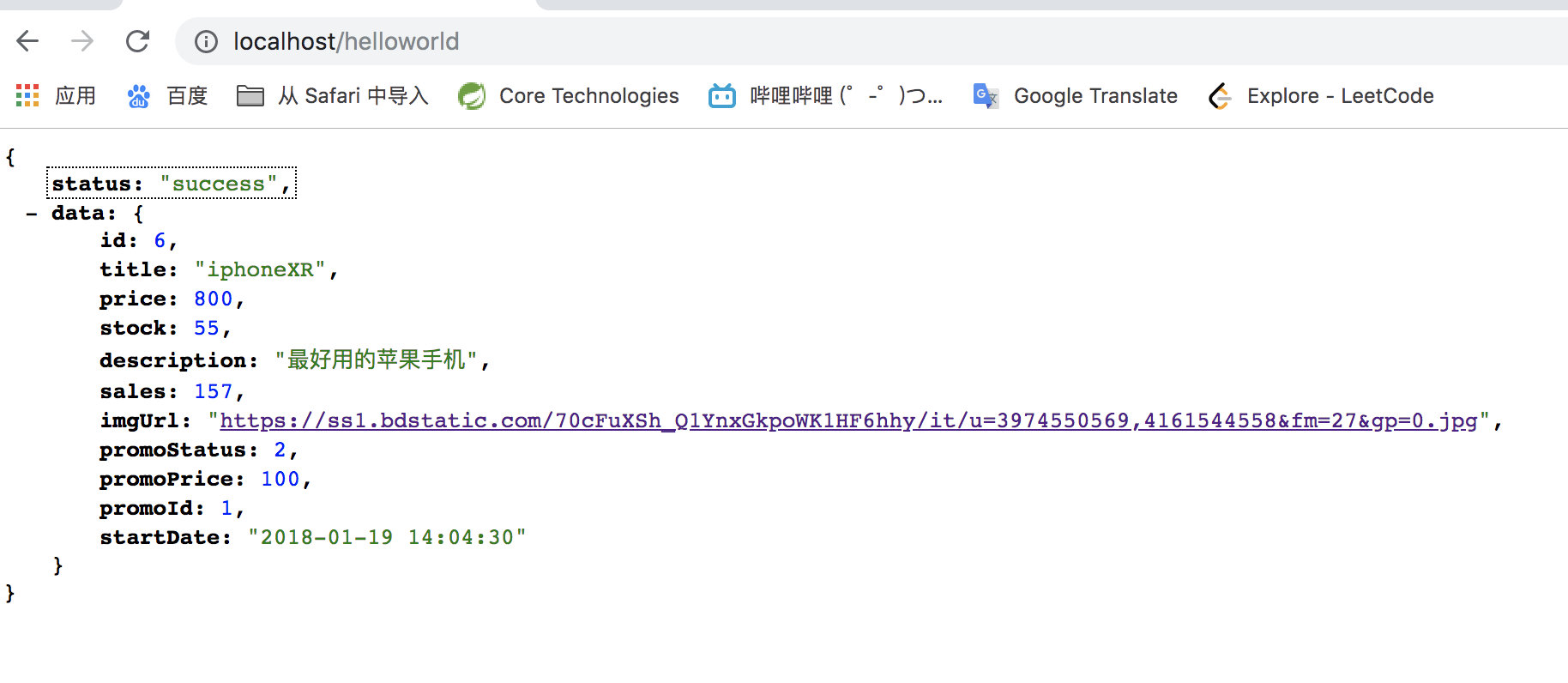
OpenResty hello world
- 在
/usr/local/Cellar/openresty/1.15.8.1/lua/目录下创建helloworld.lua脚本
ngx.exec("/item/get?id=6");修改nginx.conf配置
#openresty helloworld
location /helloworld{
content_by_lua_file /usr/local/Cellar/openresty/1.15.8.1/lua/helloworld.lua;
}实验
显示:
shared dic
在
/usr/local/Cellar/openresty/1.15.8.1/lua/目录下创建itemshareddic.lua脚本function get_from_cache(key)
local cache_ngx=ngx.shared.my_cache
local value=cache_ngx:get(key)
return value
end function set_to_cache(key,value,exptime)
if not exptime then
exptime =0
end
local cache_ngx=ngx.shared.my_cache
local succ,err,forcible=cache_ngx:set(key,value,exptime)
return succ
end local args=ngx.req.get_uri_args();
local id=args["id"]
local item_model=get_from_cache("item_"..id);
if item_model == nil then
local resp=ngx.location.capture("/item/get?id="..id)
item_model = resp.body
set_to_cache("item_"..id,item_model,1*60)
end
ngx.say(item_model)修改nginx.conf
location /luaitem/get {
default_type "application/json";
content_by_lua_file /usr/local/Cellar/openresty/1.15.8.1/lua/itemshareddic.lua;
}实验
输入http://localhost/luaitem/get?id=6
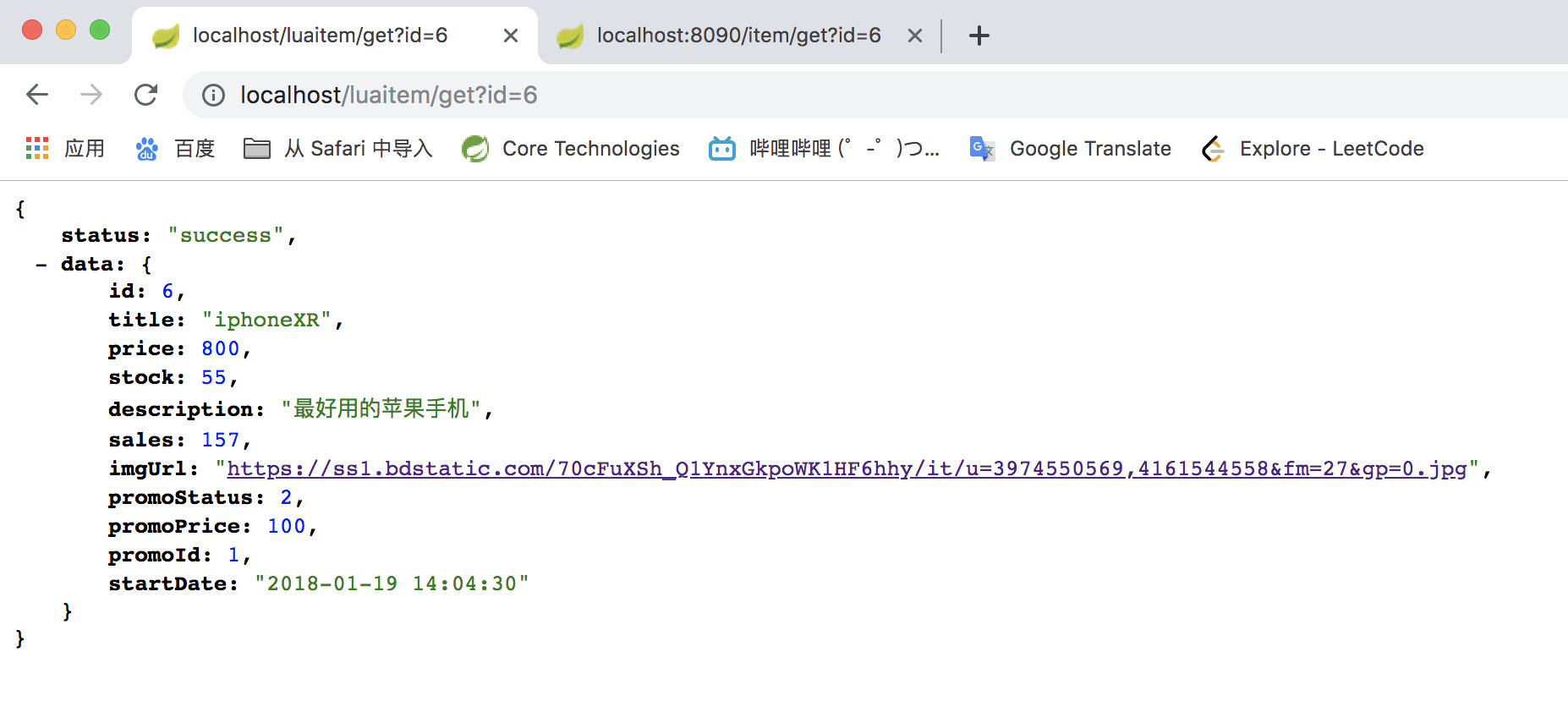 实验图
实验图
OpenResty对redis的支持
在
/usr/local/Cellar/openresty/1.15.8.1/lua/目录下创建itemredi.lua脚本local args=ngx.req.get_uri_args()
local id=args["id"]
local redis= require "resty.redis"
local cache=redis:new()
local ok,err= cache:connect("localhost",6379)
local item_model=cache:get("item_"..id)
if item_model==ngx.null or item_model==nil then
local resp=ngx.location.capture("/item/get?id="..id)
item_model=resp.body
end
ngx.say(item_model)修改nginx.conf
location /luaitem/get {
default_type "application/json";
content_by_lua_file /usr/local/Cellar/openresty/1.15.8.1/lua/itemredis.lua;
}实验
输入http://localhost/luaitem/get?id=6
实验图

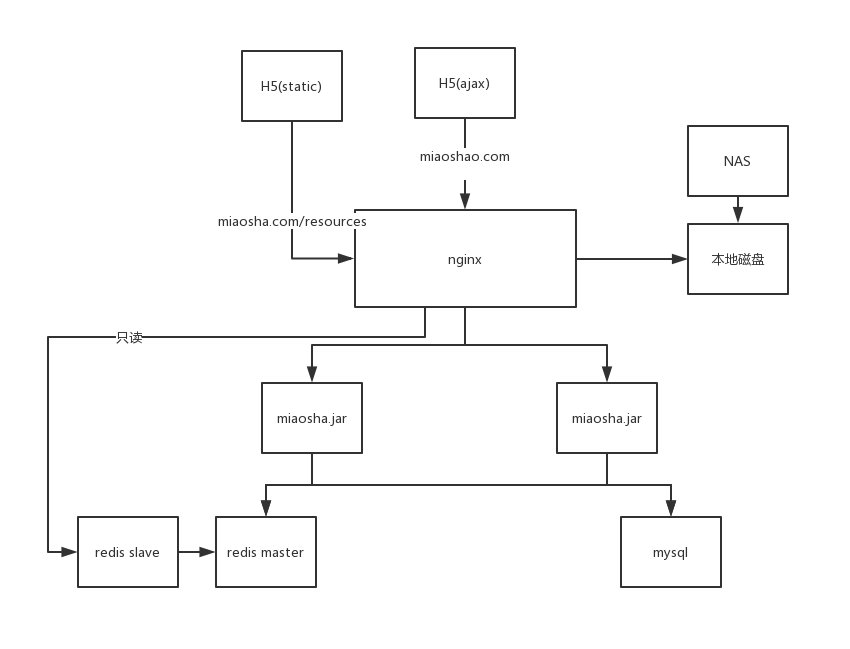
优化的是H5(static),请求走静态资源文件。
将静态资源的请求路由到CDN
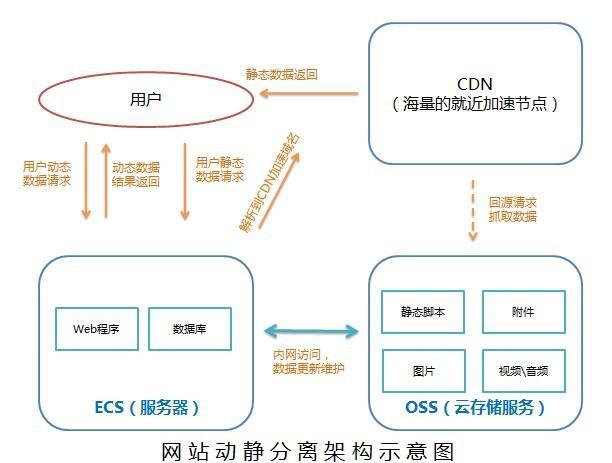
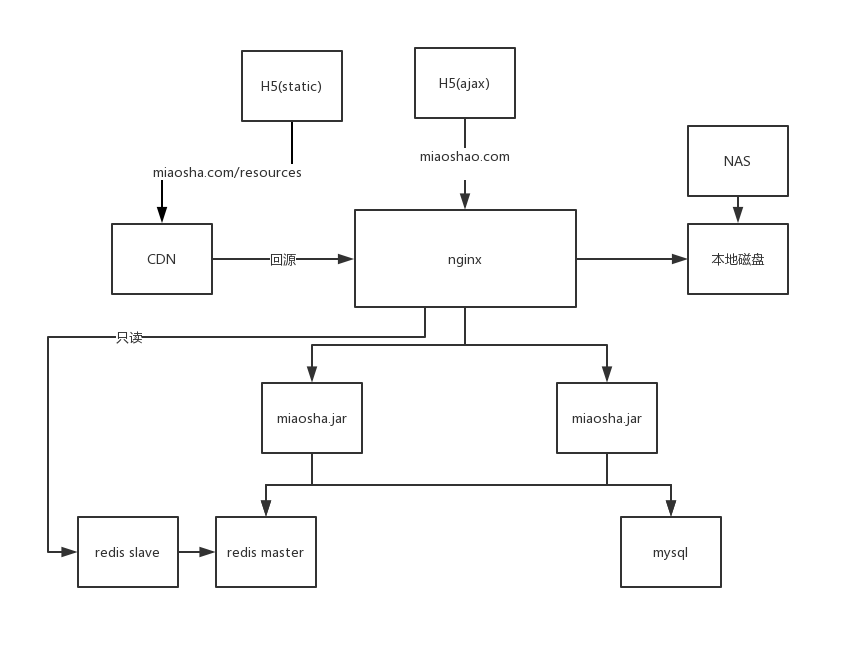
结构图
DNS用CNAME解析源站
回源缓存设置
cache control响应头
Request Headers:
例:
GET / HTTP/1.1
Host: localhost:4000
Connection: keep-alive
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36
Accept:text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: Hm_lvt_512065947708a980c982b4401d14c2f5=1551084094; SESSION=OGQzOGIzMGEtZGYyNy00MjQ4LWI1ZGYtMjc2OTAxYjJmNjEz###cache control有几种取值:
private:客户端可以缓存(请求发起的浏览器才可以缓存)
public:客户端和代理服务器(反向或正向代理)都可以缓存
max-age=xxx:缓存的内容将在xxx秒之后失效
也就是说我们对应缓存的内容,从收到服务端的这个max-age返回数据开始,存储xxx秒后这个请求就失效,客户端必须往对应的服务端上面再次发起请求,用来验证和结束对应的请求体
no-cache:强制向服务端再验证一次(会将对应的缓存存储在客户端,但是在下次用的时候要向服务端验证一次这个缓存到底是能用还是不能用,no-store是压根不存)
no-store:不缓存请求的任何返回内容
怎么选择HTTP cache control头
有效性判断
- ETag:资源唯一标识
- If-None-Match:客户端发送的匹配ETag标识符
- Last-modified:资源最后被修改时间
- If-Modified-Since:客户端发送的匹配资源最后修改时间的标识符
补充:
ETag:
一般是将请求的资源做一个MD5或者类似hash操作,生成一个ETag的唯一标识,服务端在第一次返回内容中加上这个ETag的唯一标识,一起返回给浏览器,浏览器会存储下来这个ETag;下一次请求的时候,所谓的有效性判断,是浏览器将之前缓存下来内容的ETag的值一起带到服务器上,用来验证说它不发送具体的响应,而是发送一个对应的HTTP请求并且带上这个ETag的值,服务端会将这个ETag的值和我本地的文件ETag内容做比较,若比较是一致的,就返回304 not-modified,告诉客户端说服务端这个内容是有效的,直接使用浏览器里的缓存即可
若If-Modified-Since的值早于Last-modified的值,证明是无效的;若晚于Last-modified的值,则是有效的,说明这段时间资源没有被修改过。
用户请求浏览器资源的网站路径
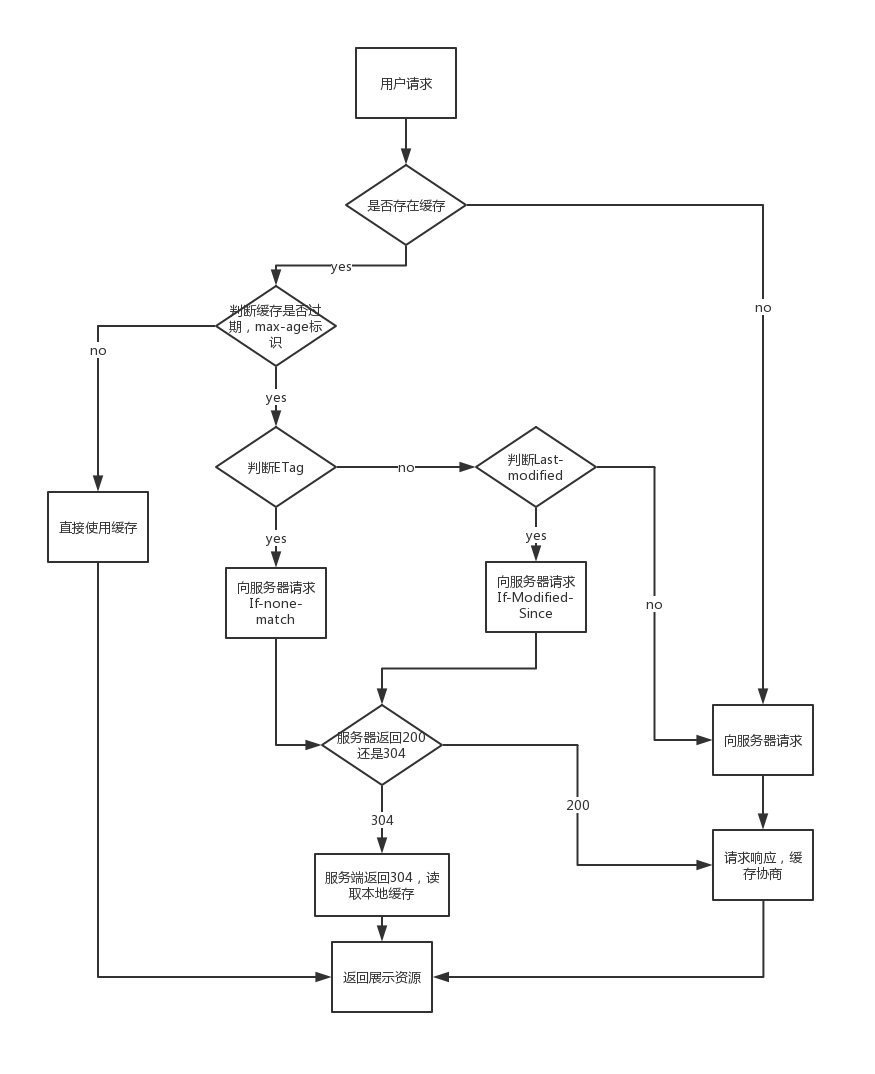
浏览器三种刷新方式
- 回车刷新或者a链接(get请求跳转):看cache-control对应的max-age是否仍然有效,有效则直接从cache取对应的数据,若cache-control中为no-cache,则进入缓存协商逻辑
- F5刷新(Windows)或者command+R(macOS)刷新:去掉cache-control中的max-age或者直接设置max-age为0,然后进入缓存协商逻辑
- ctrl+F5或commond+shift+R刷新:去掉cache-control和协商头,强制刷新 (强制从服务端拿内容)
对应的协商机制:
比较Last-modified和ETag到服务端,若服务端判断没变化则304不返回数据,否则200返回数据
CDN自定义缓存策略
- 可自定义目录过期时间
- 可自定义后缀名过期时间
- 可自定义对应权重
- 可通过界面或api强制cdn对应目录刷新(不一定保证成功)
阿里云CDN配置
cdn缓存
cdn缓存是一种服务端缓存,CDN服务商将源站的资源缓存到遍布全国的高性能加速节点上,当用户访问相应的业务资源时,用户会被调度至最接近的节点最近的节点ip返回给用户,在web性能优化中,它主要起到了,缓解源站压力,优化不同用户的访问速度与体验的作用。
缓存规则
与http缓存规则不同的是,这个规则并不是规范性的,而是由cdn服务商来制定,我们以腾讯云举例,打开cdn加速服务配置,面板如下。
可以看到,提供给我们的配置项只有文件类型(或文件目录)和刷新时间,意义也很简单,针对不同文件类型,在cdn节点上缓存对应的时间。
cdn运作流程
由图我们可以看出,cdn缓存的配置主要作用在缓存处理阶段,虽然配置项只有文件类型和缓存时间,但流程却并不简单,我们先来明确一个概念——回源,回源的意思就是返回源站,何为源站,就是我们自己的服务器,很多人误解接入cdn就是把资源放在了cdn上,其实不然,如图中所示,接入cdn后,我们的服务器就是源站,源站一般情况下只会在cdn节点没有资源或cdn资源失效时接收到cdn节点的请求,其他时间,源站并不会接收请求(当然,如果我们知道源站的地址,我们可以直接访问源站)。明确了回源的概念后,cdn的流程就显得不那么复杂了,简单的理解就是,没有资源就去源站读取,有资源就直接发送给用户。与http缓存不同的是,cdn中没有no-cache(max-age=0)的情况,当我们设置缓存时间为0的时候,该类型文件就被认定为不缓存文件,就是所有请求直接转发源站,只有当缓存时间大于0且缓存过期的时候,才会与源站对比缓存是否被修改。
缓存配置
cdn缓存配置并不麻烦,整体来说,建议和http缓存配置保持统一。需要特别注意的是,cdn的缓存配置会受到http缓存配置的影响,而且各个cdn服务商并不完全一致,以腾讯云为例,在缓存配置的文档中特别有以下说明。
这会对我们有什么影响呢?
- 如果我们http缓存设置cache-control: max-age=600,即缓存10分钟,但cdn缓存配置中设置文件缓存时间为1小时,那么就会出现如下情况,文件被访问后第12分钟修改并上传到服务器,用户重新访问资源,响应码会是304,对比缓存未修改,资源依然是旧的,一个小时后再次访问才能更新为最新资源
- 如果不设置cache-control呢,在http缓存中我们说过,如果不设置cache-control,那么会有默认的缓存时间,但在这里,cdn服务商明确会在没有cache-control字段时主动帮我们添加cache-control: max-age=600。
注:针对问题1,也并非没有办法,当我们必须要在缓存期内修改文件,并且不向想影响用户体验,那么我们可以使用cdn服务商提供的强制更新缓存功能,主要注意的是,这里的强制更新是更新服务端缓存,http缓存依然按照http头部规则进行自己的缓存处理,并不会受到影响。
小结
cdn缓存的配置并不复杂, 复杂的情况在于cdn缓存配置会受到http缓存配置的影响,并且不同的cdn运营商对于这种影响的处理也都不一致,实际使用时,建议去对应的cdn服务商文档中找到对应的注意事项。
最新文章
- OpenGL学习资料汇总
- Zabbix 3.0 安装笔记
- php路径目录解析函数dirname basename pathinfo区别及实例
- Great StackOverflow questions
- BX2001: IE 支持使用 window.clipboardData 访问系统剪贴板,Chrome 和 Safari 中存在类似的 Clipboard 对象但尚未实现,Firefox 和 Opera 不支持这类对象
- 比特币钱包应用breadwallet源码
- faplayer编译配置经验
- Java面向对象编辑
- Google photos -- reverse thinking
- qmake 小结(Qt 5.4)
- table新增空白行到首行
- 编译安装PHP 时遇到问题解决方法.
- Netty的并发编程实践3:CAS指令和原子类
- 【转载】Sqlserver通过维护计划定时自动备份数据库
- Keil常见错误汇总及处理方式
- [svc]通过bridge连接单机的多个网络namespace
- 某些浏览器没有canvas.toBlob 方法的解决方案
- cannot send list of active checks to [ZabbixServerIp]: host [Zabbix server] not found
- JS替换地址栏参数值
- 好记性不如烂笔头-linux学习笔记1