9、共享变量(Broadcast Variable和Accumulator)
2024-08-22 11:44:05
一、共享变量
1、共享变量工作原理
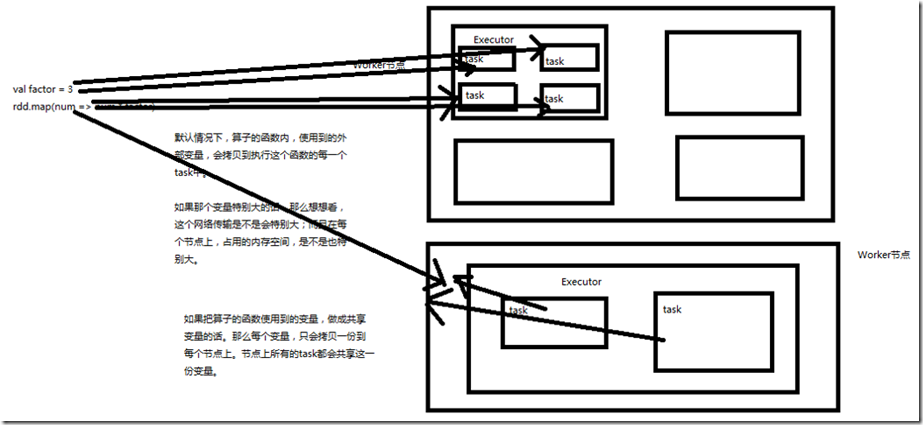
Spark一个非常重要的特性就是共享变量。 默认情况下,如果在一个算子的函数中使用到了某个外部的变量,那么这个变量的值会被拷贝到每个task中。此时每个task只能操作自己的那份变量副本。如果多个task想
要共享某个变量,那么这种方式是做不到的。 Spark为此提供了两种共享变量,一种是Broadcast Variable(广播变量),另一种是Accumulator(累加变量)。Broadcast Variable会将使用到的变量,仅仅为每个节点拷贝
一份,更大的用处是优化性能,减少网络传输以及内存消耗。Accumulator则可以让多个task共同操作一份变量,主要可以进行累加操作。
2、Broadcast Variable
Spark提供的Broadcast Variable,是只读的。并且在每个节点上只会有一份副本,而不会为每个task都拷贝一份副本。因此其最大作用,就是减少变量到各个节点的网络传
输消耗,以及在各个节点上的内存消耗。此外,spark自己内部也使用了高效的广播算法来减少网络消耗。 可以通过调用SparkContext的broadcast()方法,来针对某个变量创建广播变量。然后在算子的函数内,使用到广播变量时,每个节点只会拷贝一份副本了。每个节点可以使
用广播变量的value()方法获取值。记住,广播变量,是只读的。 ------java实现------ package cn.spark.study.core; import java.util.Arrays;
import java.util.List; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.broadcast.Broadcast; /**
* 广播变量
* @author bcqf
*
*/ public class BroadcastVariable {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("BroadcastVariable").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); // 在java中,创建共享变量,就是调用SparkContext的broadcast()方法
// 获取的返回结果是Broadcast<T>类型
final int factor = 3;
final Broadcast<Integer> factorBroadcast = sc.broadcast(factor); List<Integer> numberList = Arrays.asList(1,2,3,4,5); JavaRDD<Integer> numbers = sc.parallelize(numberList); //让集合中的每个数字,都乘以外部定义的那个factor
JavaRDD<Integer> multipleNumbers = numbers.map(new Function<Integer, Integer>() { private static final long serialVersionUID = 1L; @Override
public Integer call(Integer v1) throws Exception {
// 使用共享变量时,调用其value()方法,即可获取其内部封装的值
int factor = factorBroadcast.value();
return v1 * factor;
}
}); multipleNumbers.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
System.out.println(t);
}
}); sc.close();
}
} //结果
3
6
9
12
15
--------scala实现-------- package cn.spark.study.core import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object BroadcastVariable {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("BroadcastVariable").setMaster("local")
val sc = new SparkContext(conf) val factor = 3;
val factorBroadcast = sc.broadcast(factor) val numberArray = Array(1,2,3,4,5)
val numbers = sc.parallelize(numberArray, 1) val multipleNumbers = numbers.map { num => num * factorBroadcast.value}
multipleNumbers.foreach { num => println(num)}
}
}
3、Accumulator
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能。但是确给我们提供了多个task对一个变量并行操作的功能。
但是task只能对Accumulator进行累加操作,不能读取它的值。只有Driver程序可以读取Accumulator的值。 ------java实现------- package cn.spark.study.core; import java.util.Arrays;
import java.util.List; import org.apache.spark.Accumulator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.VoidFunction; public class AccumulatorVariable {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("Accumulator").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf); // 创建Accumulator变量
// 需要调用SparkContext的accumulator()方法
final Accumulator<Integer> sum = sc.accumulator(0); List<Integer> numberList = Arrays.asList(1,2,3,4,5);
JavaRDD<Integer> numbers = sc.parallelize(numberList); numbers.foreach(new VoidFunction<Integer>() { private static final long serialVersionUID = 1L; @Override
public void call(Integer t) throws Exception {
// 然后在函数内部,就可以对Accumulator变量,调用add()方法,累加值
sum.add(t);
}
}); // 在driver程序中,可以调用Accumulator的value()方法,获取其值
System.out.println(sum.value()); sc.close();
} } //结果
15 --------scala实现--------- package cn.spark.study.core import org.apache.spark.SparkConf
import org.apache.spark.SparkContext object AccumulatorVariable {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("AccumulatorVariable").setMaster("local")
val sc = new SparkContext(conf) val sum = sc.accumulator(0) val numberArray = Array(1,2,3,4,5)
val numbers = sc.parallelize(numberArray, 1)
numbers.foreach {num => sum += num } println(sum)
}
}
最新文章
- 我的android学习经历9
- LeetCode 刷题顺序表
- GTD中定位篇
- JavaScript功能检测技术和函数构造
- servlet请求转发、包含以及重定向
- Oracle导入excel数据方法汇总[转]
- 1629 B君的圆锥
- JavaScript中的鼠标滚轮事件详解
- 【LCT】BZOJ3091 城市旅行
- 基于event 实现的线程安全的优先队列(python实现)
- 目标检测(七)YOLOv3: An Incremental Improvement
- 【题解】Luogu SP3267 DQUERY - D-query
- Java-Runoob-高级教程-实例-方法:03. Java 实例 – 汉诺塔算法-un
- web-day10
- WPF学习笔记(2):准确定位弹出窗
- JavaScript常用操作,常用类
- DDD CQRS和Event Sourcing的案例:足球比赛
- django rest_framework 框架的使用02
- Python爬虫:爬取美拍小姐姐视频
- es put mapping