主要排序算法(Python实现)
1. 冒泡排序
算法描述:1. 比较相邻的两个数,对升序(/降序)而言,若当前数小于(大于)后一个数则交换两者的位置。
2.那么循环长度为L的列表,从第一个元素到倒数第(L-1)元素进行第1步操作,其结果是第L个元素必定是最小值;也就是说单次循环确定了一个数的排序位置,单次循环次数为(L-1);
3. 要确定所有元素的排序位置,还需要L-1次,因为每次循环确定了一个元素的位置,当第(L-1)次循环时,L-1个元素的位置都被确定了,剩下的一个自然被确定。
图片演示:
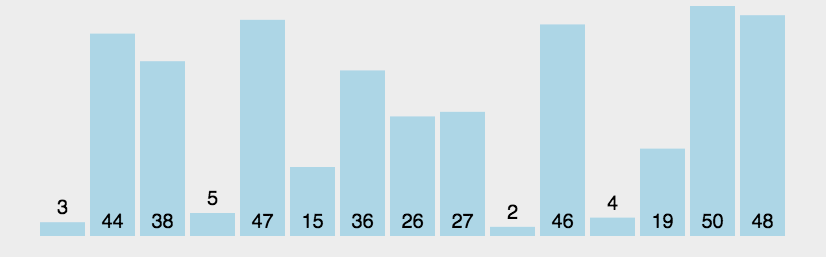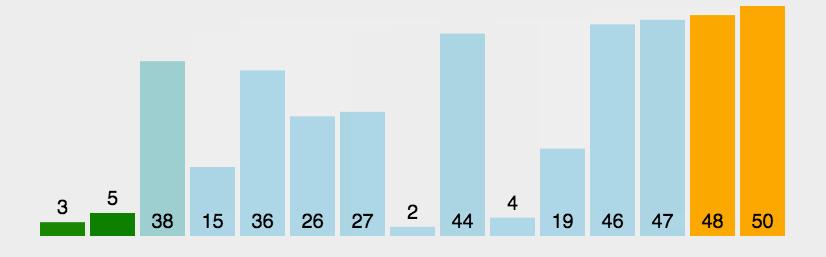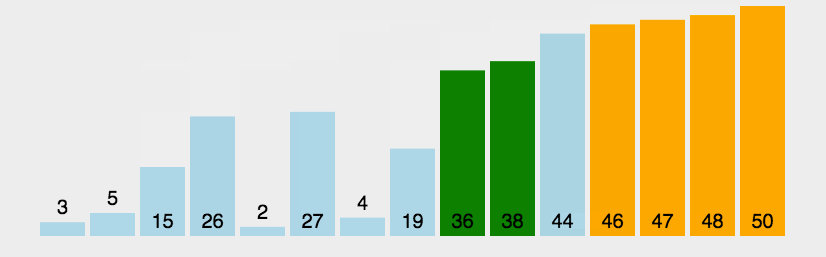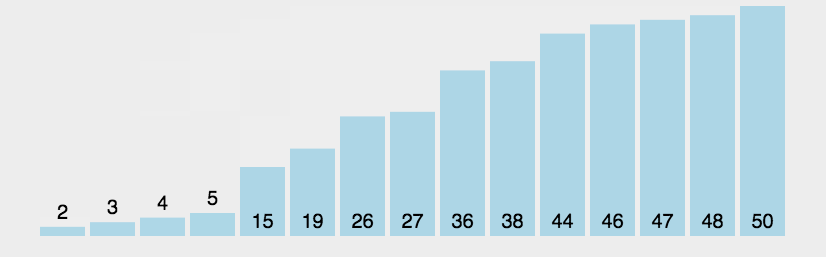
代码实现:
# coding:utf-8
import timeit def bubble_sort(seq:list):
"""冒泡排序, seq为有效待排序列表"""
for i in range(len(seq)-1):
for j in range(len(seq)-1):
if seq[j] < seq[j+1]:
seq[j], seq[j+1] = seq[j+1], seq[j]
return seq if __name__ == '__main__':
print(bubble_sort([i for i in range(10)]))
# t = timeit.Timer("bubble_sort([i for i in range(1000)])", "from __main__ import bubble_sort")
# print(t.timeit())
运行结果:

最优时间复杂度:O(N)
最坏时间复杂度:O(N^2)
稳定性:稳定
2. 选择排序
算法描述:1. 将当前元素与其后所有元素进行比较,若大于(小于)则置换两个元素;
2. 对于长度为L的列表,第1步操作完成能确定一个元素的位置;
3.要确定L个元素的位置,则需循环L-1次;
图片演示:

代码实现:
# coding:utf-8 def select_sort(seq:list):
"""选择排序(降序)"""
for i in range(len(seq)-1):
# 暂存待置换的元素的值
cur_max = seq[i]
for j in range(i+1, len(seq)):
if seq[j] > cur_max:
cur_max = seq[j]
seq[i], seq[j] = seq[j], seq[i]
return seq if __name__ == '__main__':
print(select_sort([i for i in range(10)]))
最优时间复杂度:O(N^2)
最坏时间复杂度:O(N^2)
稳定性:不稳定
3. 插入排序
算法描述:选择排序的关键在于向后比较,而插入排序与之相反,是向前比较并调整相应元素位置;
1. 对于列表长度为L的列表而言,循环从第N个数开始向前与第N-1进行比较,若大于(小于)则交换位置;
2. 要实现所有的数排序,另加一层L-1次的循环;
图片演示:

代码实现:
# coding:utf-8 def insert_sort(seq:list):
"""插入排序(降序)"""
for i in range(len(seq)):
for j in range(i, 0, -1):
# 倒序交换相邻两个的取值
if seq[j] > seq[j-1]:
seq[j], seq[j-1] = seq[j-1], seq[j]
return seq if __name__ == '__main__':
print(insert_sort([i for i in range(10)]))
最优时间复杂度:O(N)
最坏时间复杂度:O(N^2)
稳定性:稳定
4. 快速排序
算法描述:
图片演示:


代码实现:
# coding:utf-8 def fast_sort(seq:list, left, right):
"""
快速排序(升序)
:param left:左部起始位置
:param right: 右部起始位置
"""
if right<=left:
return low = left
high = right # 基准值
mid = seq[left] while low < high:
# 从右扫描找出小于基准值的数
while low<high and seq[high]>mid:
high -= 1
seq[low] = seq[high]
# 向左扫描找出大于基准值的数
while low<high and seq[low]<=mid:
low += 1
seq[high] = seq[low] # 此时low=high, 确定了基准值在序列中的排序位置
seq[low] = mid # 递归排序low左右两边的序列
fast_sort(seq, low+1, right)
fast_sort(seq, left, low-1) if __name__ == '__main__':
seq = [i for i in range(10,0,-1)]
fast_sort(seq, 0, len(seq)-1)
print(seq)
最优时间复杂度:O(NlogN)
最坏时间复杂度:O(N^2)
稳定性:不稳定
5. 希尔排序
算法描述:
希尔排序是对插入排序的一种优化,主要在于设置了以步长来比较两个元素的值;
1.
图片演示:

代码实现:
最优时间复杂度:O(NlogN)
最坏时间复杂度:O(N^2)
稳定性:不稳定
最新文章
- 02shell编程环境的搭建
- Razor语法中链接的一些方法
- Configure Amazon RDS mysql to store Chinese Characters
- oracle 锁的介绍 (转)
- JSP取得绝对路径
- python 字符编码问题
- 程序设计模式 —— State 状态模式
- JAVA解析各种编码密钥对(DER、PEM、openssh公钥)
- IntelliJ IDEA 13.x 下使用Hibernate + Spring MVC + JBoss 7.1.1
- Hadoop概念学习系列之分布式文件系统(三十)
- Aspcms所有标签调用
- 去掉MySQL字段中的空格
- CodeForces 14 E - Camels &amp;&amp; D - Two Paths
- linux 同步机制之complete【转】
- 这个发现是否会是RSA算法的BUG、或者可能存在的破解方式?
- 【运维监控】四款云服务监控工具介绍:Nagios 、 ganglia、zabbix、onealert
- 【转】iptables 命令介绍
- delphi 验证码识别(XE8源码)
- MSSQL sql server order by 1,2 的具体含义
- 20135316王剑桥Linux内核学习记笔记第七周
热门文章
- flutter 动画
- SASS系列之:!global VS !deafult
- ORACLE主键ID的生成
- springboot学习入门简易版七---springboot2.0使用@Async异步执行方法(17)
- [daily][qemu][kvm] 使用qemu/kvm模拟numa节点
- STM32+IAR 解决Error[Pe147]: declaration is incompatible with "__nounwind __interwork __softfp unsigned
- Java注解annotation : invalid type of annotation member
- 使用BERT模型生成句子序列向量
- [牛客网 -leetcode在线编程 -02] minimum-depth-of-binary-tree -树的最短深度
- SQL中 count(*)和count(1)的对比,区别