Scala,Java,Python 3种语言编写Spark WordCount示例
2024-09-02 06:54:02
首先,我先定义一个文件,hello.txt,里面的内容如下:
hello spark
hello hadoop
hello flink
hello storm
Scala方式
scala版本是2.11.8。
配置maven文件,三个依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0-cdh5.7.0</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0</version>
</dependency>
package com.darrenchan.spark
import org.apache.spark.{SparkConf, SparkContext}
object SparkCoreApp2 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("WordCountApp")
val sc = new SparkContext(sparkConf)
//业务逻辑
val counts = sc.textFile("D:\\hello.txt").
flatMap(_.split(" ")).
map((_, 1)).
reduceByKey(_+_)
println(counts.collect().mkString("\n"))
sc.stop()
}
}
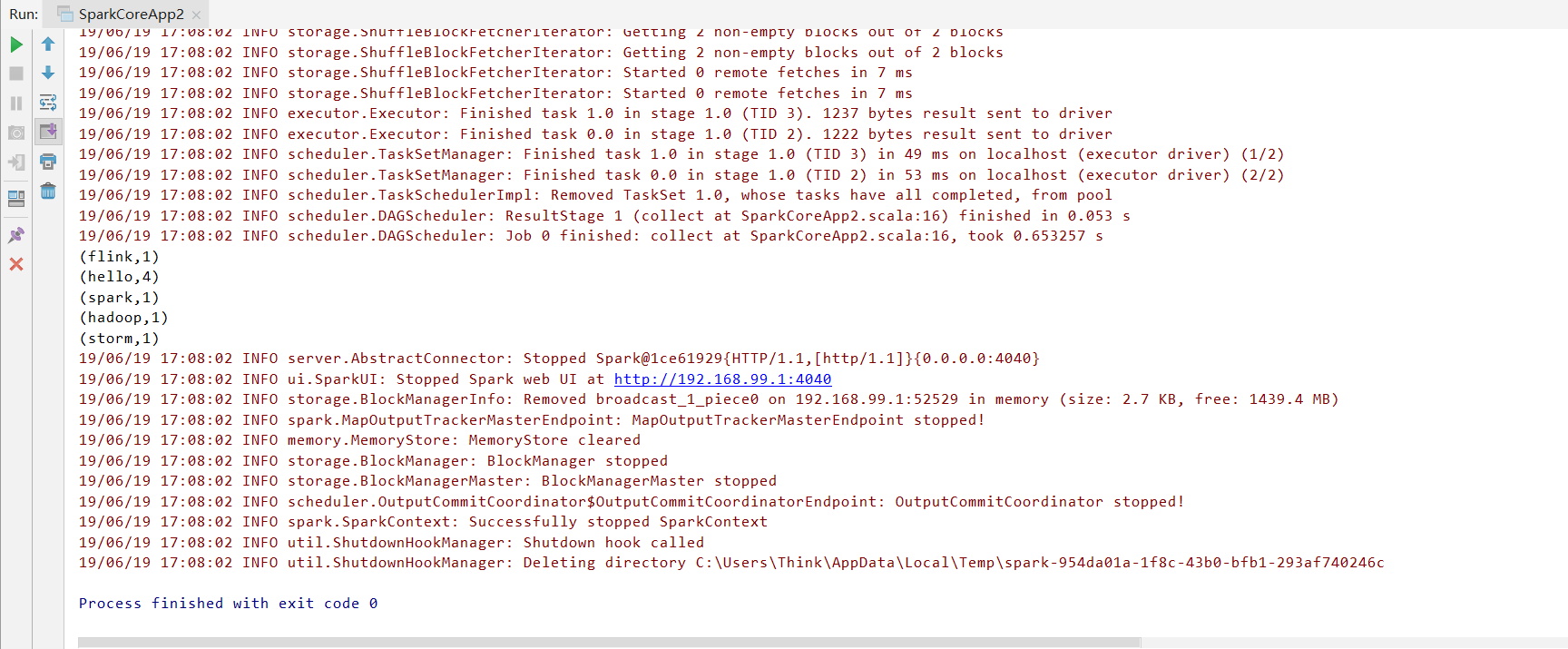
运行结果:
Java方式
Java8,用lamda表达式。
package com.darrenchan.spark.javaapi; import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2; import java.util.Arrays; public class WordCountApp2 {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf().setMaster("local[2]").setAppName("WordCountApp");
JavaSparkContext sc = new JavaSparkContext(sparkConf); //业务逻辑
JavaPairRDD<String, Integer> counts =
sc.textFile("D:\\hello.txt").
flatMap(line -> Arrays.asList(line.split(" ")).iterator()).
mapToPair(word -> new Tuple2<>(word, 1)).
reduceByKey((a, b) -> a + b); System.out.println(counts.collect()); sc.stop();
}
}
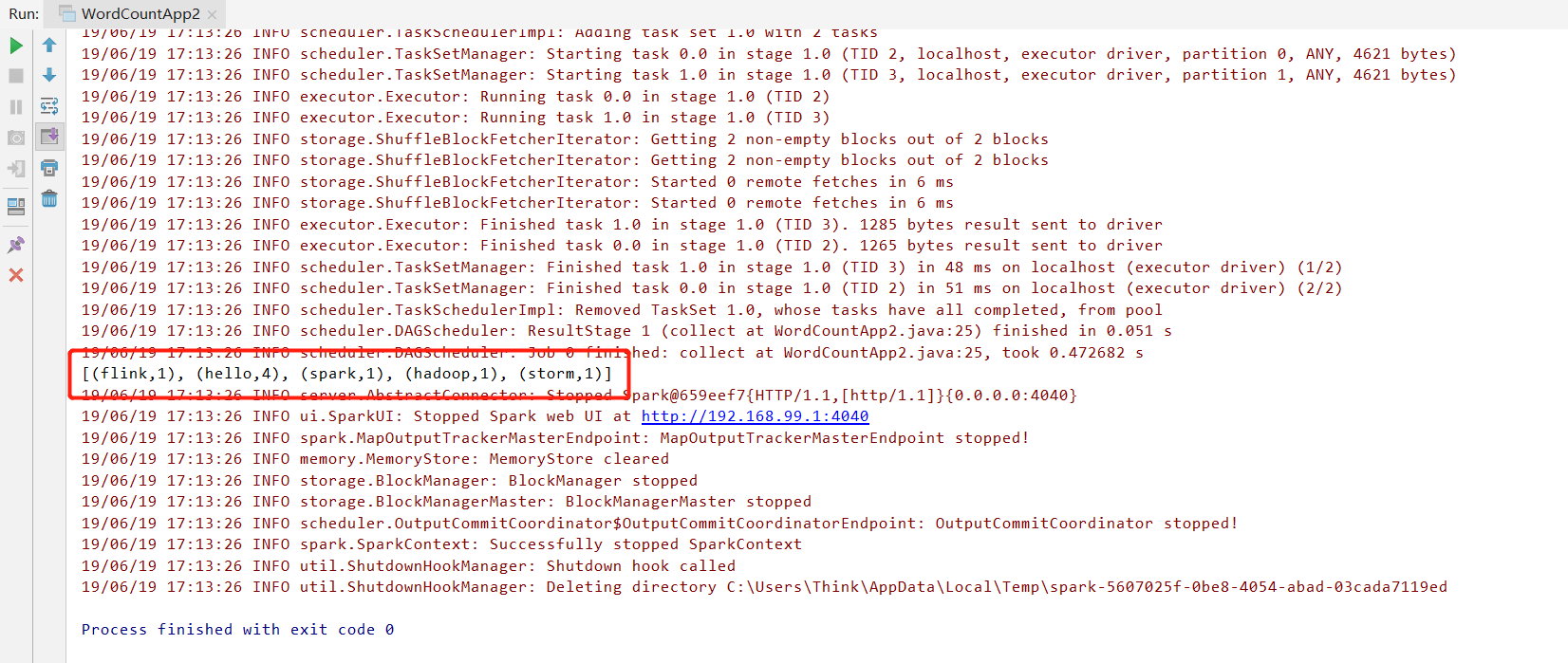
运行结果:
Python方式
Python 3.6.5。
from pyspark import SparkConf, SparkContext def main():
# 创建SparkConf,设置Spark相关的参数信息
conf = SparkConf().setMaster("local[2]").setAppName("spark_app")
# 创建SparkContext
sc = SparkContext(conf=conf) # 业务逻辑开发
counts = sc.textFile("D:\\hello.txt").\
flatMap(lambda line: line.split(" ")).\
map(lambda word: (word, 1)).\
reduceByKey(lambda a, b: a + b) print(counts.collect()) sc.stop() if __name__ == '__main__':
main()
运行结果:

使用Python在Windows下运行Spark有很多坑,详见如下链接:
http://note.youdao.com/noteshare?id=aad06f5810f9463a94a2d42144279ea4
最新文章
- vmware备忘
- python安装locustio报错error: invalid command 'bdist_wheel'的解决方法
- 关于Oracle AUTONOMOUS TRANSACTION(自治事务)的介绍
- 李洪强iOS经典面试题143-绘图与动画
- 慕课网__CSS_网页图标制作
- 使用shell操作mysql(转)
- SSH basics
- angular中$cacheFactory缓存的使用
- org.apache.flume.FlumeException: NettyAvroRpcClient { host: xxx.xxx.xxx.xxx, port: 41100 }: RPC
- android中文件操作的四种枚举
- NDK(8)"Unknown Application ABI"的解决方案
- [TYVJ1827]『Citric II』一道防AK好题
- 向日葵sunlogin配置
- 外网SSH访问内网LINUX的N种方法
- silverlight与wcf双向通讯 例子
- SQL Server 性能调优培训引言
- Spring Boot中采用Mockito来mock所测试的类的依赖(避免加载spring bean,避免启动服务器)
- 月薪20k以上的高级程序员需要学习哪些技术呢?
- hasattr(),getattr(),setattr()的使用
- 关于使用Git的几点小技巧