Pandas文本数据处理
2024-10-07 08:41:00
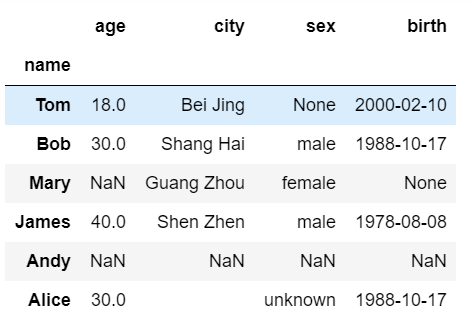
先初始化数据
import pandas as pd
import numpy as np
index = pd.Index(data=["Tom", "Bob", "Mary", "James", "Andy", "Alice"], name="name")
data = {
"age": [18, 30, np.nan, 40, np.nan, 30],
"city": ["Bei Jing", "Shang Hai", "Guang Zhou", "Shen Zhen", np.nan, " "],
"sex": [None, "male", "female", "male", np.nan, "unknown"],
"birth": ["2000-02-10", "1988-10-17", None, "1978-08-08", np.nan, "1988-10-17"]
}
user_info = pd.DataFrame(data=data, index=index)
user_info["birth"] = pd.to_datetime(user_info.birth)
user_info
为什么要用str属性
文本数据也就是我们常说的字符串,Pandas 为 Series 提供了 str 属性,通过它可以方便的对每个元素进行操作。在之前已经了解过,在对 Series 中每个元素处理时,我们可以使用 map 或 apply 方法。
# 将每个城市都转为小写:
user_info.city.map(lambda x: x.lower())
What?竟然出错了,错误原因是因为 float 类型的对象没有 lower 属性。这是因为缺失值 (np.nan)属于float 类型
这时候我们的 str 属性操作来了,来看看如何使用吧
# 将文本转为小写
user_info.city.str.lower()
# 统计每个字符串的长度
user_info.city.str.len()
替换和分割
替换操作
# 将空字符串替换成下划线:
user_info.city.str.replace(" ", "_")
# 使用正则表达式将所有开头为 S 的城市替换为空字符串:
user_info.city.str.replace("^S.*", " ")
分割操作
# 根据空字符串来分割某一列:
user_info.city.str.split(" ")
"""
name
Tom [Bei, Jing]
Bob [Shang, Hai]
Mary [Guang, Zhou]
James [Shen, Zhen]
Andy NaN
Alice [, ]
Name: city, dtype: object
""" #分割列表中的元素可以使用 get 或 [] 符号进行访问:
user_info.city.str.split(" ").str.get(0)
"""
name
Tom Bei
Bob Shang
Mary Guang
James Shen
Andy NaN
Alice
Name: city, dtype: object
""" user_info.city.str.split(" ").str[1]
"""
name
Tom Jing
Bob Hai
Mary Zhou
James Zhen
Andy NaN
Alice
Name: city, dtype: object
""" # 设置参数 expand=True 可以轻松扩展此项以返回 DataFrame
user_info.city.str.split(" ", expand=True)
"""
0 1
name
Tom Bei Jing
Bob Shang Hai
Mary Guang Zhou
James Shen Zhen
Andy NaN NaN
Alice
"""
提取子串
从一个长的字符串中提取出子串。
提取第一个匹配的子串
extract 只能够匹配出第一个子串,extract 方法接受一个正则表达式并至少包含一个捕获组,指定参数 expand=True 可以保证每次都返回 DataFrame。
\s+ :一个或多个空字符串
(\w+):分组捕获任意多个字符
(\w+)\s+:在一个或多个空字符串前,分组捕获任意多个字符
# 匹配空字符串前面的所有的字母
user_info.city.str.extract("(\w+)\s+", expand=True)
"""
0
name
Tom Bei
Bob Shang
Mary Guang
James Shen
Andy NaN
Alice NaN
""" # 如果使用多个组提取正则表达式会返回一个 DataFrame,每个组只有一列。
# 匹配出空字符串前面和后面的所有字母
user_info.city.str.extract("(\w+)\s+(\w+)", expand=True)
"""
0 1
name
Tom Bei Jing
Bob Shang Hai
Mary Guang Zhou
James Shen Zhen
Andy NaN NaN
Alice NaN NaN
"""
匹配所有子串
extract 只能够匹配出第一个子串,使用 extractall 可以匹配出所有的子串。
# 将所有组的空白字符串前面的字母都匹配出来
user_info.city.str.extractall("(\w+)\s+")
"""
0
name match
Tom 0 Bei
Bob 0 Shang
Mary 0 Guang
James 0 Shen
"""
测试是否包含子串
使用 contains 来测试是否包含子串 --> 布尔值
# 测试城市是否包含子串 'Zh':
user_info.city.str.contains("Zh")
# 测试是否是以字母 'S' 开头:
user_info.city.str.contains("^S")
生成哑变量
这是一个神奇的功能,通过 get_dummies 方法可以将字符串转为哑变量, sep 参数是指定哑变量之间的分隔符
user_info.city.str.get_dummies(sep=" ")

方法摘要
| 方法 | 描述 |
| cat() | 连接字符串 |
| split() | 在分隔符上分割字符串 |
| rsplit() | 从字符串末尾开始分隔字符串 |
| get() | 索引到每个元素(检索第i个元素) |
| join() | 使用分隔符在系列的每个元素中加入字符串 |
| get_dummies() | 在分隔符上分割字符串,返回虚拟变量的DataFrame |
| contains() | 如果每个字符串都包含pattern / regex,则返回布尔数组 |
| replace() | 用其他字符串替换pattern / regex的出现 |
| repeat() ) | 重复值(s.str.repeat(3)等同于x * 3 t2 ) |
| pad() | 将空格添加到字符串的左侧,右侧或两侧 |
| center() | 相当于str.center |
| ljust() | 相当于str.ljust |
| rjust() | 相当于str.rjust |
| zfill() | 等同于str.zfill |
| wrap() | 将长长的字符串拆分为长度小于给定宽度的行 |
| slice() | 切分Series中的每个字符串 |
| slice_replace() | 用传递的值替换每个字符串中的切片 |
| count() | 计数模式的发生 |
| startswith() | 相当于每个元素的str.startswith(pat) |
| endswith() | 相当于每个元素的str.endswith(pat) |
| findall() | 计算每个字符串的所有模式/正则表达式的列表 |
| match() | 在每个元素上调用re.match,返回匹配的组作为列表 |
| extract() | 在每个元素上调用re.search,为每个元素返回一行DataFrame,为每个正则表达式捕获组返回一列 |
| extractall() | 在每个元素上调用re.findall,为每个匹配返回一行DataFrame,为每个正则表达式捕获组返回一列 |
| len() | 计算字符串长度 |
| normalize() | 返回Unicode标准格式。相当于unicodedata.normalize |
最新文章
- 浅谈Android样式开发之布局优化
- ubuntu14.04 下emacs 24 配置
- linux 新建文件的命令
- 修改FreeBSD启动菜单停留时间
- [Js]面向对象的拖拽
- iOS自定义UICollectionViewLayout之瀑布流
- 【转】android-support-v7-appcompat.jar 的安装及相关问题解决 --- 汇总整理
- APNs改动 (转)
- Linux中Samba详细安装
- C 语言实现字符串替换
- 迎圣诞,拿大奖活动赛题_SQLi(sprintf格式化字符)
- Spring Boot 2.x基础教程:快速入门
- 启动Cognos时报0106错误
- python中$和@基础笔记
- High-level structure of a simple compiler高級結構的簡單編譯器
- mysql主从复制-读写分离
- xenserver开启虚拟机时提示找不到存储介质,强制关闭和重启都没用
- Reloading Java Classes 101: Objects, Classes and ClassLoaders Translation
- Maven镜像收集
- SQL语句常见优化十大案例