写时复制和fork,vfork,clone
写时复制
原理:
用了“引用计数”,会有一个变量用于保存引用的数量。当第一个类构造时,string的构造函数会根据传入的参数从堆上分配内存,当有其它类需要这块内存时,这个计数为自动累加,当有类析构时,这个计数会减一,直到最后一个类析构时,此时的引用计数为1或是0,此时,程序才会真正的Free这块从堆上分配的内存。引用计数就是string类中写时才拷贝的原理!
共享同一块内存的类发生内容改变时,才会发生Copy On Write(写时复制)。比如string类的[]、=、+=、+等,还有一些string类中诸如insert、replace、append等成员函数等,包括类的析构时。
父进程和子进程共享页面而不是复制页面。然而,只要页面被共享,它们就不能被修改。无论父进程和子进程何时试图写一个共享的页面,就产生一个错误,这时内核就把这个页复制到一个新的页面中并标记为可写。原来的页面仍然是写保护的:当其它进程试图写入时,内核检查写进程是否是这个页面的唯一属主;如果是,它把这个页面标记为对这个进程是可写的。
写时拷贝
在复制一个对象的时候并不是真正的把原先的对象复制到内存的另外一个位置上,而是在新对象的内存映射表中设置一个指针,指向源对象的位置,并把那块内存的Copy-On-Write位设置为1.
这样,在对新的对象执行读操作的时候,内存数据不发生任何变动,直接执行读操作;而在对新的对象执行写操作时,将真正的对象复制到新的内存地址中,并修改新对象的内存映射表指向这个新的位置,并在新的内存位置上执行写操作。
这个技术需要跟虚拟内存和分页同时使用,好处就是在执行复制操作时因为不是真正的内存复制,而只是建立了一个指针,因而大大提高效率。但这不是一直成立的,如果在复制新对象之后,大部分对象都还需要继续进行写操作会产生大量的分页错误,得不偿失。所以COW高效的情况只是在复制新对象之后,在一小部分的内存分页上进行写操作。
fork
一个进程,是包括代码、数据和分配给进程的资源,fork()包含的头文件<sys/types.h>和<unistd.h>,fork()函数通过系统调用创建一个与原来进程几乎完全相同的进程,也就两个进程可以完全做相同的事,但如果初始化参数或者传入的变量不同,两个进程也可以做不同的事。一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的进程中,只有少数值与原来发的进程的值不同,相当于克隆了一个自己
在fork()之后exec之前两个进程用的是相同的物理空间(内存区),先把页表映射关系建立起来,并不真正将内存拷贝。子进程的代码段、数据段、堆栈都是指向父进程的物理空间,也就是说,两者的虚拟空间不同,但其对应的物理空间是同一个。当父进程中有更改相应段的行为发生时,如进程写访问,再为子进程相应的段分配物理空间,如果不是因为exec,内核会给子进程的数据段、堆栈段分配相应的物理空间(至此两者有各自的进程空间,互不影响),而代码段继续共享父进程的物理空间(两者的代码完全相同)。而如果是因为exec,由于两者执行的代码不同,子进程的代码段也会分配单独的物理空间。fork时子进程获得父进程数据空间、堆和栈的复制所以变量的地址(当然是虚拟地址)是一样的。
但实际上,linux为了提高fork的效率,采用了copy-on-write技术,fork后,这两个虚拟地址实际上指向相同的物理地址。(内存页),只有任何一个进程试图修改这个虚拟地址里的内容前(而当子进程改变了父进程的变量时候,会通过copy_on_write的手段为所涉及的页面建立一个新的副本),两个虚拟地址才会指向不同的物理地址。新的物理地址的内容从源物理地址中复制得到。
原理:
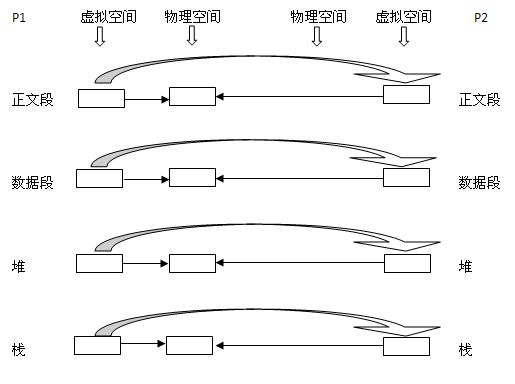
现在有一个父进程P1,这是一个主体,那么它是有灵魂也就身体的。现在在其虚拟地址空间(有相应的数据结构表示)上有:正文段,数据段,堆,栈这四个部 分,相应的,内核要为这四个部分分配各自的物理块。即:正文段块,数据段块,堆块,栈块。至于如何分配,这是内核去做的事
1. 现在P1用fork()函数为进程创建一个子进程P2,
内核:
(1)复制P1的正文段,数据段,堆,栈这四个部分,注意是其内容相同。
(2)为这四个部分分配物理块,P2的:正文段->PI的正文段的物理块,其实就是不为P2分配正文段块,让P2的正文段指向P1的正文段块,数据段->P2自己的数据段块(为其分配对应的块),堆->P2自己的堆块,栈->P2自己的栈块。如下图所示:同左到右大的方向箭头表示复制内容。

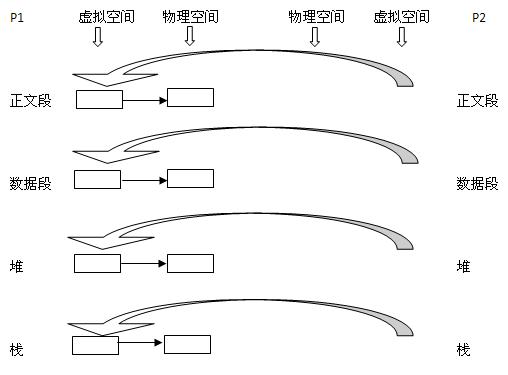
2. 写时复制技术:内核只为新生成的子进程创建虚拟空间结构,它们来复制于父进程的虚拟究竟结构,但是不为这些段分配物理内存,它们共享父进程的物理空间,当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间。
fork采用了这种写时复制的机制,那么fork出来子进程后,理论上子进程和父进程那个先调度呢?
fork之后内核一般会通过将子进程放在队列的前面,以让子进程先执行,因为很多情况下子进程要马上执行exec,会清空栈、堆,这些和父进程共享的空间,加载新的代码段。。这就避免了父进程“写时复制”拷贝共享页面的机会。如果父进程先调度很可能写共享页面,而子进程什么也没做,会产生“写时复制”的无用功。所以,一般子进程先调度。避免因无意义的复制而造成效率的下降。而事实上同步执行不分先后
它仅仅被调用一次,却能能够返回两次,它可能有三种不同的返回值。如果创建成功一个子进程,对于父进程来说是返回子进程的ID.而对于子进程来说就是返回0.而返回-1代表创建子进程失败.

如fork执行成功。fork返回新创建子进程的进程ID。在子进程中,fork返回0,所以可以通过返回值来判断当前是子进程还是父进程
如fork执行失败。1)当前的进程数已经达到了系统规定的上限,这时errno的值被设置为EAGAIN。
2)系统内存不足,这时errno的值被设置为ENOMEM。
父进程和子进程哪个进程先执行要看系统的进程调度策略
#include <sys/types.h>
#include <unistd.h>
#include <stdio.h>
#include <signal.h>
#include <errno.h>
int main(void)
{
pid_t pid ;
signal(SIGCHLD,SIG_IGN);
printf("before fork pid:%d\n",getpid());
;
pid = fork();
) //错误返回
{
perror("tile");
;
}
) //父进程空间
{
abc++;
printf("parent:pid:%d \n",getpid());
printf("abc:%d \n",abc);
sleep();
}
)
{ //子进程空间
abc++;
printf("child:%d,parent: %d\n",getpid(),getppid());
printf("abc:%d",abc);
}
printf("fork after...\n");
}
总结:
1)fork系统调用之后,父进程和子进程交替执行,并且它们处于不同空间中。
int main()
{
int pid;
;
pid=fork();
)
{
num++;
printf("in parent:num:%d addr:%x\n",num,&num);
}
)
{
printf("in child:num:%d addr:%x\n",num,&num);
}
}
答案:父子进程中输出的num不同,num地址相同
虚拟地址空间,num地址的值相同,但是其实真实的物理地址却不一样。
如果安装两个进程各处在独自的虚拟进程地址空间分析的话,这个题很容易会选择num地址不相同,但是Linux中资源分配都是虚拟机制,也就是说,他们还是共用一个虚拟的地址,但是映射到物理内存就可能不一样
2)fork()函数的一次调用返回2次返回,这个有点抽象难理解,此时二个进程处于独立的空间,它们各自执行者自己的东西,不产生冲突,所以返回2次一次pid ==0,一次pid大于0.而至于是先子进程还是父进程先执行,这没有确切的规定,是随机的.
3)将fork()返回值大于零设置为父进程,这是因为子进程获得父进程的pid(getppid())相对容易,而父进程获子进程pid叫难,所以在在fork()系统调用中将子进程的pid字节有它自己返回给父进程.
4)forl()的子执行过程在fork()之后并不是从头开始,因为在fork()之前,父进程已经为子进程搭建好了运行环境了.所以从fork()下一条语句开始。
vfork
内核连子进程的虚拟地址空间结构也不创建了,直接共享了父进程的虚拟空间,当然了,这种做法就顺水推舟的共享了父进程的物理空间
vfork也是创建一个子进程,不拷贝父进程的页表项。子进程作为父进程的一个单独的线程在它的地址空间里运行,子父进程共享数据段,父进程被阻塞,直到子进程退出或执行exec。子进程不能向地址空间写入。但是子进程共享父进程的空间。在vfork创建子进程之后,父进程阻塞,直到子进程执行了exec()或者exit()。vfork最初是因为fork没有实现COW机制,而很多情况下fork之后会紧接着exec,而exec的执行相当于之前fork复制的空间全部变成了无用功,所以设计了vfork。而现在fork使用了COW机制,唯一的代价仅仅是复制父进程页表的代价,所以vfork不应该出现在新的代码之中。
- vfork创建出来的不是真正意义上的进程,而是一个线程,因为它缺少经常要素有独立的存储空间
- 由vfork创建的子进程要先于父进程执行,子进程执行时,父进程处于挂起状态,子进程执行完,唤醒父进程。除非子进程exit或者execve才会唤起父进程
- 用vfork()创建的子进程必须显示调用exit()来结束,否则子进程将不能结束,而fork()则不存在这个情况。
- vfork的好处是在子进程被创建后往往仅仅是为了调用exec执行另一个程序,因为它就不会对父进程的地址空间有任何引用,所以对地址空间的复制是多余的 ,因此通过vfork共享内存可以减少不必要的开销。
clone
clone是Linux为创建线程设计的(虽然也可以用clone创建进程)。所以可以说clone是fork的升级版本,不仅可以创建进程或者线程,还可以指定创建新的命名空间(namespace)、有选择的继承父进程的内存、甚至可以将创建出来的进程变成父进程的兄弟进程等等。
clone函数功能强大,带了众多参数,它提供了一个非常灵活自由的常见进程的方法。因此由他创建的进程要比前面2种方法要复杂。clone可以让你有选择性的继承父进程的资源,你可以选择想vfork一样和父进程共享一个虚存空间,从而使创造的是线程,你也可以不和父进程共享,你甚至可以选择创造出来的进程和父进程不再是父子关系,而是兄弟关系
int clone(int (*fn)(void *), void *child_stack, int flags, void *arg);
- fn为函数指针,此指针指向一个函数体,即想要创建进程的静态程序(我们知道进程的4要素,这个就是指向程序的指针,就是所谓的“剧本", );
- child_stack为给子进程分配系统堆栈的指针(在linux下系统堆栈空间是2页面,就是8K的内存,其中在这块内存中,低地址上放入了值,这个值就是进程控制块task_struct的值);
- arg就是传给子进程的参数一般为(0);
- flags为要复制资源的标志,描述你需要从父进程继承那些资源(是资源复制还是共享,在这里设置参数:
下面是flags可以取的值
标志 含义
CLONE_PARENT 创建的子进程的父进程是调用者的父进程,新进程与创建它的进程成了“兄弟”而不是“父子”
CLONE_FS 子进程与父进程共享相同的文件系统,包括root、当前目录、umask
CLONE_FILES 子进程与父进程共享相同的文件描述符(file descriptor)表
CLONE_NEWNS 在新的namespace启动子进程,namespace描述了进程的文件hierarchy
CLONE_SIGHAND 子进程与父进程共享相同的信号处理(signal handler)表
CLONE_PTRACE 若父进程被trace,子进程也被trace
CLONE_VFORK 父进程被挂起,直至子进程释放虚拟内存资源
CLONE_VM 子进程与父进程运行于相同的内存空间
CLONE_PID 子进程在创建时PID与父进程一致
CLONE_THREAD 创建的进程与调用进程共享虚拟地址空间,文件描述符和信号处理函数,这些都是线程的特点。
区别:
- fork不对父子进程的执行次序进行任何限制,fork返回后,子进程和父进程都从调用fork函数的下一条语句开始行,但父子进程运行顺序是不定的,它取决于内核的调度算法
- vfork调用中,子进程先运行,父进程挂起,直到子进程调用了exec或exit之后,父子进程的执行次序才不再有限制
- clone中由标志CLONE_VFORK来决定子进程在执行时父进程是阻塞还是运行,若没有设置该标志,则父子进程同时运行,设置了该标志,则父进程挂起,直到子进程结束为止。
clone和fork的调用方式很不相同,clone调用需要传入一个函数,该函数在子进程中执行。
clone和fork最大不同在于clone不再复制父进程的栈空间,而是自己创建一个新的。 (void *child_stack,)也就是第二个参数,需要分配栈指针的空间大小,所以它不再是继承或者复制,而是全新的创造。
最新文章
- [原创]Android应用 - YE启动器APP(YeLauncherApp)
- 【加密】RSA加密之算法
- 设置contentType
- [Bnuz OJ]1176 小秋与正方形
- Butter Knife使用详解
- virtuoso装载大的rdf文件的方法
- 从返回的HTTP Header信息中隐藏Apache的版本号及PHP的X-Powered-By信息
- [HNOI 2009]梦幻布丁
- Android初级教程Fragment到Fragment的通信初探
- jQuery ajax-param()
- usb驱动程序小结(六)
- HDU 5968(异或计算 暴力)
- ---- 关于Android蓝牙搜索到设备的图标显示和设备过滤
- Docker镜像存储-overlayfs
- php 添加环境变量
- cookie、locakstorage、sessionstorage的区别
- appium获取Toast内容的方法
- 激活Window和office工具
- jQuery事件处理(七)
- Ubuntu16.04安装印象笔记