码表的理解(ASCII,GBK,Unicode,UTF-8等)。
以下任何言论都完全是个人的理解,如有雷同纯属巧合,如有错误,希望大家多多指出,共同学习!谢谢!
笔者是一个理解能力偏慢、稍钻牛角尖的程序员,什么东西都要从最基础理解起,一步一步向上理解,因此讲述时也是这样,讲述的也比较通俗,都是按照个人的理解来讲述的,也请大家少安毋躁。
在计算机中无论任何数据的传输、存储、持久化,都是以二进制的形式体现的。
那么当我存一个字符的时候,计算机需要持久化到硬盘,或者保存在内存中。
这个时候保存在内存、硬盘的数据显然也是二进制的。
那么当我需要从硬盘、内存中取出这些字符,再显示的时候,为什么二进制会变成了字符呢?
这就是码表存在的意义。
码表其实就是一个字符和其对应的二进制相互映射的一张表。
这张表中规定了字符和二进制的映射关系。
计算机存储字符时将字符查询码表,然后存储对应的二进制。
计算机取出字符时将二进制查询码表,然后转换成对应的字符显示。
大致可以这样理解。
By the way
不同的码表所容纳的字符映射也是不同的。
在有些码表中一个字符占用1个字节,1个字节能表示的范围是-128到127,总共为256。所以能容纳256个字符映射。
而有的码表中一个字符占用2个,甚至3个字节,因此能容纳的字符映射也更多。
下面笔者按照自己的理解详细讲述一下不同的码表。
常见的码表:
ASCII:
美国码表,码表中只有英文大小写字母、数字、美式标点符号等。每个字符占用1个字节,所有字符映射的二进制都为正数,因此有128个字符映射关系。
GB2312:
兼容ASCII码表,并加入了中文字符,码表中包含英文大小写字母、数字、美式标点符号占一个字节,中文占两个字节,中文映射的二进制都是负数,因此有128× 128 = 16384个字符映射关系。
GBK/GB18030:
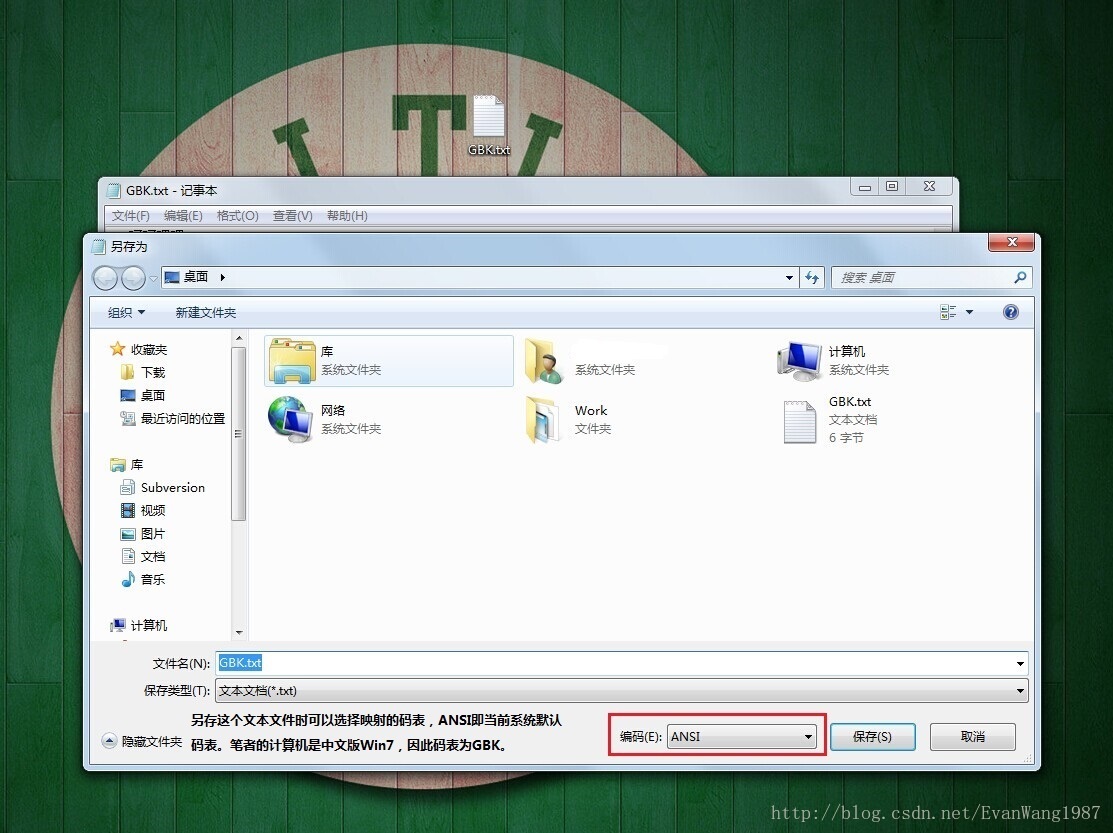
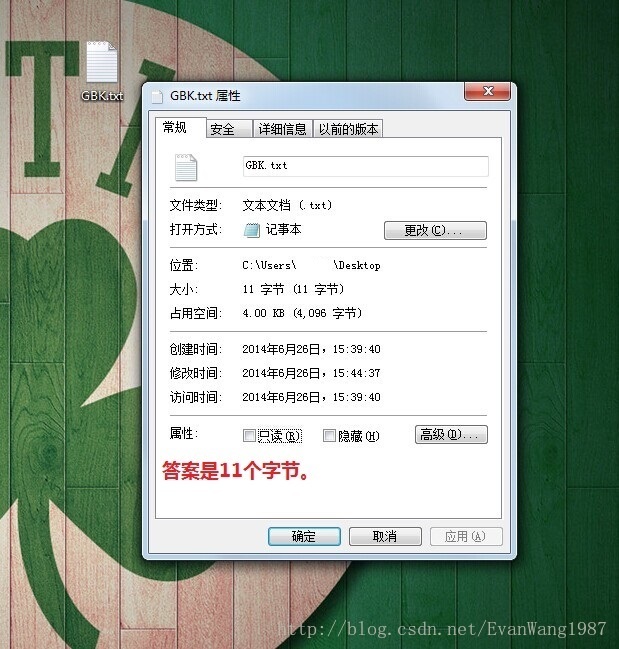
兼容GB2312码表,英文大小写字母、数字、美式标点符号,占一个字节。中文占两个字节,第一个字节为负数,第二个字节为正数和负数,因为有128× 256 = 32768个字符映射关系。
Unicode码表:
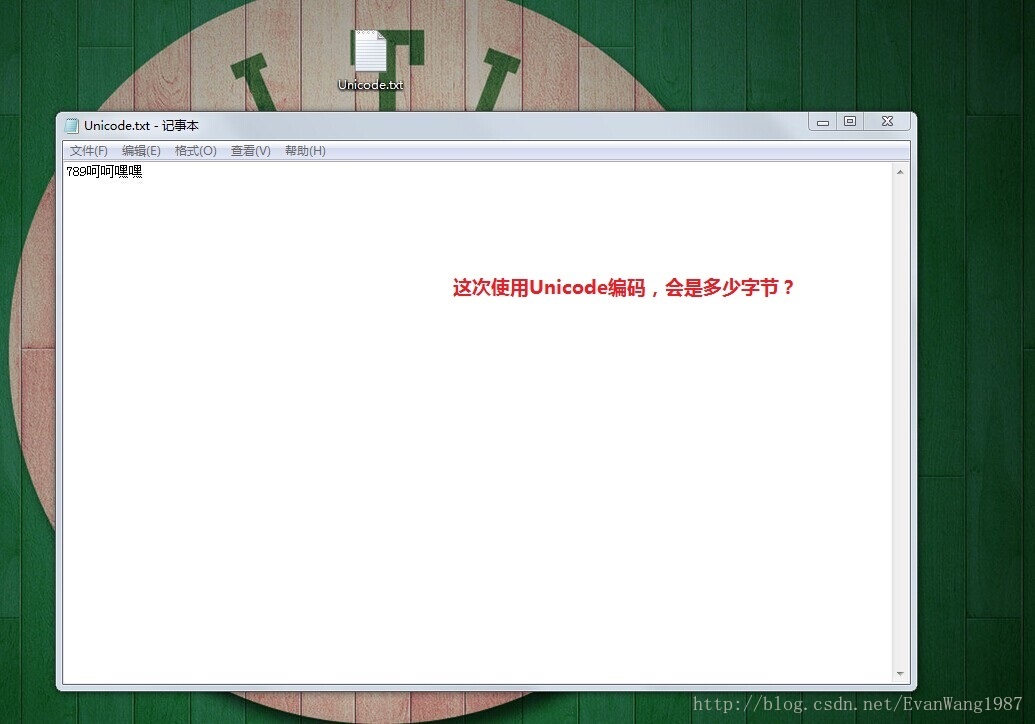
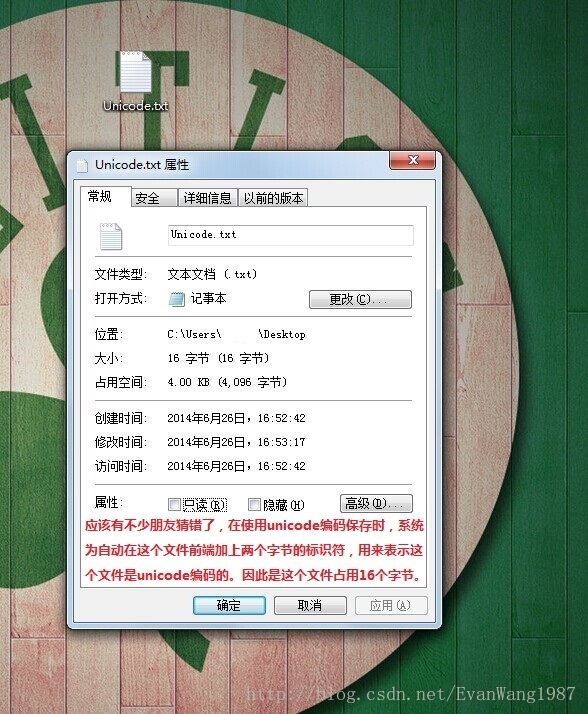
国际码表,包含各国大多数常用字符,没个字符都占2个字节,因此有65536个字符映射关系。Java语言使用的就是Unicode码表。
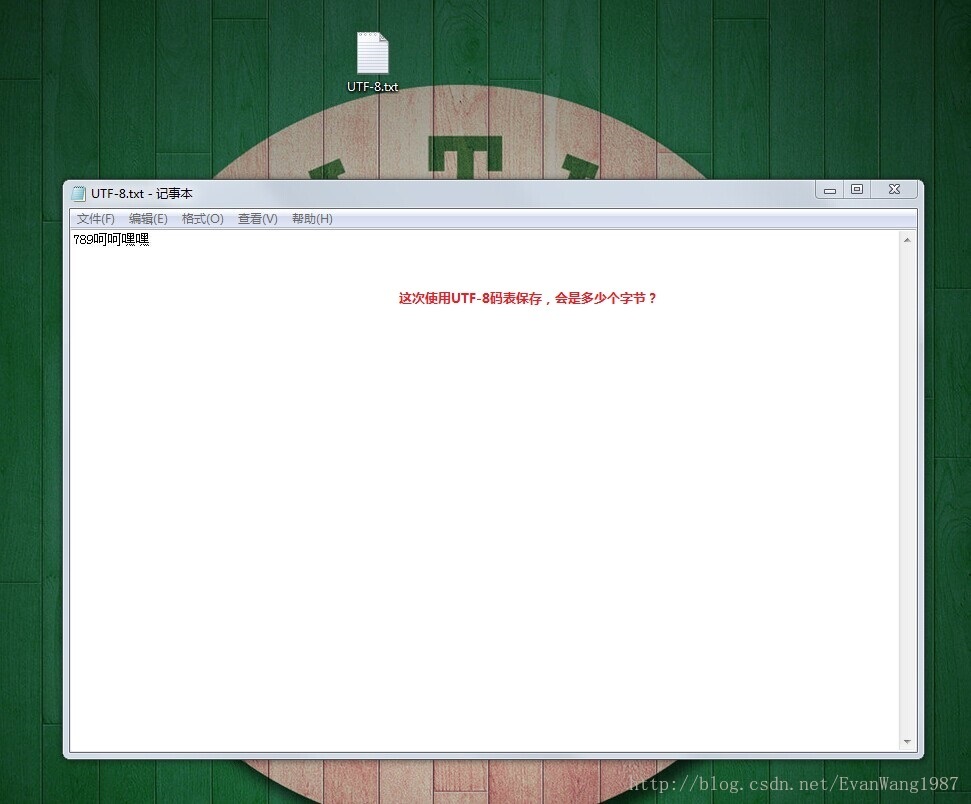
UTF-8码表:(是Unicode编码表的一种实现形式)
同样是国际码表,但英文占一个字节,中文占3个字节。
实际存储中看看具体的影响:


最新文章
- Unity3D移植到Windows phone8 遇到的点点滴滴
- SpringMVC单元测试之MockMVC,模拟登入用户
- 关于启用 HTTPS 的一些经验分享(一)
- js中各种跨域问题实战小结(二)
- logstash5.x配置
- 彻底弄懂css中单位px和em,rem的区别 转的自己看
- 推荐一个PHP在线代码运行的网站
- (剑指Offer)面试题28:字符串的排列
- LeetCode 343
- PHP自定义日期英文格式 Feb 11,2015
- JAVA如何解析多层json数据
- POJ-3278(BFS)
- Windows下Hadoop的环境安装[转]
- java对Microsoft Document的操作--->对Excel的操作
- zookeeper详解
- git使用教程之git分支
- 就这么 来ADO.net类操作数据库
- Confluence 6 性能优化
- linux中telnet后退出连接窗口的方法?
- 【面试】Python面试题库