Storm集群详细部署
1.安装zookeeper
3.1下载zookeeper安装包,
建议下载3.4.5及以上的版本
http://www.apache.org/dyn/closer.cgi/zookeeper/
3.2、下载完毕之后,解压文件
tar -zxvf zookeeper-3.4.7.tar.gz -C /export/servers/
cd /export/servers
ln -s zookeeper-3.4.7 zookeeper
修改配置文件
cd /export/servers/zookeeper/conf
mv zoo_sample.cfg zoo.cfg
vi zoo.cfg
输入以下内容:
|
#基本事件单元,以毫秒为单位。它用来控制心跳和超时,默认情况下最小的会话超时时间为两倍的 tickTime tickTime=2000 #此配置表示,允许 follower (相对于 leader 而言的“客户端”)连接并同步到 leader 的初始化连接时间,它以 tickTime 的倍数来表示。当超过设置倍数的 tickTime 时间,则连接失败 initLimit=10 #此配置表示, leader 与 follower 之间发送消息,请求和应答时间长度。如果 follower 在设置的时间内不能与 leader 进行通信,那么此 follower 将被丢弃 syncLimit=5 #数据目录. 可以是任意目录,其中的dataDir目录和dataLogDir需要提前建立好 #注意 应该谨慎地选择日志存放的位置,使用专用的日志存储设备能够大大地提高系统的性能,如果将日志存储在比较繁忙的存储设备上,那么将会在很大程度上影响系统的性能。 dataDir=/export/servers/data/zookeeper #log目录, 同样可以是任意目录. 如果没有设置该参数, 将使用和dataDir相同的设置,其中的dataDir目录和dataLogDir需要提前建立好 #注意 应该谨慎地选择日志存放的位置,使用专用的日志存储设备能够大大地提高系统的性能,如果将日志存储在比较繁忙的存储设备上,那么将会在很大程度上影响系统的性能。 dataLogDir=/export/servers/logs/zookeeper #监听client连接的端口号. clientPort=2181 #这个操作将限制连接到 ZooKeeper 的客户端的数量,限制并发连接的数量,它通过 IP 来区分不同的客户端。此配置选项可以用来阻止某些类别的 Dos 攻击。将它设置为 0 或者忽略而不进行设置将会取消对并发连接的限制。 maxClientCnxns=0 #最小的会话超时时间以及最大的会话超时时间。 #其中,最小的会话超时时间默认情况下为 2 倍的 tickTme 时间 #最大的会话超时时间默认情况下为 20 倍的会话超时时间 minSessionTimeout=4000 maxSessionTimeout=10000 #server.X=A:B:C 其中X是一个数字, 表示这是第几号server. A是该server所在的IP地址. B配置该server和集群中的leader交换消息所使用的端口. C配置选举leader时所使用的端口. #在之前设置的dataDir中新建myid文件, 写入一个数字, 该数字表示这是第几号server. 该数字必须和zoo.cfg文件中的server.X中的X一一对应. server.1=192.168.52.106:2888:3888 server.2=192.168.52.107:2888:3888 server.3=192.168.52.108:2888:3888 |
创建zk的数据目录和日志目录
mkdir -p /export/servers/data/zookeeper
mkdir -p /export/servers/logs/zookeeper
3.5、在数据目录下创建zk节点的编号
在上文中 /export/servers/data/zookeeper 的目录下,创建myid文件。
myid文件的内容,根据所属主机编号来编写。
解释:
创建数据目录,也就是在你zoo.cfg配置文件里dataDir指定的那个目录下创建myid文件,并且指定id,改id为你zoo.cfg文件中server.1=localhost:2887:3887中的1.只要在myid头部写入1即可.
3.6、分发修改后的安装文件
scp zookeeper-3.4.6 hadoop02:/export/servers/
scp zookeeper-3.4.6 hadoop03:/export/servers/
3.7、在分发后的机器上,执行步骤5的操作。
创建数据目录,也就是在你zoo.cfg配置文件里dataDir指定的那个目录下创建myid文件,并且指定id,改id为你zoo.cfg文件中server.1=localhost:2887:3887中的1.只要在myid头部写入1即可.
3.8、在所有 所有 所有机器上配置环境变量
#set ZK env
export ZK_HOME=/export/servers/zk
export PATH=${ZK_HOME}/bin:$PATH
3.9、在所有 所有 所有机器上让配置文件生效
source /etc/profile
3.10、启动zk集群
依次在不同的节点上,输入zkServers.sh start
出现错误后,可参考:http://maoxiangyi.cn/index.php/archives/121
3.11、查看zk集群的状态
依次在不同的节点上,输入zkServers.sh status
只有一个主节点,leader 其他都是follow
4、安装storm
4.1、下载安装包
4.2、解压安装包
tar -zxvf apache-storm-0.9.5.tar.gz -C /export/servers/
cd /export/servers/
ln -s apache-storm-0.9.5 storm
4.3、修改配置文件
mv /export/servers/storm/conf/storm.yaml /export/servers/storm/conf/storm.yaml.bak
vi /export/servers/storm/conf/storm.yaml
输入以下内容:
|
#指定storm使用的zk集群 storm.zookeeper.servers: - "zk01" - "zk02" - "zk03" #指定storm集群中的nimbus节点所在的服务器 nimbus.host: "storm01" #指定nimbus启动JVM最大可用内存大小 nimbus.childopts: "-Xmx1024m" #指定supervisor启动JVM最大可用内存大小 supervisor.childopts: "-Xmx1024m" #指定supervisor节点上,每个worker启动JVM最大可用内存大小 worker.childopts: "-Xmx768m" #指定ui启动JVM最大可用内存大小,ui服务一般与nimbus同在一个节点上。 ui.childopts: "-Xmx768m" #指定supervisor节点上,启动worker时对应的端口号,每个端口对应槽,每个槽位对应一个worker supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703 |
4.4、分发安装包
scp -r /export/servers/apache-storm-0.9.5 storm02:/export/servers
然后分别在各机器上创建软连接
cd /export/servers/
ln -s apache-storm-0.9.5 storm
4.5、启动集群
l 在nimbus.host所属的机器上启动 nimbus服务
cd /export/servers/storm/bin/
nohup ./storm nimbus &
l 在nimbus.host所属的机器上启动ui服务
cd /export/servers/storm/bin/
nohup ./storm ui &
l 在其它个点击上启动supervisor服务
cd /export/servers/storm/bin/
nohup ./storm supervisor &
4.6、查看集群
访问nimbus.host:/8080,即可看到storm的ui界面。
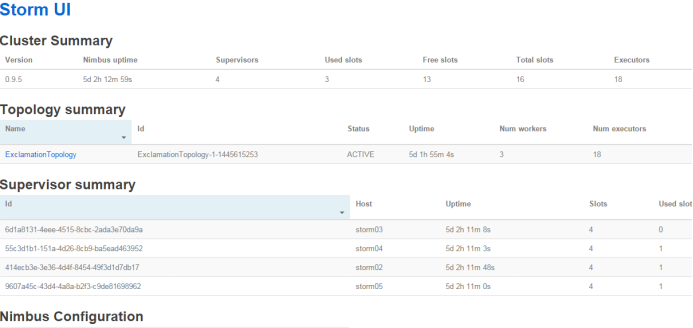
4.7、Storm常用操作命令
有许多简单且有用的命令可以用来管理拓扑,它们可以提交、杀死、禁用、再平衡拓扑。
l 提交任务命令格式:storm jar 【jar路径】 【拓扑包名.拓扑类名】 【拓扑名称】
bin/storm jar examples/storm-starter/storm-starter-topologies-0.10.0.jar storm.starter.WordCountTopology wordcount
l 杀死任务命令格式:storm kill 【拓扑名称】 -w 10(执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间)
storm kill topology-name -w 10
l 停用任务命令格式:storm deactivte 【拓扑名称】
storm deactivte topology-name
我们能够挂起或停用运行中的拓扑。当停用拓扑时,所有已分发的元组都会得到处理,但是spouts的nextTuple方法不会被调用。销毁一个拓扑,可以使用kill命令。它会以一种安全的方式销毁一个拓扑,首先停用拓扑,在等待拓扑消息的时间段内允许拓扑完成当前的数据流。
l 启用任务命令格式:storm activate【拓扑名称】
storm activate topology-name
l 重新部署任务命令格式:storm rebalance 【拓扑名称】
storm rebalance topology-name
再平衡使你重分配集群任务。这是个很强大的命令。比如,你向一个运行中的集群增加了节点。再平衡命令将会停用拓扑,然后在相应超时时间之后重分配工人,并重启拓扑。
最新文章
- iOS_XCode7_Launch Image 的初使用
- Android之webView入门
- linux 配置 wlan 连接
- Bitset位图
- Topology拓扑
- bzoj1965 [Ahoi2005]SHUFFLE 洗牌
- 对List对象按照某个成员变量进行排序
- maven中添加proguard来混淆代码
- python2和python3中的类
- ASM的备份集在文件系统上恢复测试
- Ubuntu 18.04.1 搭建Java环境和HelloWorld
- mybatis in查询 传入string
- 50道sql练习题和答案
- LA 4080 战争和物流(最短路树)
- JavaWeb基础—MVC与三层架构
- 拼图的几个网上找到的Demo
- uchome 全局变量
- Installshield 宏定义控制版本
- Afreechart很强大的图表库,支持股票曲线图,饼图,曲线
- mysql主从延时临时解决办法