The bytes/str dichotomy in Python 3 [transport]
reference and transporting from: http://eli.thegreenplace.net/2012/01/30/the-bytesstr-dichotomy-in-python-3/
Arguably the most significant new feature of Python 3 is a much cleaner separation between text and binary data. Text is always Unicode and is represented by the str type, and binary data is represented by the bytes type. What makes the separation particularly clean is that str and bytes can't be mixed in Python 3 in any implicit way. You can't concatenate them, look for one inside another, and generally pass one to a function that expects the other. This is a good thing.
However, boundaries between strings and bytes are inevitable, and this is where the following diagram is always important to keep in mind:
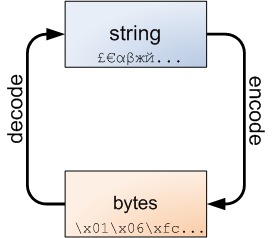
Strings can be encoded to bytes, and bytes can be decoded back to strings.
>>> '€20'.encode('utf-8')
b'\xe2\x82\xac20'
>>> b'\xe2\x82\xac20'.decode('utf-8')
'€20'
Think of it this way: a string is an abstract representation of text. A string consists of characters, which are also abstract entities not tied to any particular binary representation. When manipulating strings, we're living in blissful ignorance. We can split and slice them, concatenate and search inside them. We don't care how they are represented internally and how many bytes it takes to hold each character in them. We only start caring about this when encoding strings into bytes (for example, in order to send them over a communication channel), or decoding strings from bytes (for the other direction).
The argument given to encode and decode is the encoding (or codec). The encoding is a way to represent abstract characters in binary data. There are many possible encodings. UTF-8, shown above, is one. Here's another:
>>> '€20'.encode('iso-8859-15')
b'\xa420'
>>> b'\xa420'.decode('iso-8859-15')
'€20'
>>> '你好啊,傻傻分不清'.encode('utf-8')
b'\xe4\xbd\xa0\xe5\xa5\xbd\xe5\x95\x8a\xef\xbc\x8c\xe5\x82\xbb\xe5\x82\xbb\xe5\x88\x86\xe4\xb8\x8d\xe6\xb8\x85'
>>> b'\xe4\xbd\xa0\xe5\xa5\xbd\xe5\x95\x8a\xef\xbc\x8c\xe5\x82\xbb\xe5\x82\xbb\xe5\x88\x86\xe4\xb8\x8d\xe6\xb8\x85'.decode('utf-8')
'你好啊,傻傻分不清'
The encoding is a crucial part of this translation process. Without the encoding, the bytes object b'\xa420' is just a bunch of bits. The encoding gives it meaning. Using a different encoding, this bunch of bits can have a different meaning:
>>> b'\xa420'.decode('windows-1255')
'₪20'
That's 80% of the money lost due to using the wrong encoding, so be careful.
最新文章
- springmvc入门的第一个小例子
- window对象中的常见方法
- volley_之2
- 【javascript基础】3、变量和作用域
- 【WEB前端经验之谈】没有速成,只有不断积累。
- hdu 2041 超级楼梯
- Orthomcl的详细使用
- Node.js深受欢迎的六大原因
- 回溯(su)算法之N皇后问题
- iBeacon开发
- spring利用扫描方式对bean的处理(对任何版本如何获取xml配置信息的处理)
- java并发包——阻塞队列BlockingQueue及源码分析
- 关于 JavaScript 中的继承
- 标识符and数据类型
- SSH使用小记
- CentOS7下swap分区创建(添加),删除以及相关配置
- Oracle 导出的表不全,以及数据库版本不同导入报错
- Centos下MooseFS(MFS)分布式存储共享环境部署记录
- 猜字游戏java
- java注解的概念理解
热门文章
- 启动新内核出现:No filesystem could mount root, tried: ext3 ext2 cramfs vfa
- JAVA基础知识(12)-----同步
- css+div制作圆角矩形的四种方法
- 由hibernate配置inverse="true"而导致的软件错误,并分析解决此问题的过程
- centos6.x禁用ipv6的方法
- hadoop主节点(NameNode)备份策略以、恢复方法、操作步骤
- Win7环境下Sublime Text 3下安装NodeJS插件
- UVa 11020 Efficient Solutions (BST)
- vivado中如何调用chipscope或者impact
- vue 绑定属性(index)