Sqoop Import HDFS
2024-08-26 06:58:36
Sqoop import应用场景——密码访问
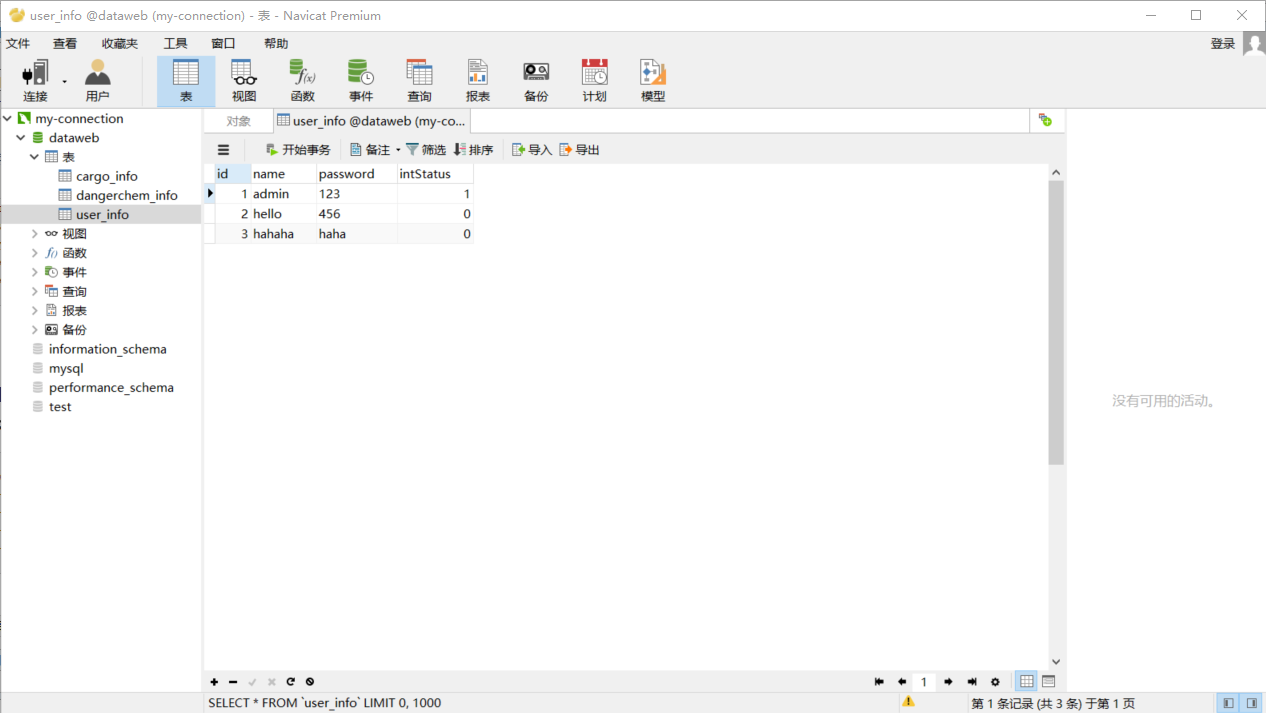
注:测试用表为本地数据库中的表
1.明码访问
sqoop list-databases \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--password
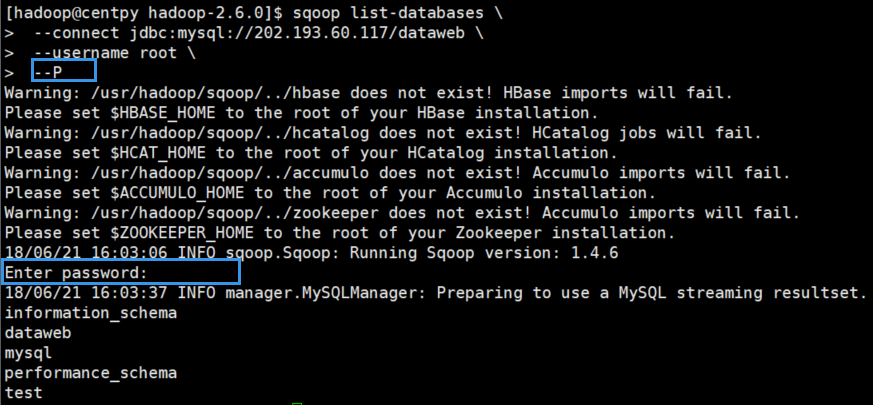
2.交互式密码
sqoop list-databases \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--P
3.文件授权密码
sqoop list-databases \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--password-file /usr/hadoop/.password
在运行之前先要在指定路径下创建.password文件。
[hadoop@centpy ~]$ cd /usr/hadoop/
[hadoop@centpy hadoop]$ ls
flume hadoop-2.6. sqoop
[hadoop@centpy hadoop]$ echo -n "20134997" > .password
[hadoop@centpy hadoop]$ ls -a
. .. flume hadoop-2.6. .password sqoop
[hadoop@centpy hadoop]$ more .password [hadoop@centpy hadoop]$ chmod 400 .password //根据官方文档说明赋予400权限
测试运行之后一定会报以下错误:
// :: WARN tool.BaseSqoopTool: Failed to load password file
java.io.IOException: The provided password file /usr/hadoop/.password does not exist!
at org.apache.sqoop.util.password.FilePasswordLoader.verifyPath(FilePasswordLoader.java:)
at org.apache.sqoop.util.password.FilePasswordLoader.loadPassword(FilePasswordLoader.java:)
at org.apache.sqoop.util.CredentialsUtil.fetchPasswordFromLoader(CredentialsUtil.java:)
at org.apache.sqoop.util.CredentialsUtil.fetchPassword(CredentialsUtil.java:)
at org.apache.sqoop.tool.BaseSqoopTool.applyCredentialsOptions(BaseSqoopTool.java:)
at org.apache.sqoop.tool.BaseSqoopTool.applyCommonOptions(BaseSqoopTool.java:)
at org.apache.sqoop.tool.ListDatabasesTool.applyOptions(ListDatabasesTool.java:)
at org.apache.sqoop.tool.SqoopTool.parseArguments(SqoopTool.java:)
at org.apache.sqoop.Sqoop.run(Sqoop.java:)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:)
at org.apache.sqoop.Sqoop.main(Sqoop.java:)
Error while loading password file: The provided password file /usr/hadoop/.password does not exist!
为了解决该错误,我们需要将.password文件放到HDFS上面去,这样就能找到该文件了。
[hadoop@centpy hadoop]$ hdfs dfs -ls /
Found items
drwxr-xr-x - Zimo supergroup -- : /actor
drwxr-xr-x - Zimo supergroup -- : /counter
drwxr-xr-x - hadoop supergroup -- : /flume
drwxr-xr-x - hadoop hadoop -- : /hdfsOutput
drwxr-xr-x - Zimo supergroup -- : /join
drwxr-xr-x - hadoop supergroup -- : /maven
drwxr-xr-x - Zimo supergroup -- : /mergeSmallFiles
drwxrwxrwx - hadoop supergroup -- : /phone
drwxr-xr-x - hadoop hadoop -- : /test
drwx------ - hadoop hadoop -- : /tmp
drwxr-xr-x - hadoop hadoop -- : /weather
drwxr-xr-x - hadoop hadoop -- : /weibo
[hadoop@centpy hadoop]$ hdfs dfs -mkdir -p /user/hadoop
[hadoop@centpy hadoop]$ hdfs dfs -put .password /user/hadoop
[hadoop@centpy hadoop]$ hdfs dfs -chmod 400 /user/hadoop/.password
现在测试运行一下,注意路径改为HDFS上的/user/hadoop。
[hadoop@centpy hadoop-2.6.]$ sqoop list-databases --connect jdbc:mysql://202.193.60.117/dataweb --username root --password-file /user/hadoop/.password
Warning: /usr/hadoop/sqoop/../hbase does not exist! HBase imports will fail.
Please set $HBASE_HOME to the root of your HBase installation.
Warning: /usr/hadoop/sqoop/../hcatalog does not exist! HCatalog jobs will fail.
Please set $HCAT_HOME to the root of your HCatalog installation.
Warning: /usr/hadoop/sqoop/../accumulo does not exist! Accumulo imports will fail.
Please set $ACCUMULO_HOME to the root of your Accumulo installation.
Warning: /usr/hadoop/sqoop/../zookeeper does not exist! Accumulo imports will fail.
Please set $ZOOKEEPER_HOME to the root of your Zookeeper installation.
// :: INFO sqoop.Sqoop: Running Sqoop version: 1.4.
// :: INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.
information_schema
dataweb
mysql
performance_schema
test
可以看到成功了。
Sqoop import应用场景——导入全表
1.不指定目录
sqoop import \
--connect jdbc:mysql://202.193.60.117/dataweb \
--username root \
--password-file /user/hadoop/.password \
--table user_info
运行过程如下
// :: INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:
// :: INFO db.DBInputFormat: Using read commited transaction isolation
// :: INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(`id`), MAX(`id`) FROM `user_info`
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1529567189245_0001
// :: INFO impl.YarnClientImpl: Submitted application application_1529567189245_0001
// :: INFO mapreduce.Job: The url to track the job: http://centpy:8088/proxy/application_1529567189245_0001/
// :: INFO mapreduce.Job: Running job: job_1529567189245_0001
// :: INFO mapreduce.Job: Job job_1529567189245_0001 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1529567189245_0001 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Other local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total vcore-seconds taken by all map tasks=
Total megabyte-seconds taken by all map tasks=
Map-Reduce Framework
Map input records=
Map output records=
Input split bytes=
Spilled Records=
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
// :: INFO mapreduce.ImportJobBase: Transferred bytes in 54.3141 seconds (0.8101 bytes/sec)
// :: INFO mapreduce.ImportJobBase: Retrieved records.
再查看一下HDFS下的运行结果

[hadoop@centpy hadoop-2.6.]$ hdfs dfs -cat /user/hadoop/user_info/part-m-*
,admin,,
,hello,,
,hahaha,haha,
运行结果和数据库内容匹配。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
最新文章
- C++Primer 第九章
- 20145338 《Java程序设计》第1周学习总结
- angualrjs学习总结二(作用域、控制器、过滤器)
- 【 随笔 】 JavaScript 图形库的流行度调查
- man命令
- 最近很火的携程Java 工程师的一道面向对象面试题
- Android小应用-----画画板
- C++ 中内存分配和回收
- ovs+dpdk numa感知特性验证
- 多少牛逼的程序员毁在low逼的英文发音上(JAVA)
- 【WPF开发备忘】使用MVVM模式开发中列表控件内的按钮事件无法触发解决方法
- P4777 【模板】扩展中国剩余定理(EXCRT)/ poj2891 Strange Way to Express Integers
- PowerDesigner V16.5 安装教程以及汉化(数据库建模)
- WebApi的调用-2.后台调用
- 【Java】 剑指offer(47) 礼物的最大价值
- php CI框架中URL特殊字符处理与SQL注入隐患
- 撤销commit
- OCP 062考试题库2019年新出现的考题-17
- Nginx server之Nginx添加ssl支持
- POJ 2371
热门文章
- Azure自动化部署服务 (1)
- 微服务理论之五:微服务架构 vs. SOA架构
- delphi 线程教学第一节:初识多线程
- 值得细细品读的URL资源
- 2、linux-compress and uncompresse
- EF Code first 和 DDD (领域驱动设计研究)系列一
- idea调试SpringMvc, 出现:”javax.servlet.ServletException: java.lang.IllegalStateException: Cannot create a session after the response has been committed"错误的解决方法
- Open-source Tutorial - Material Design for WPF UI
- 【leetcode 105. 从前序与中序遍历序列构造二叉树】解题报告
- .NET ToString() format格式化字符串(常用)