推荐系统学习(2)——基于TF-IDF的改进
2024-08-29 14:16:41
使用用户打标签次数*物品打标签次数做乘积的算法尽管简单。可是会造成热门物品推荐的情况。物品标签的权重是物品打过该标签的次数,用户标签的权重是用户使用过该标签的次数。从而导致个性化的推荐减少,而造成热门推荐。
运用TF-IDF的思想能够对算法进行改进。TF-IDF(term frequemcy-inverse documnet frequency)是一种用于资讯检索和文本挖掘的加权技术。用来评估一个词的重要程度。其主要思想是假设某个词或短语在一篇文章中出现的频率TF高,而且在其它文章中非常少出现,则觉得此词或者短语具有非常好的类别区分能力,适合用来分类。IDF是逆向文件频率,即包括某个term的文件越少。则IDF越大。
IDF能够由总文件数目除以包括该词语的文件的数目,然后取对数得到:
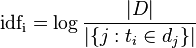
当中D代表文件的总数,分母代表包括该词语的文件的数目。为避免分母为0。通经常使用1+分母作为当前的分母。这样,当包括该词语的文件在总文件数量中所占比重非常小时,可以得到较大的TDF,从而可以得到较大的比重,有利于实现个性化的推荐。(可是引入的TDF却单纯的突出了小频率词汇的权重。从而又可能会给结果带来不好的影响)
则TF-TDF = TF * TDF就反映了一个词对于整个文档集的重要程度。
将TF-IDF应用到基于标签的推荐系统的算法中,则能够进行例如以下改进:

当中n(b)表示标签b被多少不同的用户所使用过。
同理,用n(i)表示物品i被多少个不同的用户打过标签。能够降低热门物品的权重。从而有效的避免热门物品的影响。

最新文章
- 【repost】js 常见错误类型
- XML:使用DOM技术解析xML文件中的城市,实现select级联选择
- Perl爬取江西失信执行
- org.apache.commons.lang.StringUtils中常用的方法
- 深入解析js中基本数据类型与引用类型,函数参数传递的区别
- [转]框架模式 MVC 在Android中的使用
- Winform开发框架主界面设计展示
- Java基本运算符
- 如何利用svn自动同步更新到网站服务器
- 字符串(多串后缀自动机):HDU 4436 str2int
- 测试库的接收到的数据是否完整(jrtplib为列)
- Excel提取字符串示例
- [swarthmore cs75] Lab 1 — OCaml Tree Programming
- SQL Server-执行计划教会我如何创建索引
- linux操作命令,批量注释#方法
- 强化学习论文(Scalable agent alignment via reward modeling: a research direction)
- mysql 可重复执行添加列
- 文件名命工具类(将指定目录下的文件的type类型的文件,进行重命名,命名后的文件将去掉type)
- MYSQL统计
- Linux添加或修改ssh端口