SqlServer中的UNION操作符在合并数据时去重的原理以及UNION运算符查询结果默认排序的问题
本文出处:http://www.cnblogs.com/wy123/p/7884986.html
周围又有人在讨论UNION和UNION ALL,对于UNION和UNION ALL,网上说的最多的就是性能问题(实在不想说出来这句话:UNION ALL比UNION快)
其实根本不想炒UNION和UNION ALL这碗剩饭了,
每次看到网上说用这个不用那个,列举的一条一条的那种文章,只要看到说UNION ALL比UNION性能好的就……
对于合并的结果集,UNION是去重的,UNION ALL是不去重的,去重与不去重是两个目的,分别由UNION和UNION ALL实现
两个作用(功能)不同的东西,放一起比性能有什么意义?
这种问题真的是无聊至极,就好比“足球场上的某个中后卫和某个前腰哪个能力更强”一样没有可比性,
他们的作用本身就是不同的,难道说中后卫能力不行,把他撤下来,用一个牛逼的前腰球员替代中后卫,或者是前腰能力不行,撤下他用牛逼的中后卫替代?
这是在功能上的区别,至于性能,我个人认为对比起来没有任何意义。
如果非要放一起比的话,做同样的数据合并,
UNION因为要去重,相对UNION ALL来说,(相对)当然会耗费更多的资源(耗费的资源多少跟性能无关,做的事情多,当然需要更多的资源)
但是一定要弄清楚,合并数据的时候,到底要不要去掉重复数据,这是最终结果对与错的问题,不是性能问题!
这里不讨论UNION和UNION ALL的性能了,
从另外一个点入手来发起问题
UNION与UNION ALL最大的区别就是UNION会去重,那么问题就来了,这个去重是怎么实现的?去重会对查询的默认顺序集产生什么影响?
UNION去重的实现
测试一下UNION运算符去重的实现原理
create table TestUnion1
( Id1 INT PRIMARY KEY,
Id2 tinyint,
Name varchar(100)
);
create table TestUnion2
(
Id1 INT PRIMARY KEY,
Id2 tinyint,
Name varchar(100)
); insert into TestUnion1 values (500,9,'aaa')
insert into TestUnion1 values (700,3,'ccc')
insert into TestUnion1 values (200,7,'eee') insert into TestUnion2 values (300,2,'bbb')
insert into TestUnion2 values (800,8,'ddd')
insert into TestUnion2 values (100,5,'fff') --TestUnionALL1和TestUnionALL2中相同的数据
insert into TestUnion1 values (600,6,'xxx')
insert into TestUnion2 values (600,6,'xxx')
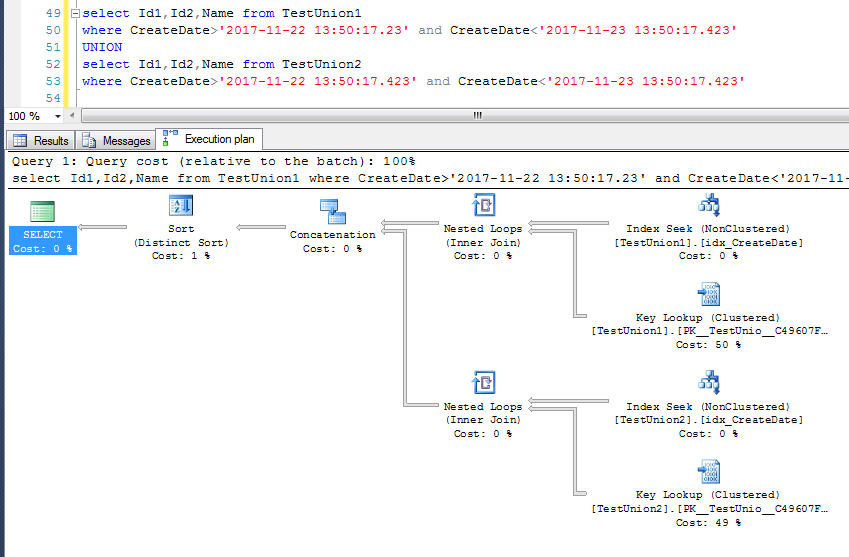
UNION在去重的过程中,使用的执行计划是Merge Join,UNION ALL是不去重的,同样步骤对应的执行计划是Concatenation
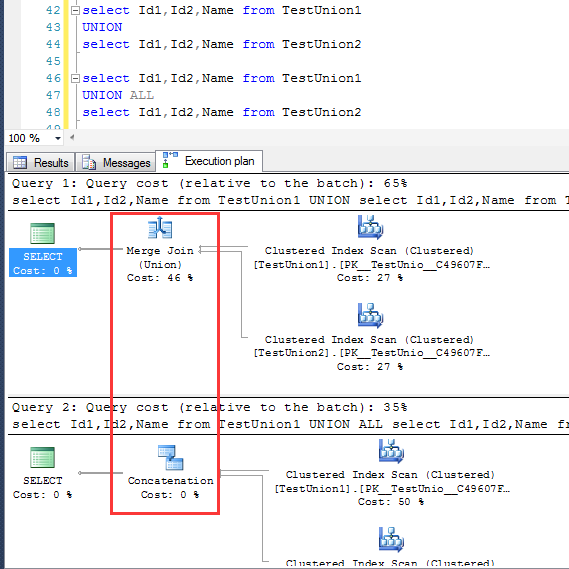
这里UNION的去重动作是通过merge实现,这里的merge join并不是表与表之间的merge join
这里可以看出来,UNION产生的merge与 inner join产生的Merge的作用是有差异的

对于UNION的去重的这一动作,去当然不是说只有merge join一种,这里只不过是两个结果的数据都刚好有序才采用merge join来去重罢了
如果查询字段的顺序的第一个字段是聚集索引(或者主键),,正如上文提到的,UNION的双方就会以merge的方式区中
如果查询字段的顺序非聚集索引,UNION的过程是现将两个结果集合并起来(上文提到的Concatenation),然后再做sort排序去重
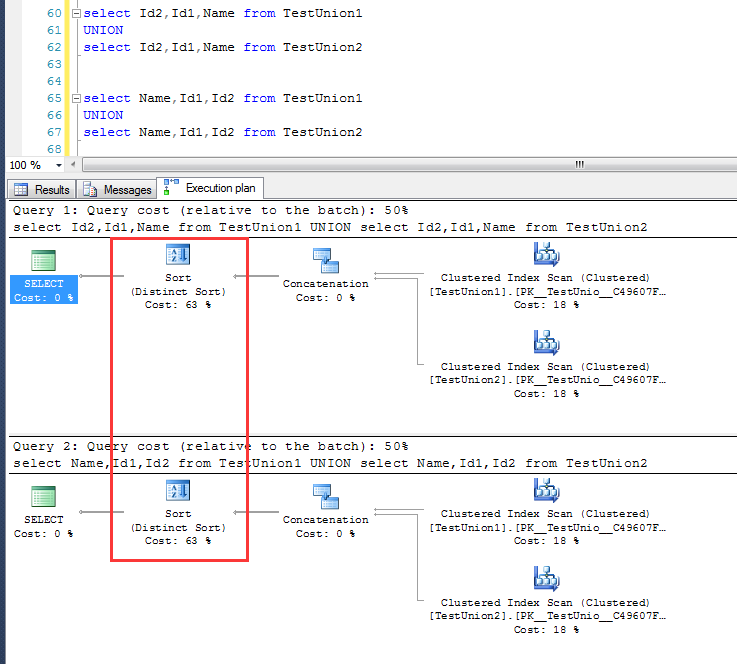
UNION之后结果集的最终排序结果
UNION之后结果集的最终排序结果跟查询字段的顺序有关,
如果查询字段的顺序的第一个字段是聚集索引(或者主键),正如上文提到的,UNION的双方就会以merge的方式区中
如果查询字段的顺序的第一个字段是非聚集索引字段,UNION的过程是现将两个结果集合并起来(上文提到的Concatenation),然后再做sort排序去重
如下的实例能说说明这个问题,当查询字段的顺序发生变化之后,两者的执行计划完全不一致。
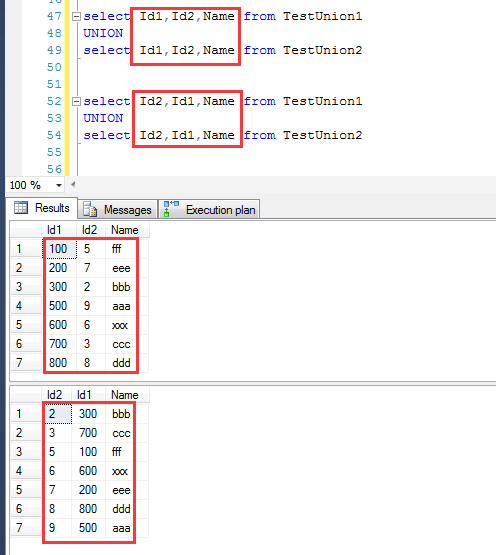

或者再看一个case,当Name在最前面的时候,最终的结果就是按照name排序。
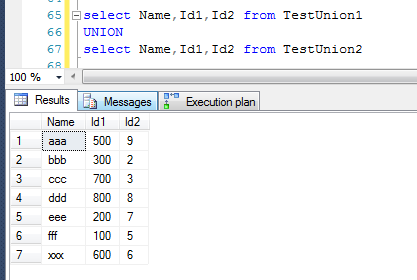
可能有人会怀疑是不是数据量太小了,是不是巧合,这里可以加大测试数据库,在查询条件中,让非聚集索引参与到运算之中
create table TestUnion1
( Id1 INT PRIMARY KEY,
Id2 tinyint,
Name varchar(100),
CreateDate datetime
); create table TestUnion2
(
Id1 INT PRIMARY KEY,
Id2 tinyint,
Name varchar(100),
CreateDate datetime
); begin tran
declare @i int = 0
while @i<1000000
begin
insert into TestUnion1 values (@i,rand()*200,newid(),getdate()-rand()*1000)
insert into TestUnion2 values (@i,rand()*200,newid(),getdate()-rand()*1000)
set @i=@i+1
end
commit create index idx_CreateDate on TestUnion1(CreateDate)
create index idx_CreateDate on TestUnion2(CreateDate)
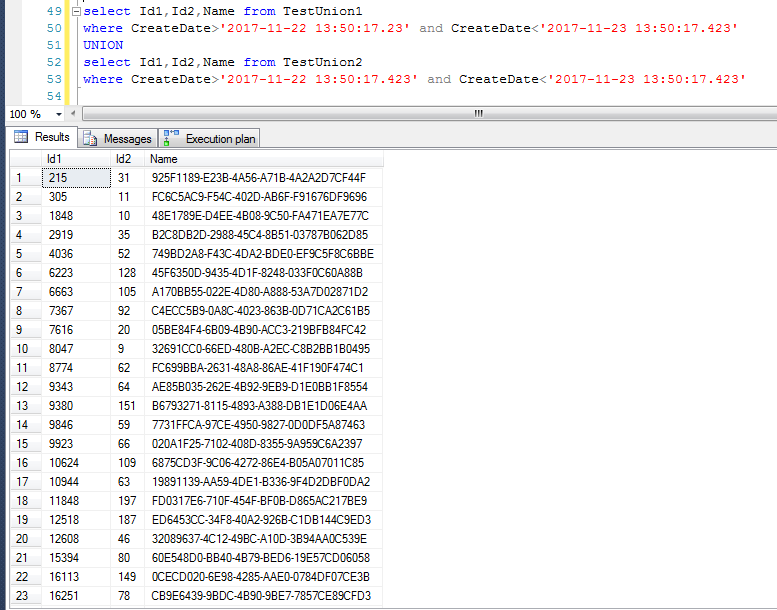
参考下图,一旦查询结果集不是按照查询字段聚集索引排序的话,
比如这里走的是createDate时间字段的索引,执行计划都是先按照普通的方式合并结果集,也即Concatenation
然后在利用Sort(Distinct)的方式排序去重,对于去重的结果的最终的排序,跟查询结果的第一个字段有关,且结果总是按照查询的第一个字段排序的。
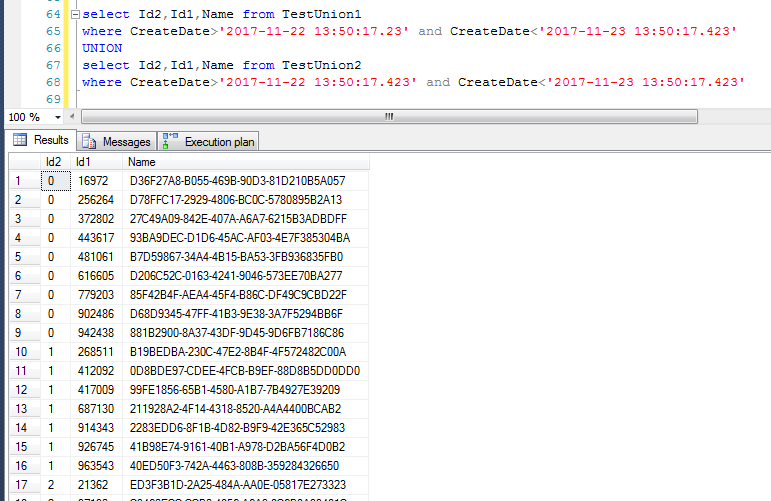
换一种查询字段的顺序方式,看一下结果,仍旧是按照查序列的第一个字段排序的
UNION运算符在去重的时候,
如果查询字段的第一个字段是聚集索引,那么会用merge join的方式合并+去重。
如果查询字段的第一个字段不是非聚集索引,那么首先会将两个(或者多个)结果集进行普通的合并,最后通过Sort Distinct的方式去重。
且UNION运算之后的默认排序方式,受查询字段前后的方式影响。
总结:
UNION和UNION ALL的作用是不一样的,放在一起比性能没有任何意义,真不想趟这趟浑水。
合并结果集,需要去重就用UNION,不需要去重就用UNION ALL,如果两个结果集中没有重复的结果集,就用UNION ALL,
这纯粹是需求驱动的,而不是UNION和UNION ALL的性能问题。
多撤一句:
曾经大晚上接到一个面试电话,没有任何开场白,第一句话是“我们电话面试一下可以吗”,答曰可以,第二句话就是“UNION和UNION ALL的区别是什么,有没有性能差异”。
真的不希望再去对UNION和UNION ALL的性能上做讨论。
最新文章
- opengles 矩阵计算
- MVC中处理表单提交的方式(使用html扩展方法+juqery插件)
- 事件(event),正则
- c# bass入门学习
- IOS网络开发(三)
- 【循序渐进学Python】7.面向对象的核心——类型(上)
- Android R文件相关问题
- SPRING IN ACTION 第4版笔记-第四章ASPECT-ORIENTED SPRING-011-注入AspectJ Aspect
- Niagara AX之BajaScript资料哪里找
- BZOJ 3402: [Usaco2009 Open]Hide and Seek 捉迷藏
- kuryr环境搭建
- jquery选择器 看这个链接吧!2017.6.2
- windows密码策略
- odoo开发笔记 -- 日常开发注意点小节
- 长按listview弹出选项列表对话框
- mysql中concat 和 group_concat()的用法
- Oil Deposits(poj 1526 DFS入门题)
- Ionic构建打包apk出现的问题集合
- 解析html文档的java库及范例
- HDU1232——畅通工程