Quratz的理解
一:公共术语
1.为什么使用Qurztz
在某一个有规律的时间点干某件事。并且时间的触发的条件可以非常复杂(比如每月最后一个工作日的17:50),复杂到需要一个专门的框架来干这个事。
Quartz就是来干这样的事,你给它一个触发条件的定义,它负责到了时间点,触发相应的Job起来干活
2.Qurztz三要素
- Scheduler:调度器。所有的调度都是由它控制。
- Trigger: 定义触发的条件。在上一篇的例子中,它的类型是SimpleTrigger,以及
- JobDetail & Job: JobDetail 定义的是任务数据,而真正的执行逻辑是在Job中。 为什么设计成JobDetail + Job,不直接使用Job?这是因为任务是有可能并发执行,如果Scheduler直接使用Job,就会存在对同一个Job实例并发访问的问题。而JobDetail & Job 方式,sheduler每次执行,都会根据JobDetail创建一个新的Job实例,这样就可以规避并发访问的问题。
3.API
在Quartz的API的风格在2.x以后,采用的是DSL风格(通常意味着fluent interface风格)
DSL风格写起来会更加连贯,畅快,而且由于不是使用setter的风格,语义上会更容易理解一些。
4.关于name和group
JobDetail和Trigger都有name和group。
name是它们在这个sheduler里面的唯一标识。如果我们要更新一个JobDetail定义,只需要设置一个name相同的JobDetail实例即可。
group是一个组织单元,sheduler会提供一些对整组操作的API,比如 scheduler.resumeJobs()。
二:Trigger
1.StartTime & EndTime
startTime和endTime指定的Trigger会被触发的时间区间。在这个区间之外,Trigger是不会被触发的。
所有Trigger都会包含这两个属性
2.优先级
当scheduler比较繁忙的时候,可能在同一个时刻,有多个Trigger被触发了,但资源不足(比如线程池不足)。那么这个时候比剪刀石头布更好的方式,就是设置优先级。优先级高的先执行。
需要注意的是,优先级只有在同一时刻执行的Trigger之间才会起作用,如果一个Trigger是9:00,另一个Trigger是9:30。那么无论后一个优先级多高,前一个都是先执行。
优先级的值默认是5,当为负数时使用默认值。最大值似乎没有指定,但建议遵循Java的标准,使用1-10,不然,上头还有没有更大的值。
3.Misfire(错失触发)策略
类似的Scheduler资源不足的时候,或者机器崩溃重启等,有可能某一些Trigger在应该触发的时间点没有被触发,也就是Miss Fire了。这个时候Trigger需要一个策略来处理这种情况。每种Trigger可选的策略各不相同。
MisFire的触发是有一个阀值,这个阀值是配置在JobStore的。比RAMJobStore是org.quartz.jobStore.misfireThreshold。只有超过这个阀值,才会算MisFire。小于这个阀值,Quartz是会全部重新触发。
这里有很多策略,这里主要说术语,就不具体说明了。
4.Calendar
这里的Calendar不是jdk的java.util.Calendar,不是为了计算日期的。它的作用是在于补充Trigger的时间。可以排除或加入某一些特定的时间点。
注意,所有的Calendar既可以是排除,也可以是包含。
- HolidayCalendar。指定特定的日期,比如20140613。精度到天。
- DailyCalendar。指定每天的时间段(rangeStartingTime, rangeEndingTime),格式是HH:MM[:SS[:mmm]]。也就是最大精度可以到毫秒。
- WeeklyCalendar。指定每星期的星期几,可选值比如为java.util.Calendar.SUNDAY。精度是天。
- MonthlyCalendar。指定每月的几号。可选值为1-31。精度是天
- AnnualCalendar。 指定每年的哪一天。使用方式如上例。精度是天。
- CronCalendar。指定Cron表达式。精度取决于Cron表达式,也就是最大精度可以到秒。
示例:
AnnualCalendar cal = new AnnualCalendar(); //定义一个每年执行Calendar,精度为天,即不能定义到2.25号下午2:00
java.util.Calendar excludeDay = new GregorianCalendar();
excludeDay.setTime(newDate().inMonthOnDay(2, 25).build());
cal.setDayExcluded(excludeDay, true); //设置排除2.25这个日期
scheduler.addCalendar("FebCal", cal, false, false); //scheduler加入这个Calendar //定义一个Trigger
Trigger trigger = newTrigger().withIdentity("trigger1", "group1")
.startNow()//一旦加入scheduler,立即生效
.modifiedByCalendar("FebCal") //使用Calendar !!
.withSchedule(simpleSchedule()
.withIntervalInSeconds(1)
.repeatForever())
.build();
5.实现类
SimpleTrigger
CalendarIntervalTrigger
DailyTimeIntervalTrigger
CronTrigger
6.SimpleTrigger
指定从某一个时间开始,以一定的时间间隔(单位是毫秒)执行的任务。
它适合的任务类似于:9:00 开始,每隔1小时,执行一次。
它的属性有:
- repeatInterval 重复间隔
- repeatCount 重复次数。实际执行次数是 repeatCount+1。因为在startTime的时候一定会执行一次。
simpleSchedule()
.withIntervalInHours(1) //每小时执行一次
.repeatForever() //次数不限
.build(); simpleSchedule()
.withIntervalInMinutes(1) //每分钟执行一次
.withRepeatCount(10) //次数为10次
.build();
7.CalendarIntervalTrigger
类似于SimpleTrigger,指定从某一个时间开始,以一定的时间间隔执行的任务。 但是不同的是SimpleTrigger指定的时间间隔为毫秒,没办法指定每隔一个月执行一次(每月的时间间隔不是固定值),而CalendarIntervalTrigger支持的间隔单位有秒,分钟,小时,天,月,年,星期。
相较于SimpleTrigger有两个优势:1、更方便,比如每隔1小时执行,你不用自己去计算1小时等于多少毫秒。 2、支持不是固定长度的间隔,比如间隔为月和年。但劣势是精度只能到秒。
它适合的任务类似于:9:00 开始执行,并且以后每周 9:00 执行一次
它的属性有:
- interval 执行间隔
- intervalUnit 执行间隔的单位(秒,分钟,小时,天,月,年,星期)
calendarIntervalSchedule()
.withIntervalInDays(1) //每天执行一次
.build(); calendarIntervalSchedule()
.withIntervalInWeeks(1) //每周执行一次
.build();
8.DailyTimeIntervalTrigger
· 指定每天的某个时间段内,以一定的时间间隔执行任务。并且它可以支持指定星期。
它适合的任务类似于:指定每天9:00 至 18:00 ,每隔70秒执行一次,并且只要周一至周五执行。
属性有:
- startTimeOfDay 每天开始时间
- endTimeOfDay 每天结束时间
- daysOfWeek 需要执行的星期
- interval 执行间隔
- intervalUnit 执行间隔的单位(秒,分钟,小时,天,月,年,星期)
- repeatCount 重复次数
dailyTimeIntervalSchedule()
.startingDailyAt(TimeOfDay.hourAndMinuteOfDay(9, 0)) //第天9:00开始
.endingDailyAt(TimeOfDay.hourAndMinuteOfDay(16, 0)) //16:00 结束
.onDaysOfTheWeek(MONDAY,TUESDAY,WEDNESDAY,THURSDAY,FRIDAY) //周一至周五执行
.withIntervalInHours(1) //每间隔1小时执行一次
.withRepeatCount(100) //最多重复100次(实际执行100+1次)
.build(); dailyTimeIntervalSchedule()
.startingDailyAt(TimeOfDay.hourAndMinuteOfDay(9, 0)) //第天9:00开始
.endingDailyAfterCount(10) //每天执行10次,这个方法实际上根据 startTimeOfDay+interval*count 算出 endTimeOfDay
.onDaysOfTheWeek(MONDAY,TUESDAY,WEDNESDAY,THURSDAY,FRIDAY) //周一至周五执行
.withIntervalInHours(1) //每间隔1小时执行一次
.build();
9.CronTrigger
适合于更复杂的任务,它支持类型于Linux Cron的语法(并且更强大)。基本上它覆盖了以上三个Trigger的绝大部分能力(但不是全部)—— 当然,也更难理解。
它适合的任务类似于:每天0:00,9:00,18:00各执行一次。
它的属性只有:
- Cron表达式。
cronSchedule("0 0/2 8-17 * * ?") // 每天8:00-17:00,每隔2分钟执行一次
.build();
cronSchedule("0 30 9 ? * MON") // 每周一,9:30执行一次
.build();
10.cron表达式
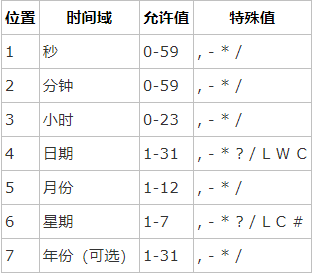
星号():可用在所有字段中,表示对应时间域的每一个时刻,例如, 在分钟字段时,表示“每分钟”;
问号(?):该字符只在日期和星期字段中使用,它通常指定为“无意义的值”,相当于点位符;
减号(-):表达一个范围,如在小时字段中使用“10-12”,则表示从10到12点,即10,11,12;
逗号(,):表达一个列表值,如在星期字段中使用“MON,WED,FRI”,则表示星期一,星期三和星期五;
斜杠(/):x/y表达一个等步长序列,x为起始值,y为增量步长值。如在分钟字段中使用0/15,则表示为0,15,30和45秒,而5/15在分钟字段中表示5,20,35,50,你也可以使用*/y,它等同于0/y;
L:该字符只在日期和星期字段中使用,代表“Last”的意思,但它在两个字段中意思不同。L在日期字段中,表示这个月份的最后一天,如一月的31号,非闰年二月的28号;如果L用在星期中,则表示星期六,等同于7。但是,如果L出现在星期字段里,而且在前面有一个数值X,则表示“这个月的最后X天”,例如,6L表示该月的最后星期五;
W:该字符只能出现在日期字段里,是对前导日期的修饰,表示离该日期最近的工作日。例如15W表示离该月15号最近的工作日,如果该月15号是星期六,则匹配14号星期五;如果15日是星期日,则匹配16号星期一;如果15号是星期二,那结果就是15号星期二。但必须注意关联的匹配日期不能够跨月,如你指定1W,如果1号是星期六,结果匹配的是3号星期一,而非上个月最后的那天。W字符串只能指定单一日期,而不能指定日期范围;
LW组合:在日期字段可以组合使用LW,它的意思是当月的最后一个工作日;
井号(#):该字符只能在星期字段中使用,表示当月某个工作日。如6#3表示当月的第三个星期五(6表示星期五,#3表示当前的第三个),而4#5表示当月的第五个星期三,假设当月没有第五个星期三,忽略不触发;
C:该字符只在日期和星期字段中使用,代表“Calendar”的意思。它的意思是计划所关联的日期,如果日期没有被关联,则相当于日历中所有日期。例如5C在日期字段中就相当于日历5日以后的第一天。1C在星期字段中相当于星期日后的第一天。
Cron表达式对特殊字符的大小写不敏感,对代表星期的缩写英文大小写也不敏感。
三:Job任务
1.并发问题
每次调度都会创建一个新的Job实例,这样的好处是有些任务并发执行的时候,不存在对临界资源的访问问题——当然,如果需要共享JobDataMap的时候,还是存在临界资源的并发访问的问题。
2.JobDataMap
Job都次都是newInstance的实例,那我怎么传值给它? 比如我现在有两个发送邮件的任务,一个是发给"liLei",一个发给"hanmeimei",不能说我要写两个Job实现类LiLeiSendEmailJob和HanMeiMeiSendEmailJob。实现的办法是通过JobDataMap。
每一个JobDetail都会有一个JobDataMap。JobDataMap本质就是一个Map的扩展类,只是提供了一些更便捷的方法,比如getString()之类的。
在定义JobDetail的时候,这个JobDetail定义在main中,加入属性值:
newJob().usingJobData("age", 18) //加入属性到ageJobDataMap
or
job.getJobDataMap().put("name", "quertz"); //加入属性name到JobDataMap
然后在Job中可以获取这个JobDataMap的值。
public class HelloQuartz implements Job {
private String name;
public void execute(JobExecutionContext context) throws JobExecutionException {
JobDetail detail = context.getJobDetail();
JobDataMap map = detail.getJobDataMap(); //方法一:获得JobDataMap
System.out.println("say hello to " + name + "[" + map.getInt("age") + "]" + " at "
+ new Date());
}
//方法二:属性的setter方法,会将JobDataMap的属性自动注入
public void setName(String name) {
this.name = name;
}
}
3.JobExecutionException
Job.execute()方法是不允许抛出除JobExecutionException之外的所有异常的(包括RuntimeException),所以编码的时候,最好是try-catch住所有的Throwable,小心处理。
四:Scheduler
1.说明
Scheduler就是Quartz的大脑,所有任务都是由它来设施。
Schduelr包含一个两个重要组件: JobStore和ThreadPool。
JobStore是会来存储运行时信息的,包括Trigger,Schduler,JobDetail,业务锁等。它有多种实现RAMJob(内存实现),JobStoreTX(JDBC,事务由Quartz管理),JobStoreCMT(JDBC,使用容器事务),ClusteredJobStore(集群实现)、TerracottaJobStore(什么是Terractta)。
ThreadPool就是线程池,Quartz有自己的线程池实现。所有任务的都会由线程池执行。
2.SchedulerFactory
SchdulerFactory,顾名思义就是来用创建Schduler了,有两个实现:DirectSchedulerFactory和 StdSchdulerFactory。前者可以用来在代码里定制你自己的Schduler参数。后者是直接读取classpath下的quartz.properties(不存在就都使用默认值)配置来实例化Schduler。通常来讲,我们使用StdSchdulerFactory也就足够了。
SchdulerFactory本身是支持创建RMI stub的,可以用来管理远程的Scheduler,功能与本地一样,可以远程提交个Job什么的。
PS:主要参考https://www.cnblogs.com/drift-ice/p/3817269.html
最新文章
- DNS初识
- 航空货运:运价类别Rate Class
- PHP获取远程图片并调整图像大小(转)
- MFC对话框Dialog控件处理程序handler因为public修饰符导致无法访问
- C# subString的理解
- c++算法联系,冒泡排序,bubble sort,插入排序,insert sort,
- 普通Java程序员学习使用的6个JDK内建工具
- SGU 176.Flow construction (有上下界的最大流)
- vim编译安装+lua模块
- 《Metasploit魔鬼训练营》第四章(上)
- Beta冲刺-用户测试报告
- 【译】微型ORM:PetaPoco
- hyperledger中文文档学习-4-构建第一个fabric网络
- 笨办法29IF语句
- MFC消息-自定义消息
- java位运算(操作)的使用
- Anaconda常用命令大全
- listview加载数据
- 【c#】腾讯人脸识别api签名
- Spinner的用法