JMM模型基础知识笔记
概述
内存模型可以理解为在特定的操作协议下,对特定的内存或者高速缓存进行读写访问的过程抽象,不同架构下的物理机拥有不一样的内存模型,Java虚拟机也有自己的内存模型,即Java内存模型(JavaMemory Model, JMM)。在C/C++语言中直接使用物理硬件和操作系统内存模型,导致不同平台下并发访问出错。而JMM的出现,能够屏蔽掉各种硬件和操作系统的内存访问差异,实现平台一致性,是的Java程序能够“一次编写,到处运行”。
Java内存模型(JavaMemoryModel简称JMM)是一种抽象的概念,并不真实存在,它描述的是一组规则或规范,通过这组规范定义了程序中各个变量(包括实例字段,静态字段和构成数组对象的元素)的访问方式。JVM运行程序的实体是线程,而每个线程创建时JVM都会为其创建一个工作内存(有些地方称为栈空间),用于存储线程私有的数据,而Java内存模型中规定所有变量都存储在主内存,主内存是共享内存区域,所有线程都可以访问,但线程对变量的操作(读取赋值等)必须在工作内存中进行,首先要将变量从主内存拷贝的自己的工作内存空间,然后对变量进行操作,操作完成后再将变量写回主内存,不能直接操作主内存中的变量,工作内存中存储着主内存中的变量副本拷贝,前面说过,工作内存是每个线程的私有数据区域,因此不同的线程间无法访问对方的工作内存,线程间的通信(传值)必须通过主内存来完成。
JMM不同于JVM内存区域模型
JMM与JVM内存区域的划分是不同的概念层次,更恰当说JMM描述的是一组规则,通过这组规则控制程序中各个变量在共享数据区域和私有数据区域的访问方式,JMM是围绕原子性,有序性、可见性展开。JMM与Java内存区域唯一相似点,都存在共享数据区域和私有数据区域,在JMM中主内存属于共享数据区域,从某个程度上讲应该包括了堆和方法区,而工作内存数据线程私有数据区域,从某个程度上讲则应该包括程序计数器、虚拟机栈以及本地方法栈。
主内存和工作内存
Java内存模型的主要目标是定义程序中各个变量的访问规则,即在虚拟机中将变量存储到内存和从内存中取出变量这样底层细节。此处的变量与Java编程时所说的变量不一样,指包括了实例字段、静态字段和构成数组对象的元素,但是不包括局部变量与方法参数,后者是线程私有的,不会被共享。
Java内存模型中规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存(可以与前面讲的处理器的高速缓存类比),线程的工作内存中保存了该线程使用到的变量到主内存副本拷贝,线程对变量的所有操作(读取、赋值)都必须在工作内存中进行,而不能直接读写主内存中的变量。不同线程之间无法直接访问对方工作内存中的变量,线程间变量值的传递均需要在主内存来完成,线程、主内存和工作内存的交互关系如下图所示,和上图很类似。注意:这里的主内存、工作内存与Java内存区域的Java堆、栈、方法区不是同一层次内存划分,这两者基本上没有关系
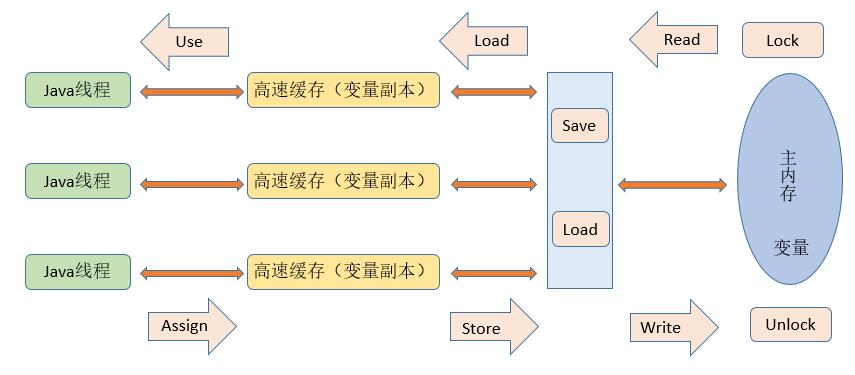
通过对前面的硬件内存架构、Java内存模型以及Java多线程的实现原理的了解,我们应该已经意识到,多线程的执行最终都会映射到硬件处理器上进行执行,但Java内存模型和硬件内存架构并不完全一致。对于硬件内存来说只有寄存器、缓存内存、主内存的概念,并没有工作内存(线程私有数据区域)和主内存(堆内存)之分,也就是说Java内存模型对内存的划分对硬件内存并没有任何影响,因为JMM只是一种抽象的概念,是一组规则,并不实际存在,不管是工作内存的数据还是主内存的数据,对于计算机硬件来说都会存储在计算机主内存中,当然也有可能存储到CPU缓存或者寄存器中,因此总体上来说,Java内存模型和计算机硬件内存架构是一个相互交叉的关系,是一种抽象概念划分与真实物理硬件的交叉。(注意对于Java内存区域划分也是同样的道理)。
JMM-内存交互操作
由上面的交互关系可知,关于主内存与工作内存之间的具体交互协议,即一个变量如何从主内存拷贝到工作内存、如何从工作内存同步到主内存之间的实现细节,Java内存模型定义了以下八种操作来完成:
lock(锁定):作用于主内存的变量,把一个变量标识为一条线程独占状态。
unlock(解锁):作用于主内存变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
read(读取):作用于主内存变量,把一个变量值从主内存传输到线程的工作内存中,以便随后的load动作使用
load(载入):作用于工作内存的变量,它把read操作从主内存中得到的变量值放入工作内存的变量副本中。
use(使用):作用于工作内存的变量,把工作内存中的一个变量值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作。
assign(赋值):作用于工作内存的变量,它把一个从执行引擎接收到的值赋值给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作。
store(存储):作用于工作内存的变量,把工作内存中的一个变量的值传送到主内存中,以便随后的write的操作。
write(写入):作用于主内存的变量,它把store操作从工作内存中一个变量的值传送到主内存的变量中。
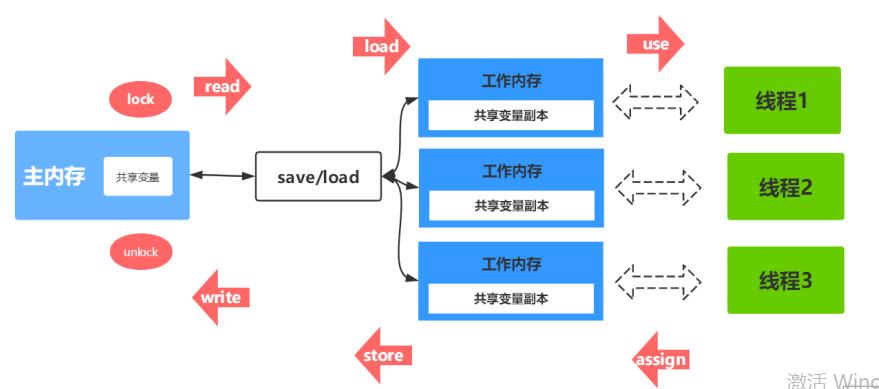
如果要把一个变量从主内存中复制到工作内存,就需要按顺寻地执行read和load操作,如果把变量从工作内存中同步回主内存中,就要按顺序地执行store和write操作。Java内存模型只要求上述两个操作必须按顺序执行,而没有保证必须是连续执行。也就是read和load之间,store和write之间是可以插入其他指令的,如对主内存中的变量a、b进行访问时,可能的顺序是read a,read b,load b, load a。Java内存模型还规定了在执行上述八种基本操作时,必须满足如下规则:
不允许read和load、store和write操作之一单独出现
不允许一个线程丢弃它的最近assign的操作,即变量在工作内存中改变了之后必须同步到主内存中。
不允许一个线程无原因地(没有发生过任何assign操作)把数据从工作内存同步回主内存中。
一个新的变量只能在主内存中诞生,不允许在工作内存中直接使用一个未被初始化(load或assign)的变量。即就是对一个变量实施use和store操作之前,必须先执行过了assign和load操作。
一个变量在同一时刻只允许一条线程对其进行lock操作,lock和unlock必须成对出现
如果对一个变量执行lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前需要重新执行load或assign操作初始化变量的值
如果一个变量事先没有被lock操作锁定,则不允许对它执行unlock操作;也不允许去unlock一个被其他线程锁定的变量。
对一个变量执行unlock操作之前,必须先把此变量同步到主内存中(执行store和write操作)。
这8种内存访问操作很繁琐,后文会使用一个等效判断原则,即先行发生(happens-before)原则来确定一个内存访问在并发环境下是否安全。
long/double非原子协定
JMM要求lock、unlock、read、load、assign、use、store、write这8个操作都必须具有原子性,但对于64为的数据类型(long和double,具有非原子协定:允许虚拟机将没有被volatile修饰的64位数据的读写操作划分为2次32位操作进行。(与此类似的是,在栈帧结构的局部变量表中,long和double类型的局部变量可以使用2个能存储32位变量的变量槽(Variable Slot)来存储的,关于这一部分的详细分析,详见详见周志明著《深入理解Java虚拟机》8.2.1节)
如果多个线程共享一个没有声明为volatile的long或double变量,并且同时读取和修改,某些线程可能会读取到一个既非原值,也不是其他线程修改值的代表了“半个变量”的数值。不过这种情况十分罕见。因为非原子协议换句话说,同样允许long和double的读写操作实现为原子操作,并且目前绝大多数的虚拟机都是这样做的。
重排序
在执行程序时为了提高性能,编译器和处理器经常会对指令进行重排序。从硬件架构上来说,指令重排序是指CPU采用了允许将多条指令不按照程序规定的顺序,分开发送给各个相应电路单元处理,而不是指令任意重排。重排序分成三种类型:
编译器优化的重排序。编译器在不改变单线程程序语义放入前提下,可以重新安排语句的执行顺序。
指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
内存系统的重排序。由于处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。

JMM重排序屏障
从Java源代码到最终实际执行的指令序列,会经过三种重排序。但是,为了保证内存的可见性,Java编译器在生成指令序列的适当位置会插入内存屏障指令来禁止特定类型的处理器重排序。对于编译器的重排序,JMM会根据重排序规则禁止特定类型的编译器重排序;对于处理器重排序,JMM会插入特定类型的内存屏障,通过内存的屏障指令禁止特定类型的处理器重排序。这里讨论JMM对处理器的重排序,为了更深理解JMM对处理器重排序的处理,先来认识一下常见处理器的重排序规则;
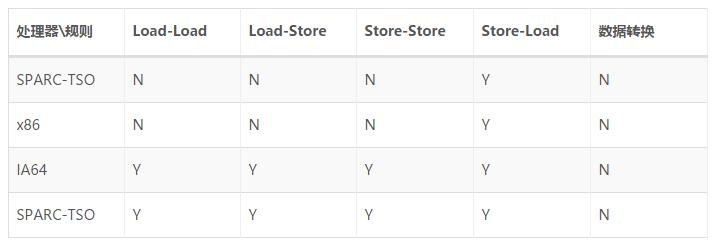
其中的N标识处理器不允许两个操作进行重排序,Y表示允许。其中Load-Load表示读-读操作、Load-Store表示读-写操作、Store-Store表示写-写操作、Store-Load表示写-读操作。可以看出:常见处理器对写-读操作都是允许重排序的,并且常见的处理器都不允许对存在数据依赖的操作进行重排序(对应上面数据转换那一列,都是N,所以处理器不允许这种重排序)。
那么这个结论对我们有什么作用呢?比如第一点:处理器允许写-读操作两者之间的重排序,那么在并发编程中读线程读到可能是一个未被初始化或者是一个NULL等,出现不可预知的错误,基于这点,JMM会在适当的位置插入内存屏障指令来禁止特定类型的处理器的重排序。内存屏障指令一共有4类:
LoadLoad Barriers:确保Load1数据的装载先于Load2以及所有后续装载指令
StoreStore Barriers:确保Store1的数据对其他处理器可见(会使缓存行无效,并刷新到内存中)先于Store2及所有后续存储指令的装载
LoadStore Barriers:确保Load1数据装载先于Store2及所有后续存储指令刷新到内存
StoreLoad Barriers:确保Store1数据对其他处理器可见(刷新到内存,并且其他处理器的缓存行无效)先于Load2及所有后续装载指令的装载。该指令会使得该屏障之前的所有内存访问指令完成之后,才能执行该屏障之后的内存访问指令。
总结
原子性,有序性,可见性的说明请见我的另外一篇随笔:JAVA多线程之并发编程三大核心问题
感谢其他网络大神的分享:
https://www.cnblogs.com/jiangds/p/6510583.html
https://www.jianshu.com/p/bf158fbb2432
https://www.jianshu.com/p/76959115d486
最新文章
- [Unity3D]做个小Demo学习Input.touches
- NOIP2009pj道路游戏[环形DP 转移优化 二维信息]
- 测试服务API的_苏飞开发助手_使用说明
- Ubuntu 14.04安装OpenCV 3.1
- asp.net + Jquery 实现类似Gridview功能 (一)
- 代码的未来读书笔记<二>
- PAT (Advanced Level) 1095. Cars on Campus (30)
- Hive表生成函数explode讲解
- SQL Server 深入解析索引存储(聚集索引)
- 牛客小白月赛12C (线性筛积性函数)
- css3组件之几何图形
- npm全局目录修改
- ceph部署实践(mimic版本)
- gradle tool升级到3.0注意事项
- eclipse中svn插件的工程不能与svn资源库同步的解决方法
- 打包spring项目遇到的坑 Unable to locate Spring NamespaceHandler for XML schema ……shcema/context 产生的原因及解决方法
- oracle 如何查看oracle数据库版本
- ClamAV病毒软件的安装和使用
- [LeetCode] 443. String Compression_Easy tag:String
- eclipse override报错
热门文章
- Mybatis环境搭建及测试
- CF761A Dasha and Stairs 题解
- ThreadLocal的正确使用与原理
- svn服务器用户名密码更改后,如何更新本地用户名密码
- 查找MySql的配置文件my.cnf所在路径
- 【LeetCode】278. First Bad Version 解题报告(Python & C++)
- hdu-5568SUM (dp)
- 解决"The remote SSH server rejected X11 forwarding request"问题
- Essentially No Barriers in Neural Network Energy Landscape
- CS5268 Typec转HDMI+VGA+PD3.0四合一扩展坞转换器方案芯片