Redis缓存穿透、缓存击穿、缓存雪崩的介绍及其解决方案
首先,来画一张图了解下缓存处理的流程
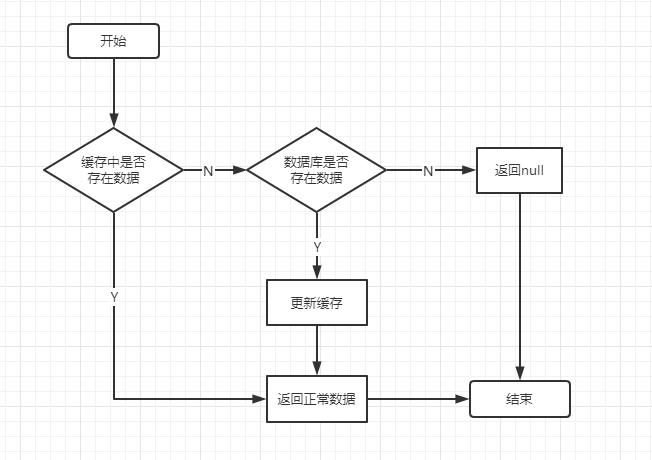
一、缓存穿透
描述:
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求查询该数据,导致数据库压力过大。
解决方案:
1、接口校验
如鉴权校验、数据合法性校验
2、布隆过滤器
将数据库中所有的查询条件,放入布隆过滤器中,当一个查询请求过来时,先经过布隆过滤器进行查,如果判断请求查询值存在,则继续查;如果判断请求查询不存在,直接丢弃。
3、缓存空结果
当没有命中缓存时,也没有从数据库取到数据时,我们给它缓存一个空结果,并且设置一个较短的过期时间(例如30s),之后当有请求访问时,可以直接从缓存中获取,保护后端数据源。
这个解决方案会存在两个问题:
1.会需要更多的空间来存储更多的键,因为这当中可能会产生很多的空值键;
2.数据一致性的问题,即时给空值设定了过期时间,缓存层和存储层还有会有一定时间的不一致,这对需要保持数据一致性的业务会有影响。
二、缓存击穿
描述:
缓存击穿是缓存中没有但数据库有的数据(一般是“热点数据”缓存时间到期了),这个时候由于并发量特别大,读缓存的时候读取不到数据,都同时去数据库读取数据了,导致数据库的压力瞬间增大,
解决方案:
1、设置热点数据永不过期
2、加互斥锁
当多个线程同时去数据库查询这一条数据时,我们可以在第一个查询时使用互斥锁来锁住它,其他的线程走到这一步拿不到锁就进入等待的状态,等第一个线程查完数据,写入缓存后。后面的线程进来就可以直接走缓存了。
贴代码,仅供参考:
1 static Lock reenLock = new ReentrantLock();
2 public Object getData() throws InterruptedException{
3 //从缓存中获取数据
4 Object object = getDataFromRedis();
5 if(object == null){
6 if(reenLock.tryLock()){
7 try {
8 System.out.println("拿到锁,从数据库中获取数据并写入缓存中");
9 //从数据库中查询数据
10 object = getDataFromDB();
11 //写入缓存
12 setDataToRedis(object);
13 } finally {
14 reenLock.unlock();// 释放锁
15 }
16 }else{
17 object = getDataFromRedis();// 先查一下缓存
18 if (object == null) {
19 System.out.println("我没拿到锁,缓存也没数据,先等待一下");
20 Thread.sleep(100);
21 return getData();// 重试
22 }
23 }
24 }
25 return object;
26 }
三、缓存雪崩
描述:
缓存雪崩与缓存击穿不同的一点是,缓存雪崩是指大量的热点Key设置了相同的过期时间,导致缓存在同一时刻大量失效,这时由于并发量过大,会导致所有的请求都需要到数据库去读取数据,数据库压力骤增,引起雪崩。
解决方案:
1、过期时间打散
既然是因为大量缓存集中失效导致的,那第一想到的应该是让它们不要集中失效就好了。可以给缓存的过期时间加一个随机值时间,使得每一个Key的过期时间都错开来,不会在同一时刻失效。
2、热点数据永不过期
3、加互斥锁
该方式和缓存击穿一样,按Key维度去加锁,同一个Key,指允许一个线程去请求数据库,后续的都从缓存中读取。
最后
欢迎补充,点个推荐鼓励一下吧!
最新文章
- 运维自动化轻量级工具pssh
- Yii2 使用 Joins 查询
- DateFormat 中间加别的字符
- WordPress 主题开发 - (三) 开发工具 待翻译
- 【转】Android 驱动开发系列四
- 转载:struts标签<s:date>的使用
- js你真的了解offsetWidth吗
- cglib动态代理举例
- kvm之十二:虚拟机迁移
- CentOS7.2卸载完CDH5.12后重装CDH
- 使用requests模块保存网络上的图片
- [转帖]JavaEE中Web服务器、Web容器、Application服务器区别及联系
- HibernateUtil工具类的使用
- MT【198】连乘积放缩
- 功能强大的StickyHeaderListView:标题渐变、吸附悬停、筛选分类、动态头部
- struts2 标签使用注意
- 模块型css样式
- 使用Xfire发布WebService接口遇到的问题:
- kubeadm搭建kubernetes集群之一:构建标准化镜像
- 第六章使用java实现面向对象-集合框架