稀疏自编码器及TensorFlow实现
2024-09-07 11:21:03
自动编码机更像是一个识别网络,只是简单重构了输入。而重点应是在像素级重构图像,施加的唯一约束是隐藏层单元的数量。
有趣的是,像素级重构并不能保证网络将从数据集中学习抽象特征,但是可以通过添加更多的约束确保网络从数据集中学习抽象特征。
稀疏自编码器(又称稀疏自动编码机)中,重构误差中添加了一个稀疏惩罚,用来限定任何时刻的隐藏层中并不是所有单元都被激活。如果 m 是输入模式的总数,那么可以定义一个参数 ρ_hat,用来表示每个隐藏层单元的行为(平均激活多少次)。基本的想法是让约束值 ρ_hat 等于稀疏参数 ρ。具体实现时在原始损失函数中增加表示稀疏性的正则项,损失函数如下:

如果 ρ_hat 偏离 ρ,那么正则项将惩罚网络,一个常规的实现方法是衡量 ρ 和 ρ_hat 之间的 Kullback-Leiber(KL) 散度。
准备工作
在开始之前,先来看一下 KL 散度 DKL的概念,它是衡量两个分布之间差异的非对称度量,本节中,两个分布是 ρ 和 ρ_hat。当 ρ 和 ρ_hat 相等时,KL 散度是零,否则会随着两者差异的增大而单调增加,KL 散度的数学表达式如下:
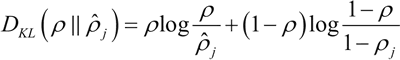
下面是 ρ=0.3 时的 KL 的散度 DKL的变化图,从图中可以看到,当 ρ_hat=0.3时,DKL=0;而在 0.3 两侧都会单调递增:
具体做法
- 导入必要的模块:

- 从 TensorFlow 示例加载 MNIST 数据集:

- 定义 SparseAutoEncoder 类,除了引入 KL 散度损失之外,它与前面的自动编码机类非常相似:

将 KL 约束条件添加到损失函数中,如下所示:

其中,alpha 是稀疏约束的权重。该类的完整代码如下所示:

- 声明 SparseAutoEncoder 类的一个对象,调用 fit() 训练,然后计算重构的图像:

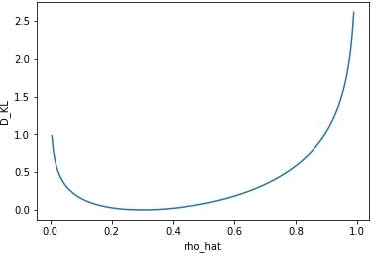
- 重构损失均方误差随网络学习的变化图:

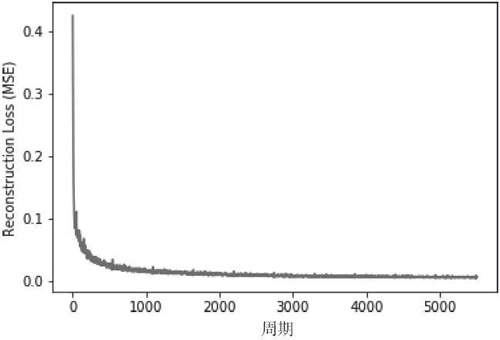
- 查看重构的图像:

结果如下:

解读分析
必须注意到,稀疏自编码器的主要代码与标准自动编码机完全相同,稀疏自编码器只有一个主要变化——增加了KL散度损失以确保隐藏(瓶颈)层的稀疏性。如果将两者的重构结果进行比较,则可以看到即使隐藏层中的单元数量相同,稀疏自动编码机也比标准自动编码机好很多:
在 MNIST 数据集上,标准自动编码机训练后的重构损失是 0.022,而稀疏自编码器是 0.006,由此可见稀疏自编码器对数据的内在表示学习得更好一些。
最新文章
- Waud.js – 使用HTML5降级处理的Web音频库
- 关于PHP学习的各种网站
- 6、XML(2)
- 一、Java语言基础
- C#开发BHO程序(引)
- DataTemplate和ControlTemplate的关系
- iOS 获取项目名称及版本号
- C++头文件保护符和变量的声明定义
- easyUI创建人员树
- Linux系统安装软件出错
- Havel-Hakimi定理---通过度数列判断是否可图化
- hdu 2553 n皇后问题【DFS递归解法】
- Java 中的伪共享详解及解决方案
- sql 中常见的控制流语句
- .mht文件转换为html
- Ganglia监控Hadoop集群的安装部署
- thinkphp中常用的模板变量
- android FrameLayout
- 【MongoDB】NoSQL Manager for MongoDB 教程(进阶篇)
- gitlab之gitlab-runner自动部署(二)
热门文章
- C/C++ 对代码节的动态加解密
- POJ1376简单广搜
- NetBIOS名称欺骗和LLMNR欺骗
- Python 爬虫 BeautifulSoup4 库的使用
- 【dependencyManagement版本管理】dependencies.dependency.version is missing
- [源码解析] 并行分布式任务队列 Celery 之 EventDispatcher & Event 组件
- 【译】.NET 的新的动态检测分析
- Pytorch_Part2_数据模块
- 16.分类和static
- Linux下script命令录制、回放和共享终端操作script -t 2> timing.log -a output.session # 开始录制