关于 用fscanf读文件,把文件中用##分割的内容分开
2024-10-19 13:18:03
今天呀,被学弟问了一个问题
文件里存的是“123##456##0##1644444.....##”
为什么用fscanf(fp, "%s##%s......", &card[sum1].aName, .......)从文件里读出来,那个aName里就把123##456啥啥啥的全读进去了。
看来是因为用#作为分割控制格式的时候,#也会被当作字符读进后面的card[sum1].aName。
于是搜了搜fscanf,用菜鸟教程的示例代码重现了他的问题:
文件中是“We##are##in##2014”
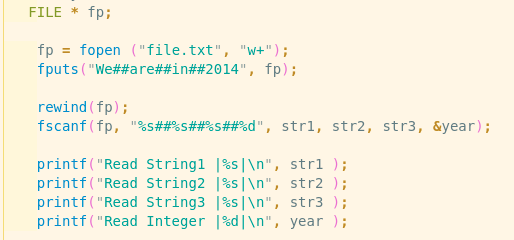
读出来是这样的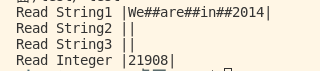
并没有成功分开那些字符串。
于是就想到用%[^#],当碰到#时就把#号前的内容存入后面对应的变量中。
然后按照格式写,如图
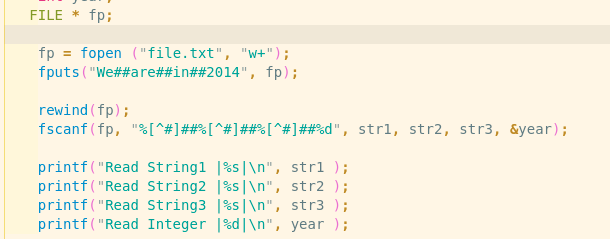
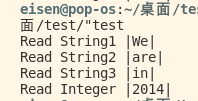
然后就能得到正确分割开的结果了,输出如下:
最新文章
- python基础-文件操作
- Nginx安装与使用
- sky
- android基础---->JSON数据的解析
- 判断手机连接的是fdd还是tdd的办法
- ASP.NET MVC5 高级编程 第2章 控制器
- Yii 1 数据库操作 笔记
- CString向char类型转化 ---“=”: 无法从“wchar_t *”转换为“char *
- MVC小系列(九)【引入namespace】
- Oracle数据库锁表的查询方法以及解锁的方法
- 基于Qt的图像采集系统
- Tomcat下的work目录
- Frame Stacking(拓扑排序)
- file.go
- 2018年冬季寒假作业4--PTA 打印沙漏
- How to Build a New Habit: This is Your Strategy Guide
- jquery操作复选框(checkbox)的一些小技巧总结
- DevOps的故事(如何整合开发和运维?)
- 基于python的机器学习实现日元币对人民币汇率预测
- opengl学习笔记(四):openCV读入图片,openGL实现纹理贴图