【总结】java集合
一.collection
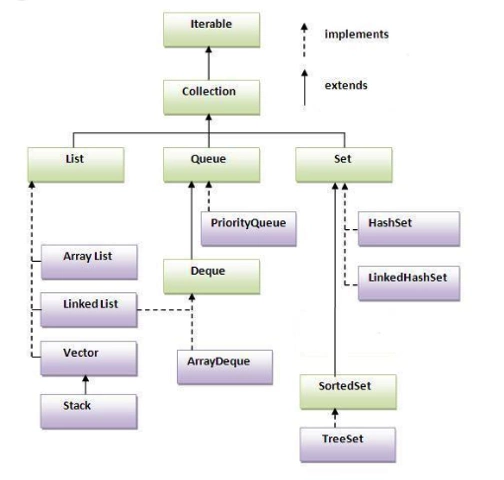
1、List接口和Set接口都继承自Collection接口,Collection接口继承Iterable接口(Iterable有一个Iterator方法),即可迭代的;Collection只能存储引用类型(对于基本数据类型进行装箱操作)
2、List接口存储元素特点:有序(存进去什么顺序取出来还什么顺序),可重复;Set接口存储元素特点:无序,不可重复
3、实现List接口主要的类包括ArrayList,LinkedList,Vector;实现Set的主要类包括:hashSet,TreeSet(自动排序)
1.List
1.ArrayList
(1)基本情况
ArrayList实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通过数组实现。除该类未实现同步外,其余跟Vector大致相同。每个ArrayList都有一个容量(capacity),表示底层数组的实际大小,容器内存储元素的个数不能多于当前容量。当向容器中添加元素时,如果容量不足,容器会自动增大底层数组的大小。Java泛型只是编译器提供的语法糖,所以这里的数组是一个Object数组,以便能够容纳任何类型的对象。
(2)扩容机制
ArrayList是采取延迟分配对象空间的
①不指定ArrayList的初始容量,在第一次add的时候会把容量初始化为10个,这个数值是确定的;
②ArrayList的扩容时机为add的时候容量不足,扩容的后的大小为原来的1.5倍,扩容需要拷贝以前数组的所有元素到新数组
(2)特点
查询效率高,插入删除效率低。查找的话,直接通过下标可以查找到,所以效率快;插入删除的话,由于插入(删除)位置后面的元素都需要移动,所以效率较差。
2.LinkedList
(1)基本情况
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。这样看来,LinkedList简直就是个全能冠军。当你需要使用栈或者队列时,可以考虑使用LinkedList,一方面是因为Java官方已经声明不建议使用Stack类,更遗憾的是,Java里根本没有一个叫做Queue的类(它是个接口名字)
(2)栈和队列的选择
关于栈或队列,现在的首选是ArrayDeque(双端队列),它有着比LinkedList(当作栈或队列使用时)有着更好的性能。
A、ArrayDeque内部使用数组实现,并且是循环数组
B、LinkedList内部使用链表实现
(3)特点
LinkedList底层通过双向链表实现。增删快,查找慢(增删只需要改变前后指针指向,查找需要从链表头开始查找)。为追求效率LinkedList没有实现同步(synchronized),如果需要多个线程并发访问,可以先采用Collections.synchronizedList()方法对其进行包装。
3.Vector
(1)和ArrayList一样,底层使用数组实现
(2)vector是线程安全的,效率受到影响。
(3)vector在多线程环境下也会受到线程安全问题。比如说,一个线程去删除i位置上的元素,另外一个线程去拿i位置上的元素,就会报异常。
(4)默认长度:10 扩容为原来的2倍(arraylist是1.5倍)
4.Stack
Stack是继承自Vector的,所以用法啊,线程安全什么的跟Vector都差不多,只是有几个地方需要注意:
(1)add()和push(),stack是将最后一个element作为栈顶的,所以这两个方法对stack而言是没什么区别的,但是,它们的返回值不一样,add()返回boolean,就是添加成功了没有;push()返回的是你添加的元素。为了可读性以及将它跟栈有一丢丢联系,推荐使用push。
(2)peek()和pop(),这两个方法都能得到栈顶元素,区别是peek()只是读取,对原栈没有什么影响;pop(),从字面上就能理解,出栈,所以原栈的栈顶元素就没了。
2.Set
HashSet添加的元素是存放在HashMap的key位置上,而value取了默认常量PRESENT,是一个空对象。(为什么不用null?因为set的remove返回Boolean,如果value设为null,remove后为null,并不代表它删除成功)
1.HashSet
(1)不能保证元素的排列顺序,顺序有可能发生变化
(2)不是同步的
(3)集合元素可以是null,但只能放入一个null
2.TreeSet
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序和定制排序,其中自然排序为默认的排序方式。向TreeSet中加入的应该是同一个类的对象。
TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0
自然排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(T o1,T o2)方法。
(1)TreeSet 是二叉树实现的,TreeSet中的数据是自动排好序的,不允许放入null值。
(2)HashSet 是哈希表实现的,HashSet中的数据是无序的,可以放入null,但只能放入一个null,两者中的值都不能重复,就如数据库中唯一约束。
(3)HashSet要求放入的对象必须实现HashCode()方法,放入的对象,是以hashcode码作为标识的,而具有相同内容的 String对象,hashCode是一样,所以放入的内容不能重复。但是同一个类的对象可以放入不同的实例 。
2.Map
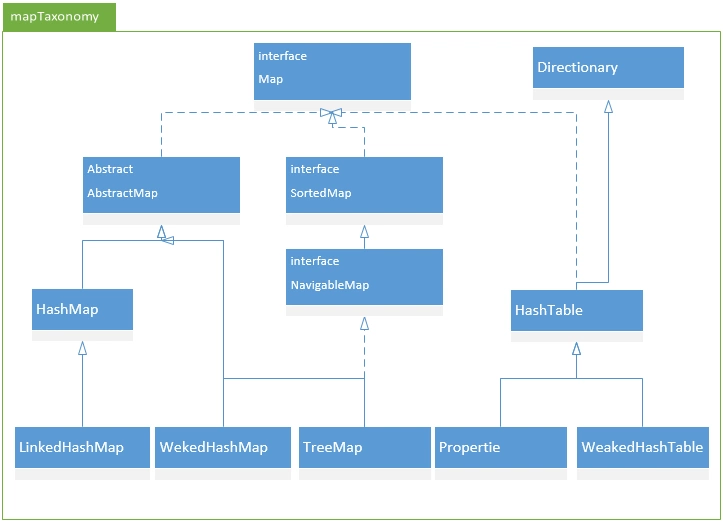
1.hashmap
(1)HashMap的结构:
HashMap的主干是一个Entry数组。Entry是HashMap的基本组成单元,每一个Entry包含一个key-value键值对。HashMap采用了链地址法,也就是数组+链表的方式处理hash冲突
将对向放入到HashMap或HashSet中时,有两个方法需要特别关心:A、hashCode()和equals()。hashCode()方法决定了对象会被放到哪个bucket里,当多个对象的哈希值冲突时,equals()方法决定了这些对象是否是“同一个对象”。所以,如果要将自定义的对象放入到HashMap或HashSet中,需要重写 hashCode()和equals()方法。
B、插入使用头插法
(2)两个重要的方法put() get()
①.put方法:调用key的hash方法得到这个元素在数组中的位置(即下标)如果该位置已经存在其它元素,那么在同一个位子上的元素将以链表的形式存放,通过equals方法依次比较链表中的key,相同则替换。不同则添加到表尾(1.8之前添加到表头)。
②.get方法:调用key的hash方法得到这个元素在数组中的位置(即下标),然后通过key的equals方法在对应位置的链表中找到需要的元素。
(需要注意Jdk 1.8中对HashMap的实现做了优化,当链表中的节点数据超过八个之后,该链表会转为红黑树来提高查询效率,从原来的O(n)到O(logn))
(3)为什么jdk8后插到链表尾?
HashMap在jdk1.7中采用头插入法,在扩容时会改变链表中元素原本的顺序,以至于在并发场景下导致链表成环的问题。而在jdk1.8中采用尾插入法,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了
(4)HashMap的resize(rehash)
当HashMap中的元素越来越多的时候,hash冲突的几率也就越来越高,因为数组的长度是固定的。所以为了提高查询的效率,就要对HashMap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,这是一个常用的操作,而在HashMap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。
那么HashMap什么时候进行扩容呢?当HashMap中的元素个数超过数组大小loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,这是一个折中的取值。也就是说,默认情况下,数组大小为16,那么当HashMap中元素个数超过160.75=12的时候,就把数组的大小扩展为 2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
(5)HashMap的性能参数
HashMap():构建一个初始容量为 16,负载因子为 0.75 HashMap。扩容为原来的2倍
(6)Fail-Fast机制
java.util.HashMap不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。
这一策略在源码中的实现是通过modCount域,modCount顾名思义就是修改次数,对HashMap内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的expectedModCount。
在迭代过程中,判断modCount跟expectedModCount是否相等,如果不相等就表示已经有其他线程修改了Map (注意到modCount声明为volatile,保证线程之间修改的可见性)
Iterator<Map.Entry<String, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<String, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
2.LinkedHashMap
(1)基本信息
HashMap有一个问题,迭代hashmap并不是有序的。所以出现了LinkedHashMap,它集成了Hashmap,是有序的
(2)实现原理
它重新定义了数组中保存的元素Entry,该Entry除了保存当前对象的引用外,还保存了其上一个元素before和下一个元素after的引用,从而在哈希表的基础上又构成了双向链接列表
3.TreeMap
TreeMap集合是基于红黑树(Red-Black tree)的 NavigableMap实现。该集合最重要的特点就是可排序,该映射根据其键的自然顺序进行排序
4.HashMap和Hashtable对比
(1)Hashtable基于Dictionary类,Hashmap基于AbstractMap类
(2)HashMap不是线程安全的;HashTable是线程安全的,其线程安全是通过Sychronized实现。由于上述原因,HashMap效率高于HashTable
5.hashmap为什么不是线程安全?
HashMap的get操作可能因为resize而引起死循环(cpu100%)
6.concurrenthashmap?
Hashtable容器使用synchronized来保证线程安全,这样每一时刻只能有一条线程访问集合,效率非常低
jdk1.7 concurrenthashmap采用分段锁,将数据分成一段一段存储,每一段数据使用一把锁(segment分段锁)存储。所以修改某一数据时只需要获得该段的segement锁,其它段的数据仍然能正常的读写
JDK1.8的实现已经摒弃了Segment的概念,而是直接用数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本
最新文章
- 调用0A中断输入字符串数据段的DUP定义
- 图片懒加载插件lazyload使用方法
- BrowserSync,调试利器--自动刷新(转
- 万网免费主机wordpress快速建站教程-万网主机申请
- 转;说说AngularJS中的$parse和$eval
- 【QT相关】文件、目录基础操作
- Extjs6(一)——用sencha cmd建立一个ExtJs小项目
- Java学习笔记一---JVM、JRE、JDK
- 揭秘 HashMap 实现原理(Java 8)
- nodejs----安装配置
- MySql 主从复制 mysql-proxy实现读写分离
- java解压多层目录中多个压缩文件和处理压缩文件中有内层目录的情况
- 『TensorFlow』函数查询列表_张量属性调整
- File类_构造函数
- ftp/sftp定时自动上传文件脚本(CentOS)
- 双向循环链表涉及双向指针的基本操作(C语言)
- boost-字符编码转换:使用conv
- Python 函数(一)
- MFC框架仿真<一>
- java 数据结构与算法---二叉树