hadoop hdfs 高可用
单点故障:
如果某一个节点或服务出了问题,导致服务不可用
单点故障解决方式:
1.给容易出故障的地方安排备份
2.一主一备,要求同一时刻只能有一个对外提供服务
3.当active挂掉之后,standby很短时间内切换成为active,保证服务可用性
HA脑裂问题:
1.主备互相认为对方挂掉,都去启动
2.主备互相认为对方启动,都把自己切换为备,就没有服务了
hadoop hdfs HA:使用Clouera QJM解决hdfs HA
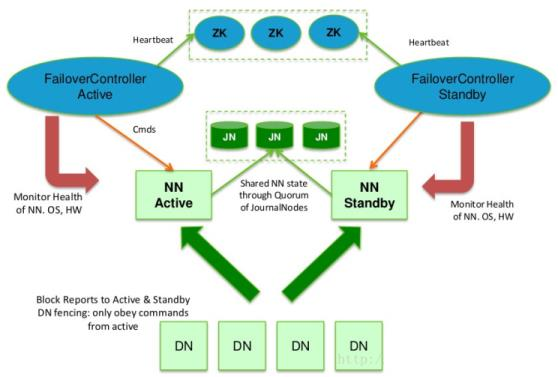
一.如何保证集群之间不会出现脑裂问题,使得集群同一时间有且只有一个active
1.启动ha集群,两个zkfc到zk集群指定目录创建znode(非序列化,短暂的),谁创建成功,谁对应的那台机器的nn就是active,没创建成功的设置该节点的监听.
2.当active节点不健康,zkfc能够感知不健康信息,断开自己跟zk集群的连接,节点被zk删除,触发监听事件,另外一个standby对应就会收到监听
3.当standby对应的zkfc收到监听回调,远程补刀,保证active不能假死,防止出现脑裂问题,ssh active kill -9 xxxx(6.因为补刀的存在,需要在两个nn之间互相免密登录)
4.补刀回来,再去zk注册该节点,同时把自己的状态变成active
5. 之前的那个active机器修复好之后,重新启动,zkfc去注册监听,设置节点监听,把自己变成standby
二.如何保证active standby之间元数据同步
1.JournalNode集群2n+1共享edits log
2..active向jn集群写edit log,只有n+1台写成功,即认为写成功
3..satndby就会感知jn集群有数据变化,把变化的edits log拉取过来,重演一遍操作记录
4.实际上standby跟所需要的内存一模一样,内存中的元数据也时刻在变化,但是不对外提供服务
三.DN怎么知道接收是Active还是Standby的信息
1.每个 NN 改变状态的时候,向 DN 发送自己的状态和一个序列号。
2.DN 在运行过程中维护此序列号,当 failover 时,新的 NN 在返回 DN 心跳时会返回自
己的 active 状态和一个更大的序列号。DN 接收到这个返回则认为该 NN 为新的 active。
3.如果这时原来的 active NN 恢复,返回给 DN 的心跳信息包含 active 状态和原来的序
列号,这时 DN 就会拒绝这个 NN 的命令。
最新文章
- SQL拼接自己需要的字符串
- 使用spring方式来实现aop编程
- JS date常用代码积累
- oracle的加密和解密
- ServletContext与网站计数器
- 图片延迟加载(用jq自己写的方法)
- homework01
- windows系统下搭建linux
- linux 下执行.sh文件总是提示permission denied
- SSM 即所谓的 Spring MVC + Spring + MyBatis 整合开发。
- activiti自己定义流程之整合(四):整合自己定义表单部署流程定义
- Spring Boot --- Swagger基本使用
- [面试题目]IT面试中的一些基础问题
- 03-03:springBoot 整合thymeleaf
- .apk等常用文件下载出现如果应下载文件,请添加 iis MIME 映射。
- foreach循环赋值问题
- TiXmlHandle的使用-简化tinyxml的代码
- DOM基本代码二
- 第一篇:Spark SQL源码分析之核心流程
- Ubuntu 源使用帮助