记录使用jQuery和Python抓取采集数据的一个实例
从现成的网站上抓取汽车品牌,型号,车系的数据库记录。
先看成果,大概4w条车款记录
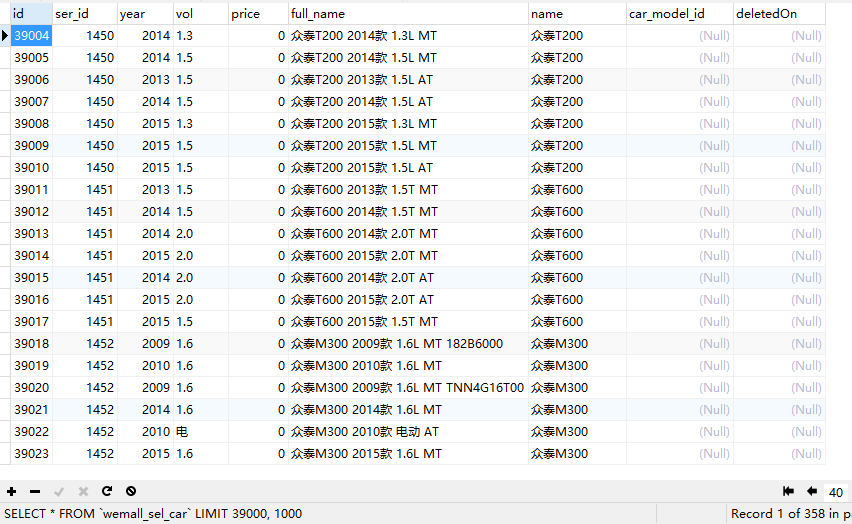
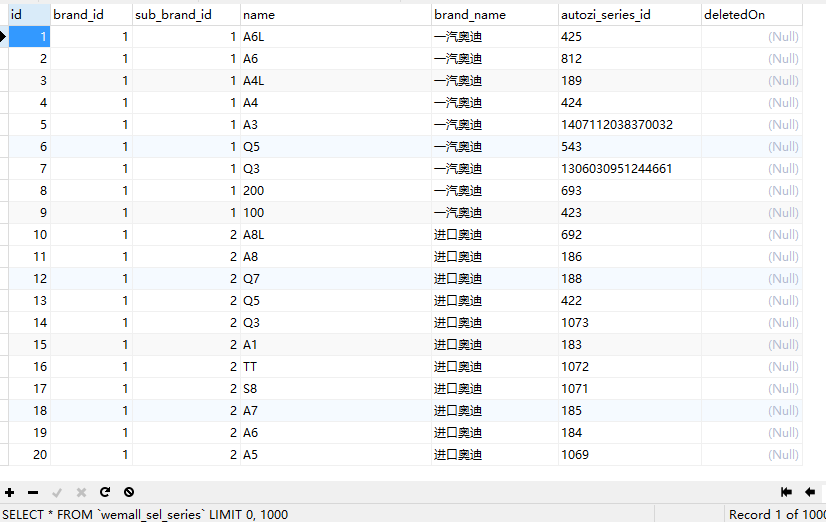
一共建了四张表,分别存储品牌,车系,车型和车款
大概过程:
使用jQuery获取页面中呈现的大批内容
能通过页面一次性获得所需大量数据的,通过jQuery获取原数据,并一条条显示在console面板中。每条我是直接拼接成sql显示。
打开chrome,进到地址http://www.autozi.com/carBrandLetter/.html。按F12点console面板。粘贴下面的内容
$("tr.event_scroll").each(function(i){
var _this = $(this);
// 奥迪,宝马各个主品牌
var mainBrandName = _this.find('th>h4').text();
var seriesList = $(this).find('.car-series-list li');
$.each(seriesList, function(i, el){
// 各品牌下的子品牌,如奥迪下有进口奥迪和一汽奥迪
var subBrandName = $(el).find('h4').text();
// 各个车系,如奥迪A6,A4
var models = $(el).find('a.carModel')
$.each(models, function(j, element){
var model = $(element).text();
var carSeriesId = getCarSeriesId($(element).attr('s_href'));
// 拼接成sql语句,插入数据库用
getSql(subBrandName,model,carSeriesId);
})
});
});
// 根据地址获取参数id
// 如http://www.autozi.com:80/carmodels.do?carSeriesId=1306030951244661 得到1306030951244661
function getCarSeriesId(str) {
return str.slice(str.indexOf('=')+1);
}
// 拼接成sql语句,插入数据库用
// insert into tableName(brandName, name, carSeriesId) values ("一汽奥迪", "A6", "425");
function getSql(subBrandName,model,carSeriesId) {
var str = 'insert into tableName(brandName, name, carSeriesId) values ("'+subBrandName+'", "'+model+'", "'+carSeriesId+'");';
console.log(str);
}
回车,显示如下。
这样我就拿到了所有的汽车品牌,子品牌和车系。

但是具体的包含年份和排量的车型还没有办法拿到。比如奥迪A6L。有2011年款2.0L的,有2005年4.2L的。
网站做成了在弹窗中显示。

比如点击A6L。发送一个ajax请求,请求地址是:http://www.autozi.com/carmodels.do?carSeriesId=425&_=1462335011762
当点击第二页,又发起了一个新的ajax请求,请求地址是:http://www.autozi.com/carmodelsAjax.do?currentPageNo=2&carSeriesId=425&_=1462335011762
奥迪A6L一共有四页carSeriesId=425刚才已经拿到了。要获得所有年份和排量的A6L。就要发起四个请求,地址是:
http://www.autozi.com/carmodelsAjax.do?currentPageNo=[#page]&carSeriesId=425
[#page]即为1-4。每次改变下分页参数数值即可。当请求不存在的http://www.autozi.com/carmodelsAjax.do?currentPageNo=5&carSeriesId=425。会返回空页面。
想想之前学了点使用Python的BeautifulSoup 类库采集网页内容。刚好在这里派上了用场。
使用Python获取页面中的内容
getSoup是打开页面并返回html,请求页面地址中初始pageNo参数是1。判断返回的html是否为空。如果有内内容则pageNo+1。继续请求这个地址。
如果没有则请求下一个车系的地址。
每两个车系之间暂停10秒。因为我发现如果操作过于频繁服务端会返回空。
from urllib.request import urlopen
from bs4 import BeautifulSoup
from time import sleep # carList
def getList(carList):
fo = open("cars.txt", "a+")
for link in soup.find_all("a", class_="link"):
#print(link.get('title'))
fo.write(link.get('title')+'\n')
fo.close() def getSoup(modelId, pageNumber):
tpl_url = "http://www.autozi.com/carmodelsAjax.do?carSeriesId=[#id]¤tPageNo=[#page]"
real_url = tpl_url.replace('[#id]', str(modelId))
real_url = real_url.replace('[#page]', str(pageNumber))
from_url = urlopen(real_url).read().decode('utf-8')
soup = BeautifulSoup(from_url, "html5lib")
return soup modelIds = [741,1121,357,1055] for modelId in modelIds:
flag = True
i = 1
while flag:
soup = getSoup(modelId, i)
carList = soup.find_all('li', limit=1)
if len(carList):
getList(carList)
i=i+1
else:
flag = False
sleep(10)
因为这个脚本的执行时间会很长,我是放到自己的vps上,将该脚本另存为car.py
然后在linux命令行里执行 nohup ./car.py &
这样保证防止断网退出执行,同时将该任务放到后台。
最新文章
- document.all.wb.ExecWB
- .htaccess绑定网站主目录的方法
- jQuery Validate 插件[表单验证 属性介绍]
- Lua代码解析-写给C和C++开发人员
- PHP 生命周期,Opcode 缓存。
- CSDN挑战编程——《数学问题》
- 计算一个数组里的重复值并且删去(java)
- 面试题之 query转为obj
- CMA-连续内存分配
- 安全终端模拟工具Xshell 5使用密钥认证登录配置详细教程
- 【Python】正则表达式re
- css(1-1)样式表
- 【安富莱二代示波器教程】第19章 附件E---参考资料
- MongoDB Export & Import
- 将linux系统目录挂载到其他分区,扩大系统可用空间
- A1056. Mice and Rice
- 091实战 Nginx配置(日志服务器中关于日志的产生)
- angularjs学习第二天笔记---过滤器
- Gradle gitignore Gradle 模式 上传SVN 要忽略的文件
- awk去重以某列重复的行
热门文章
- Failed to read Class-Path attribute from manifest of jar file:/XXX问题
- shouldRasterize 光栅化、(缓存)复用、内存、内容稳定
- P2149 [SDOI2009]Elaxia的路线
- win10中显示资源管理器扩展
- 6、Spring Cloud -熔断器Hystrix
- WEB安全 Sqlmap 中绕过空格拦截的12个脚本
- Mybatis Plus启动注入 SQL 原理分析
- 部分用户间接性访问不了linux服务器解决方法
- Spring Cloud Sleuth 之Greenwich版本全攻略
- 获取 iOS APP 内存占用的大小