004 Hadoop2.x基础知识
一:大数据应用
1.Cloudera
cloudera公司是Hadoop三大发行商之一,其版本为CDH版本,现在最新的版本是CDH5。
网站:http://archive.cloudera.com/cdh5/
现在官网上的最新的版本:
2.大数据的三大基础
Java
SQL
Linux
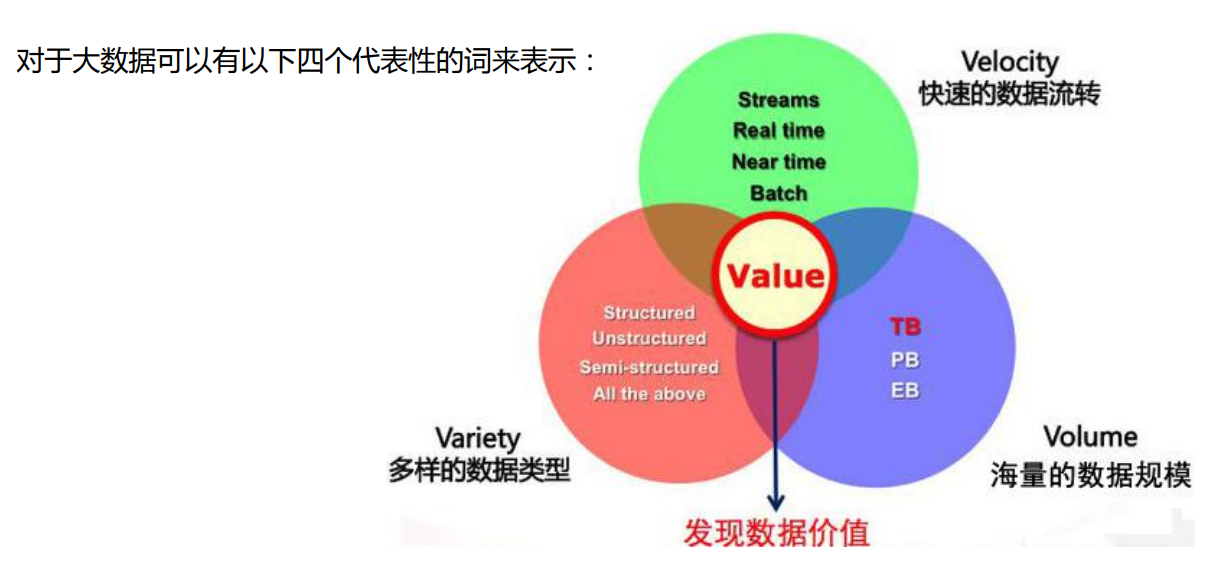
3.大数据的特性
大量的数据:PB级别
多样的数据类型
快速的数据流转
价值
二:学习的框架
1.官网:
hadoop.apache.org
目前学习的系列是Hadoop2.x,在2006年发布,几个重要的版本,2.2.0 ,2.5.0, 2.7.0
现在已经有了新的版本Hadoop3.0
2.特性
Hadoop是一个可靠性,可扩展,的分布式计算框架(The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.)。

A) 可靠性
存储方面:
HDFS存储策略,副本数为3个
以块进行,检验块损坏,生成校验码,并将两次的校验码进行比较来判断。
计算方面:
如果计算中出现问题,会使用副本数继续计算。
B) 可扩展性
可以在原有的基础上任意添加多台机器。
C) 低成本(另外补充)
磁盘的成本低一些。
3.四个核心模块

Hadoop Common:支持模块的工具类
HDFS:分布式文件系统
Hadoop YARN:任务调度和集群资源(内存,CPU)管理框架
Hadoop MapReduce:一个基于YARN的并行处理大数据集的框架
4.Hadoop之父
doug cutting
5.Hadoop的起源
apache Lucene:全文检索工具包
Apache Nutch:web搜索引擎
Google三大论文:MapReduce,GFS,BigTable
二:HDFS分布式文件系统
1.文件系统
建立在无数的硬件上。
设计理念:一次写入,多次读取
主从架构
namenode
datanode
存储的是文件,文件属性
名称,位置,副本数,拥有者,权限,存储的块
存储形式:块(block,默认是128M)
假设一个文件是250M,则需要两个块存储,第一个块128M,第二个块122M(一个文件小于一个数据块的大小,不需要占用整个数据块的空间的).
多个文件不能放到一个块中的。
文件的与元数据
文件的属性。
给到namenode进行存储。
真正存储的是datanode。
2.框架

3.HDFS读写流程(都有一个就近原则)(大概)
读取
客户端先去namenode,知道文件的存储位置。
再去找datanode。
当读取到好几个文件的时候,这个时候设计到就近原则,同一个机架上读取文件肯定比读取其他机架上的数据快。
读取块。
写入文件
首先客户端找namenode,知道文件将要被分到哪个位置
然后再找到对应的datanode
然后去datanode写入。
写副本时,应该需要写一个到别的机架。
4.HDFS服务功能
Namenode:是主节点,存储文件的元数据
Datanode:在本地文件系统存储文件数据,以及数据块的校验和。
Secondary Namenode:监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。
三:Hadoop YARN框架
1.框架

2.资源管理和调度框架
主从架构
Resourcemanager:管理整个集群的资源
NodeManager:资源所在
每个应用都有一个应用管理者:ApplicationMaster
container
使得应用不会被干扰,是资源的抽象,分装了每个任务需要的资源。
3.yarn的运行机制
当一个应用在yarn上运行,Resourcemanager首先会找一个nodemanager,给这个应用分配一个应用管理者(ApplicationMaster),使得应用管理者可以在nodemanager上运行。
然后管理者会计算出需要的资源,然后管理者根据计算出的资源向Resourcemanager申请资源
然后Resourcemanager给应用一个container,让应用在container中运行,
然后应用管理者进行监控和容错。
4.YARN服务功能

四:MapReduce框架
1.两个阶段
Map:并行输入数据
Reduce:对结果进行汇总
2.特点
适合离线批量计算
数据量大
启动开销大,每个mapreduce任务都会开一个Java虚拟机。
3.
最新文章
- unity 协程
- git 学习使用总结二(远程仓库操作)
- Jmeter—3 http请求—content-type与参数
- javascript优化--13模式1(DOM和浏览器模式)
- mongo导出导入
- 利用Velocity结合Spring发email
- typedef block
- Http Request Process
- phpEXCEL操作全解
- bzoj1633 [Usaco2007 Feb]The Cow Lexicon 牛的词典
- ImageMagick 压缩图片 方法
- Android应用中Back键的监听及处理
- JAXP的SAX解析
- 第一次AOP,附上使用DEMO,可用在简单生产环境了
- UOJ176 新年的繁荣
- MT【25】切线不等式原理及例题
- [转]MyEclipse内存不足问题
- C++之基于排序方法求一组数的中位数
- npm WARN unmet dependency问题的解决方法
- VS2017创建类库项目后添加不了WPF资源字典
热门文章
- kibana多台服务部署
- webapi框架搭建-安全机制(三)-简单的基于角色的权限控制
- codevs 3369 膜拜(线型)
- jenkins+testNg+maven+git+selenium自动化集成
- Java并发编程原理与实战十二:深入理解volatile原理与使用
- Java并发编程原理与实战四:线程如何中断
- Could not parse multipart servlet request; nested exception is java.io.IOException: The temporary upload location
- PartyPlay发布版
- 【codeforces】【比赛题解】#872 CF Round #440 (Div.2)
- Task多线程进行多进程