【DS】排序算法之插入排序(Insertion Sort)
2024-10-18 00:56:33
一、算法思想
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
1)从第一个元素开始,该元素可以认为已经被排序
2)取出下一个元素,在已经排序的元素序列中从后向前扫描
3)如果该元素(已排序)大于新元素,将该元素移到下一位置
4)重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
5)将新元素插入到该位置后
6)重复步骤2~5
如果比较操作的代价比交换操作大的话,可以采用二分查找法来减少比较操作的数目。该算法可以认为是插入排序的一个变种,称为二分查找排序。
二、算法示意图
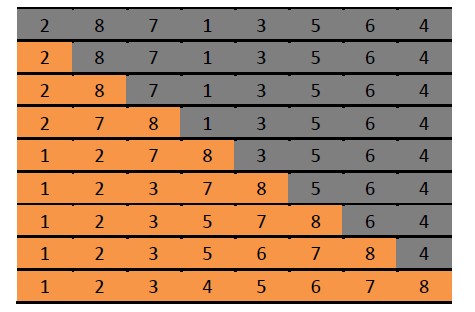
如图所示,阴影部分表示待排序的部分,黄色部分则代表已经排序好的序列。排序过程就是将阴影部分的第一个元素从后往前插入到黄色部分,同时不能破坏黄色部分的顺序。插入过程简述如下:
以第五行到第六行的变化为例,也就是将3插入到黄色部分的过程。3先和8比较,3<8,将8往后移动一格;然后3和7比较,3<7,将7往后移动一个;3和2比较,3>2,将3插入到7原来所在的地方。一趟完成。
三、Java代码
//@wiki
public class InsertionSort extends Sort{
public static void sort(int[] array) {
for (int index = 1; index < array.length; index++) {
int key = array[index];
int position = index;
// shift larger values to the right
while (position > 0 && array[position - 1] > key) {
array[position] = array[position - 1];
position--;
}
array[position] = key;
}
}
}
代码很好理解,不做解释。
四、算法复杂度
插入排序的算法复杂度很好分析,假设array的长度是n,外层for循环一共要执行n-1-1即n-2次,内层的while循环,最多执行index次,最少执行1次。因此其最坏的情况就是每次都执行Index次,其算法复杂度是n*(n-1)/2,即O(n^2),此时数组初始状态是倒叙排列的;最好的情况则是n-1次,即O(n)此时数组的初始状态是顺序排列的。平均时间复杂度为O(n^2)。
空间复杂度非常容易,由代码可以看出来,只需要一个位置key用于交换即可,因此是O(1)。
最新文章
- Windows Registry Security Check
- 说一下linux中shell的后台进程与前台进程
- POJ 2480 Longge's problem (积性函数,欧拉函数)
- dom 筛选器
- 个人收集的iOS开源动画-----长期跟新
- HDU 1672 Cuckoo Hashing
- asp.net(C#)写SQL语句技巧
- Linux下gcc,g++,gdb,scon部分用法笔记
- HDU 5692 (DFS序+线段树)
- 《深入理解Bootstrap》读书笔记(二)
- .NET Core微服务之基于Ocelot+IdentityServer实现统一验证与授权
- 处理范例代码Webapi中的Mongodb的Bson中ObjectId反序列化异常
- 使用Eclipse绑定Tomcat并发布应用
- SCRUM 12.19
- 多线程 死锁 wait(int i) notifyAll()
- effective c++ 笔记 (26-29)
- Beta阶段冲刺-3
- 一桩由X509Certificate2引发的血案
- Office/Visio/Project 2010 RTM (x86) (x64)(中文简体/英文)
- linux -- Ubuntu开启root账户,并切换到root用户登陆