[JVM 相关] Java 新型垃圾回收器(Garbage First,G1)
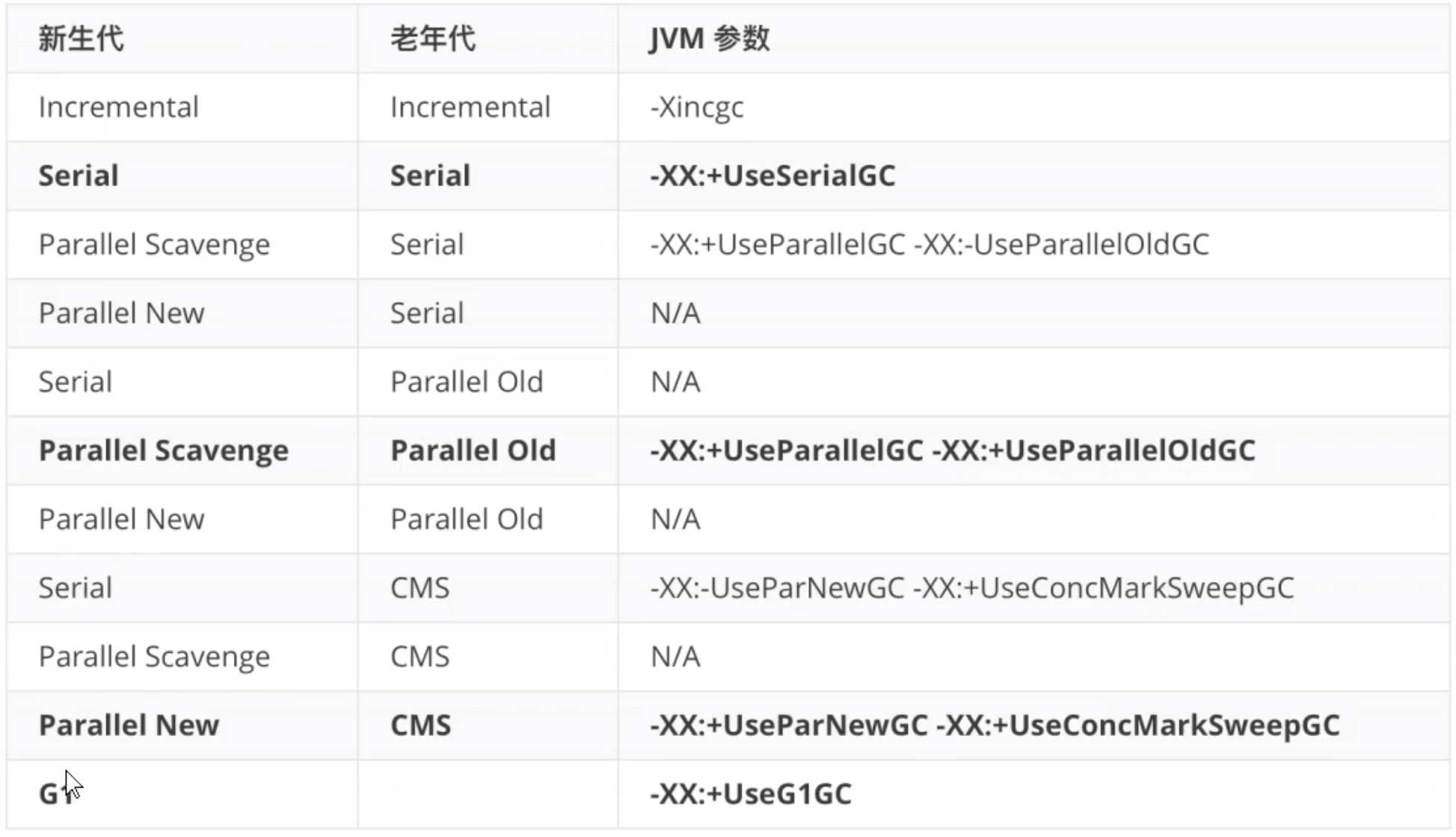
回顾传统垃圾回收器
- HotSpot 垃圾收集器实现
Serial Collector(串型收集器)
使用场景,大多数服务器是单核CPU。
适用收集场景:1. 新生代收集(Young Generation Collection)2. 老年代收集(Old Generation Collection)Parallel Collector(并行收集器)
又叫吞吐量收集器(throughput collector)应用于多核系统。
适用收集场景:1. 新生代收集是并行处理。2. 老年代收集和Serial Collector一样。Parallel Compacting Collector(并行压缩收集器)
The parallel compacting collector was introduced in J2SE 5.0 update 6. The difference between it and the parallel collector is that it uses a new algorithm for old generation garbage collection.
Note : Eventually, the parallel compacting collector will replace the parallel collector.
上述文字中斜体文字告诉我们,这个收集器和上一个并行收集器唯一的不同是在老年代使用了新的算法。
适用收集场景:1. 新生代收集(Young Generation Collector) 和Parallel Collector 相同;2. 老年代收集(Old Generation Collector)
Concurrent Mark-Sweep (CMS) Collector (并发标记清除)
> Young generation collections 通常不会造成长时间停顿,然而old generation collections却是是造成长时间停顿的,虽然它不长出现,特别是在大的heaps回收被涉及到的时候。为了处理这个问题,HotSpot JVM 引入了一个叫做concurrent mark-sweep(CMS) collector,通常也被称为低延时收集器low-latency collector.
> 适用场景: 仅适用于老年代,新生代处理方式和Parallel Collector相同。G1目标
G1 is planned as the long term replacement for the Concurrent Mark-Sweep Collector. 计划将G1作为CMS收集器的长久替代物。
它是为了平衡 延时和吞吐量之间的一种最优关系。G1实现原理
基本属性
和CMS的相同点
- CMS Replacement(CMS替代物)
- Server 'Style' Garbage Collector(服务端垃圾收集器-内存,核数区别)
- Parallel 并行
- Concurrent 并发
Generational 分代
和CMS的主要区别
- Good Throughput 良好的吞吐量
- Compacting 压缩
- Improved ease-of-use 提升了易用性(更多的JVM参数可用)
Predictable(though not hard real-time) 可预估的,非绝对实时。
基本概念
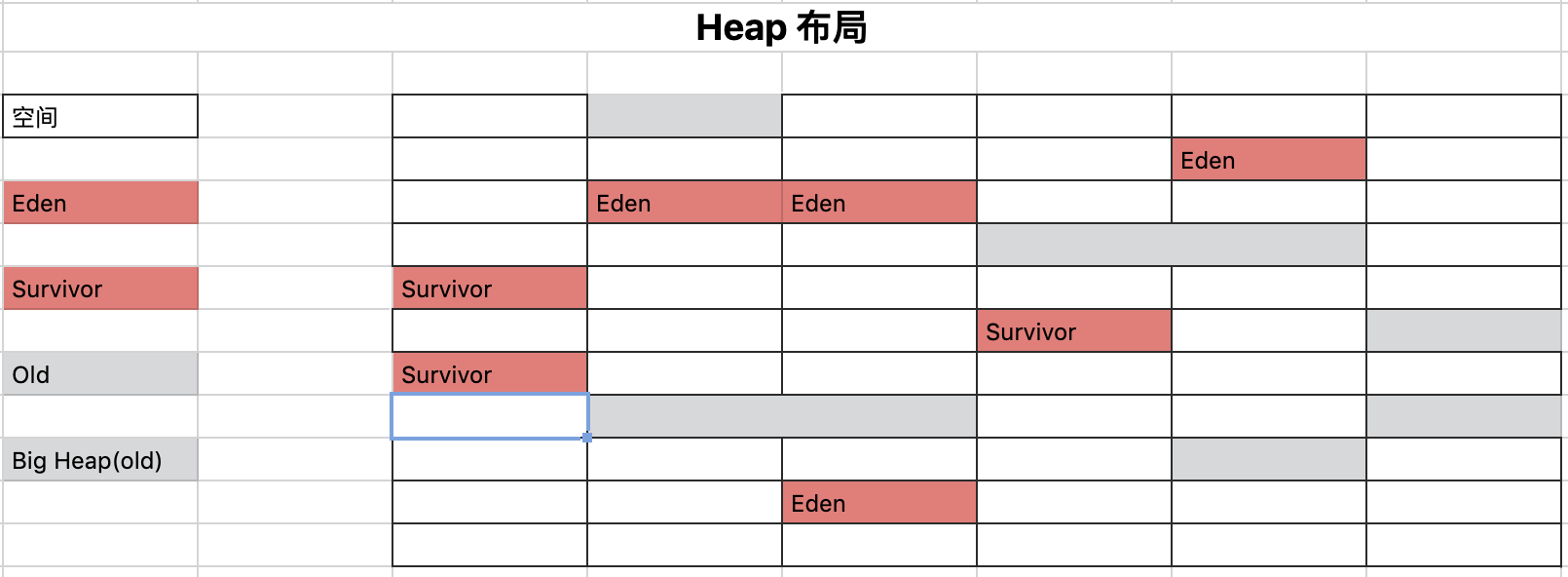
G1 堆布局
G1将堆分成若干固定大小的Region/区域(区域大小只有1、2、4、8、16和32M),G1的新生代和老年代都是一个无需连续的区域集合,每一个区域独立进行内存的分配和回收,区域是内存管理的基本单元,在某一个时间节点,可能是空闲的,当内存被请求时,内存管理器将空闲的Region分配到某个分代,然后归还应用分配给的空间。大多数情况下,GC的操作同一时间只会在一个区域进行。
Region 分布
超大对象(Humongous Objects)
下图中跨区域的灰色模块即代表了超大对象,超大对象是指那些空间大小>=1/2个区域空间的对象.超大对象有时候会被以下特殊方式处理:- 每个超大对象在老年代区域中的连续区域分配。对象分配起始于在连续区域中的首个成员,如果连续区域中的最后一个区域存在剩余空间的话,那么该空间将失去分配的机会,直到其关联的超大对象被完全回收
- 超大对象的回收通常仅在Cleanup停顿中的Marking结束后、或者在Full GC时。
- 超大对象的分配可能造成垃圾收集停顿过早地发生(主要是因为空间浪费。)
- 超大对象绝不会发生移动,即使在没有Full GC的情况下
- 回收周期
Young-only
Young-only 阶段的垃圾 收集 时逐渐地将老年代的对象填充到当前可用的内存。即将可以提升的新生代对象提升到老年代。
该阶段开始于Young-only的 收集 动作,也就是下图中的蓝色小球,每一个小球都是一次收集动作,也就是提升对象到老年代。Young-only 与Space-reclamation 过渡实际上是开始于老年代空间 *占用*达到某个阈值,即Heap初始化占用阈值。此时,G1将调度Initial Mark的Young-only收集(蓝色大球),而非常规的Young-only(蓝色小球)收集。- Initial Mark
此类收集开始于标记过程,附带一个常规的Young-only收集,并发标记决定所有在老年代区域中可达的存活对象是否要遗留到Space-reclamation 阶段。当标记过程未结束时,常规的Young-only 收集可能已经发生,等到标记完成时,将伴随着两个特殊的Stop-The-World停顿,Remark和CleanUp. Remark 停顿
因为在Initial Mark标记过程中,因为它是并发执行,有可能会发生Young-only收集,造成标记数据有误差,因此需要重新标记一次,该过程为串行执行,会造成Stop-The-World.在Remark 和Cleanup之间,G1将并发地计算出一份对象存活性总结报告,它将在Cleanup停顿阶段更新内部的数据结构
- Cleanup 停顿
该停顿同样将完整的回收空闲区域,并且决定Space-reclamation阶段是否需要继续跟踪,如果继续跟随的话,Young-only阶段的完成仅仅做Young-only收集动作。
- Initial Mark
Space-reclamation
Space-reclamation(空间回收/复用)阶段是回收老年代空间,同时处理新生代。
这个阶段由多个混合的收集动作组成,不仅包含新生代区域,同时也会排除老年代区域的存活对象,当G1发觉依然无法满足空闲的空间请求时,G1会终止本阶段。如果应用消耗完内存,G1将执行Stop-The-World的全堆压缩(Full GC)。
如下图所示:
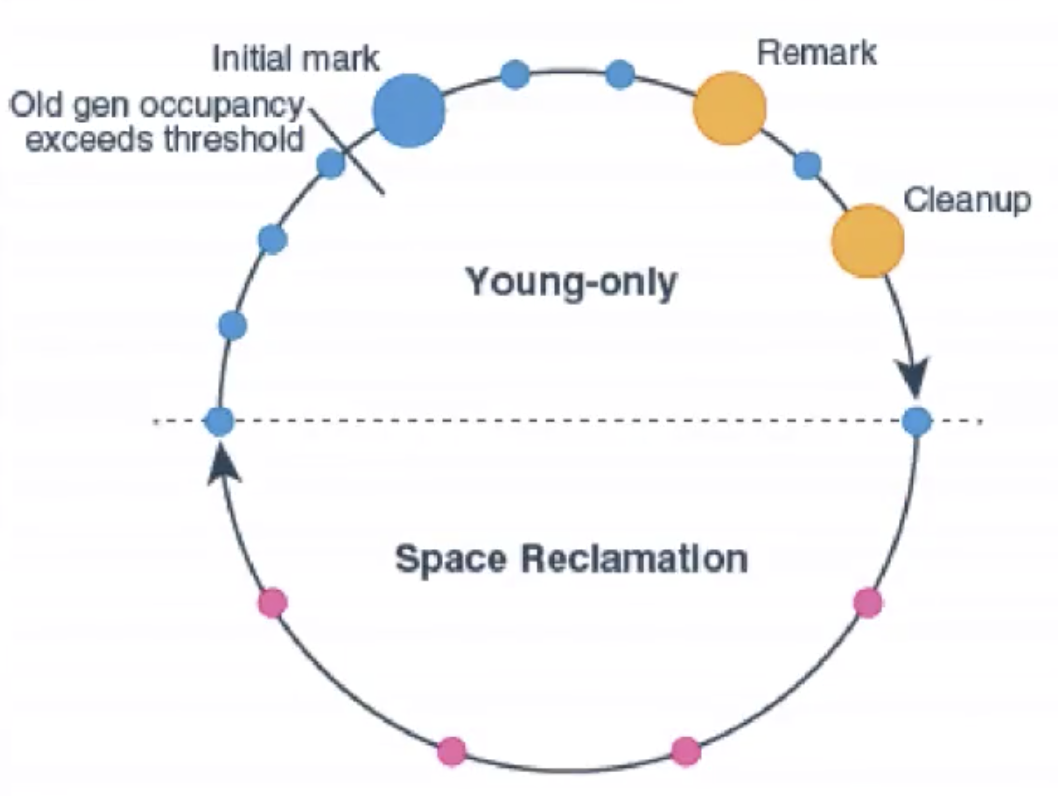
2种过程是循环往复收集。G1指令细节
初始空间占用
Initiating Heap Occupancy Percent(IHOP): Initial Mark 收集触发的阈值,为老年代空间定义Heap占用的百分比。
JVM 设置参数:-XX:InitiatingHeapOccupancyPercent
默认情况下,根据标记时间以及老年代在标记周期中的内存分配,G1垃圾收集器将自动抉择理想的IHOP的值。
JVM 失效参数:-XX:-G1UseAdaptiveIHOP
修改区域空间大小
-XX:G1HeapRegionSize
G1 Vs. 传统垃圾回收器
- G1 不区分新/老生代,只区分Region
- G1 收集分2个阶段
Young-only和Space-reclamation
最新文章
- Java 设计模式之代理模式
- Lintcode: Sort Colors II
- linux系统中实现mongodb3.0.5数据库自动备份
- Windows Phone性能优化建议
- chm文件打开,有目录没有内容
- Android开发手记(27) Java多线程的操作
- 网址测速JS
- Error in invoking target 'agent nmhs' of makefile
- 解决基于BAE python+bottle开发上的一系列问题 - artwebs - 博客频道 - CSDN.NET
- 解决exlipse下 springboot 错误:找不到或无法加载主类
- C# 操作docx文档
- 【ERROR】ERROR: transport error 202: bind failed: Cannot assign requested address
- Crane (POJ 2991)
- Java并发编程:Java的四种线程池的使用,以及自定义线程工厂
- Spark、Hadoop、Hive相关文章
- 浅谈Session与Cookie的区别与联系
- Python中*args和**kwargs的区别
- CentOS7安装OpenStack(Rocky版)-09.安装Cinder存储服务组件(控制节点)
- 大数据入门第八天——MapReduce详解(四)本地模式运行与join实例
- PHP Socket 简单使用