SSH框架整合截图总结(三)
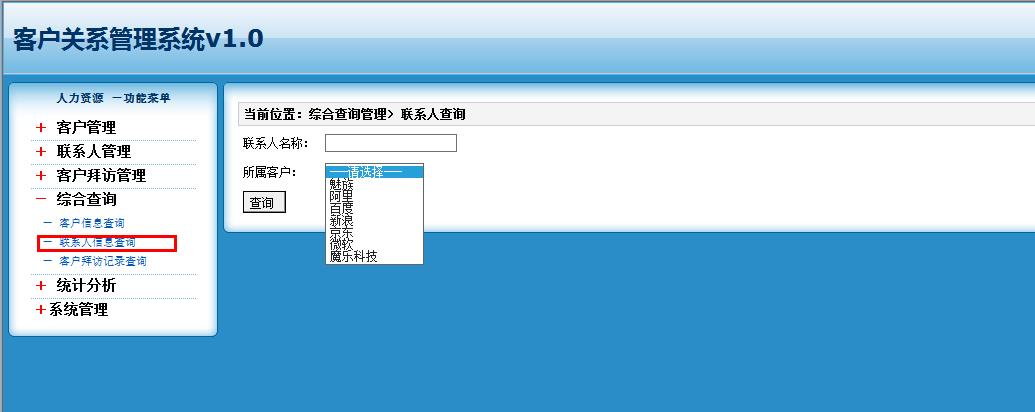
联系人信息查询
1 点击 联系人信息查询 超链接时候,到查询页面
(1)在查询页面中,选择客户,根据客户进行查询

下拉表框显示所有客户 可以根据所属的客户进行联系人查询

2 在查询页面中,输入值,提交表单到action,查询数据库得到结果
使用字符串拼接方式:
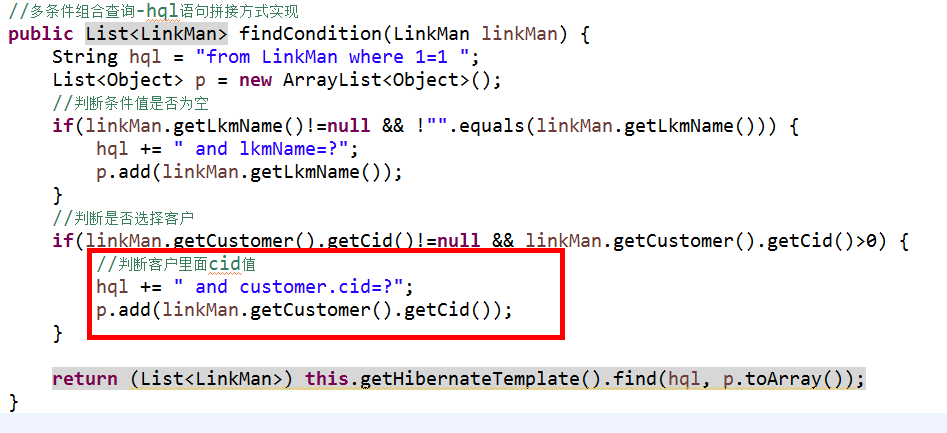
使用离线对象实现查询
字符串拼接方式代码:
界面效果:
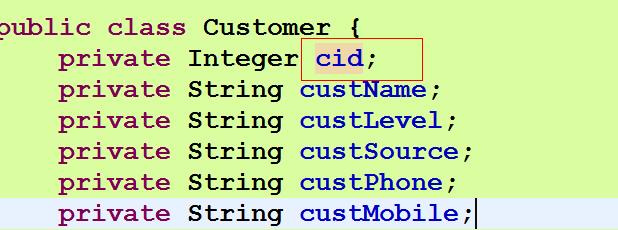
两个model关系:

点击超接连首先进入查询页面 需要做的工作就是把所有客户都查询出来,并且带查询页面上使用下拉表框进行显示

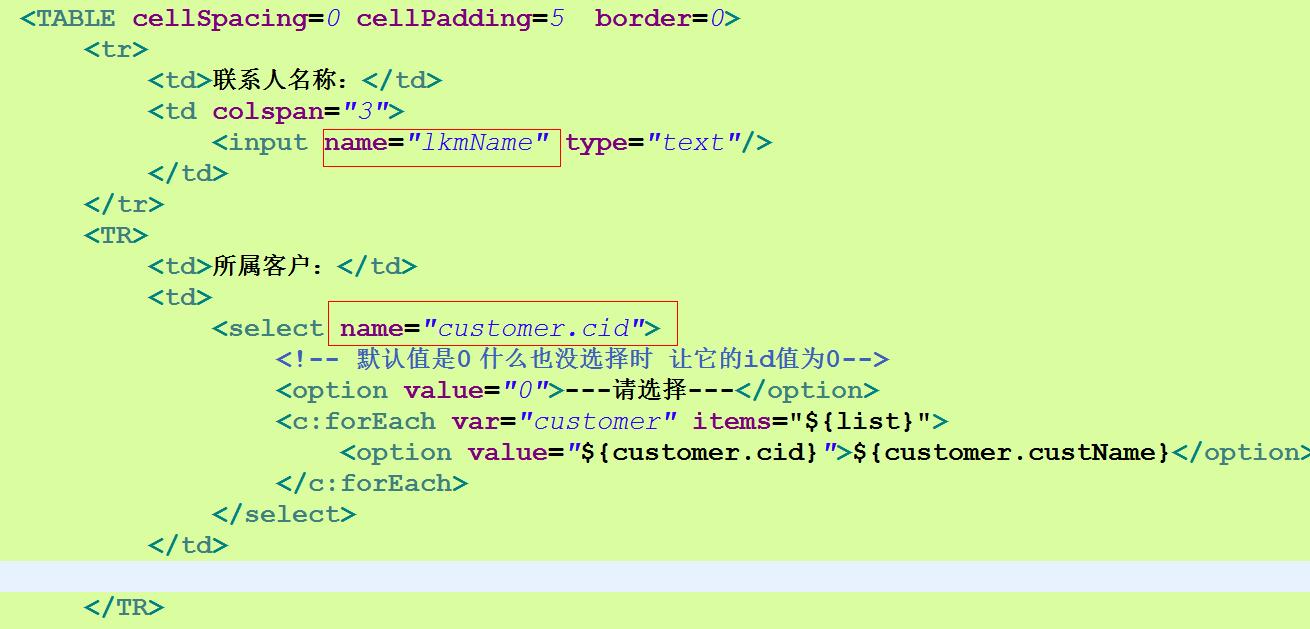
用户输入内容或者不输入 点击查询之后 把数据(没有数据将来查询时 就是查询全部信息)提交给action 使用模型驱动完成数据的封装
action中调用service service调用dao中的方法

最终daoimpl中的方法:

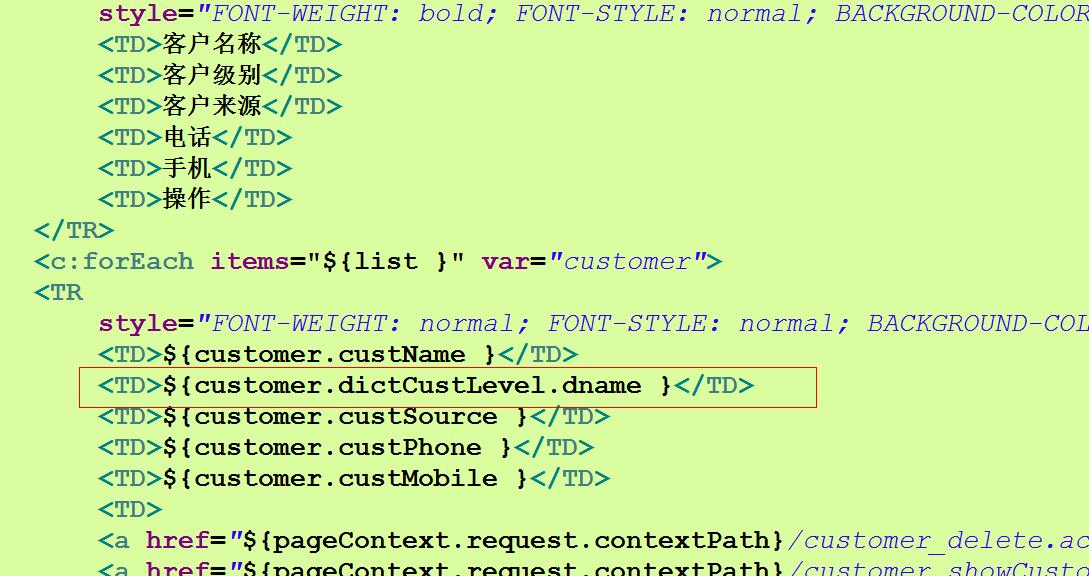
最后把符合条件的数据保存在域对象中,在联系人列表页面进行显示
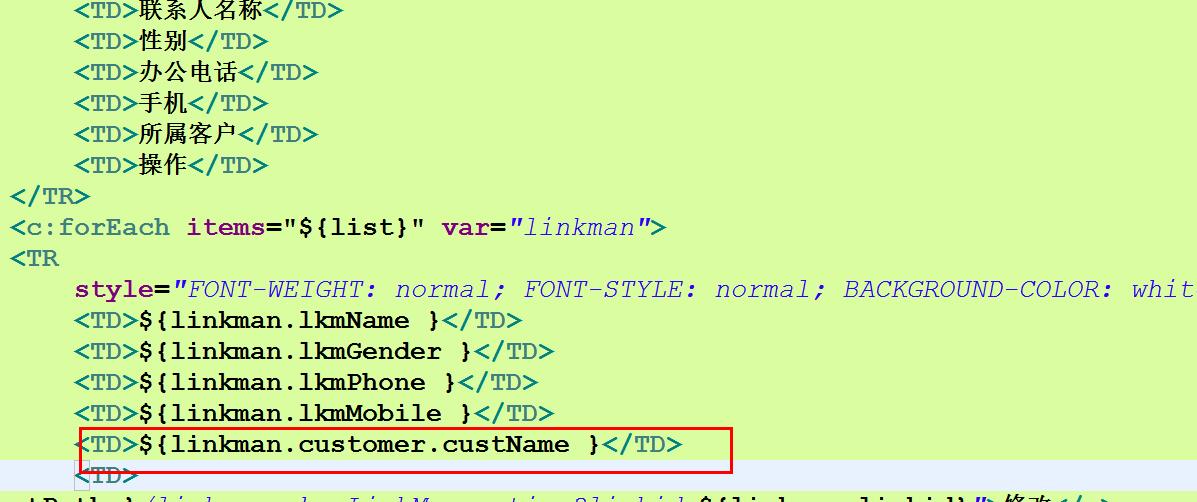
思考一下:上面画红线的地方需要注意什么?
需要避免出现no-session的问题,因为底层(使用hibernateTemplate是对session对象的封装)的得到的session是与本地线程绑定的session 所以在daoimpl调用完成之后session就自动关闭了,即使不手动关闭。又因为hibernate的优化机制,即“懒加载机制” ,数据在真正使用到的时候才会再去查数据库,这就造成在session已经关闭情况下,上面的页面需要显示的数据需要再次查询数据库时,报错no-session 解决办法2种(详见 SSH总结一)
第一种 推荐:在web.xml中配置一个session延迟关闭的过虑器
第二种 可能影响性能 在对象关系映射文件中 配置lazy="false" 属性 不让它懒加载 这个值默认是true 不配置的情况下 默认懒加载 这样就会在查询的时候,直接把关联的对象也查询出来了,将来在数据显示的时候就不需要再次查数据库了
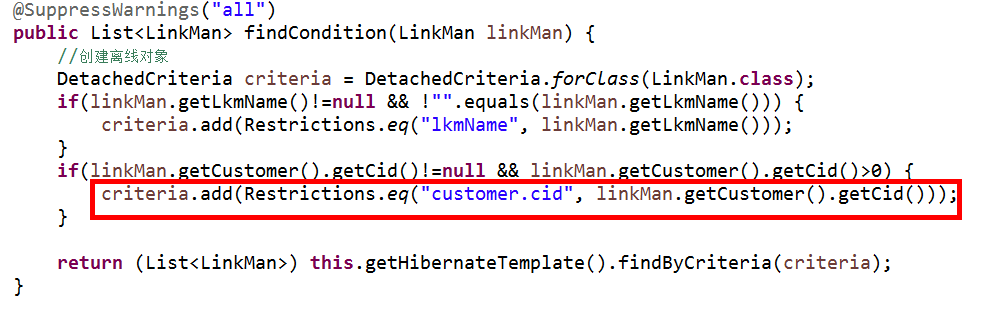
创建离线对象方式代码:
其他过程不变,使用离线对象,改变daoimpl中的代码
public List<LinkMan> finCondition(LinkMan linkMan) {
/*
List<Object> p=new ArrayList<Object>();
//先使用构造hql语句的方式 进行查询
String hql="from LinkMan where 1=1";
//判断输入的值是否为空
if(linkMan.getLkmName()!=null&&!"".equals(linkMan.getLkmName())){
//注意 hql语句中都是对实体类进行操作 表名变为对应的实体类名 字段名变为对应属性名
//即 LinkMan不是数据库中的表名 而是将要操作的表对应的实体类的名称 包括下面的lkmName也是实体类中的属性名称
hql += " and lkmName=?";
p.add(linkMan.getLkmName());
}
//判断id是否选择 如果选择了id就不为空 并且大于0 因为在表单提交的时候如果用户没选择 那么就将id的值默认为0
//这里关键是怎么拼接字符串 因为id的属性值是保存在linkman中的customer对象中的cid属性中
if(linkMan.getCustomer().getCid()!=null&&linkMan.getCustomer().getCid()>0){
//如果不为空 那么就进行字符串的拼接
hql += " and customer.cid=?";
p.add(linkMan.getCustomer().getCid());
}
return (List<LinkMan>) this.getHibernateTemplate().find(hql,p.toArray());
*/
//第二种方式 使用离线对象 完成多条件查询:
//表示对LinkMan实体类进行操作
DetachedCriteria criteria=DetachedCriteria.forClass(LinkMan.class);
//增加条件限制
if(linkMan.getLkmName()!=null&&!"".equals(linkMan.getLkmName())){
criteria.add(Restrictions.eq("lkmName",linkMan.getLkmName()));//第一个参数 是实体类中的属性名 不要认为是表中的字段名 因为hibernate操作全部都是对实体类进行的操作
}
if(linkMan.getCustomer().getCid()!=null&&linkMan.getCustomer().getCid()>0){
//这里customer.cid 表示linkman实体类中的customer属性 customer中cid属性 和拼接hql语句时一样
criteria.add(Restrictions.eq("customer.cid",linkMan.getCustomer().getCid()));
}
return (List<LinkMan>) this.getHibernateTemplate().findByCriteria(criteria);
}
无论是拼接还是离线方式 ,主要就是注意第二个限制条件的书写方式
---------------------------------------------------------------------------
添加数据字典表
1 什么是数据字典表
(1)存储基础数据
- 比如添加客户信息时候,添加客户级别,这个级别不能随便输入,把客户级别存到数据字典表里面,添加时候,查询数据字典所有记录显示
(2)码表
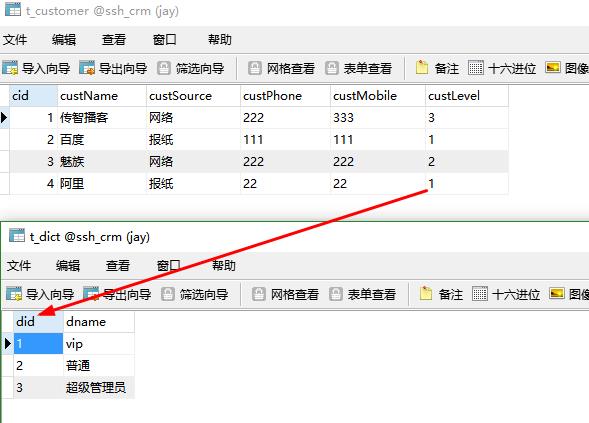
2 数据字典表 和 客户表之间关系是 一对多关系
(1)数据字典表是一
(2)客户表示 多
- 一个级别里面可以有多个客户,一个客户只能属于一个级别
(3)让数据字典表对应一个实体类
- 配置数据字典表和客户表关系


2 配置数据字典和客户映射关系
(1)需求:根据客户查询级别,没有根据级别查询客户的需求
(2)只需要在客户实体类表示所属级别

(3)在映射文件中表示关系
- 在客户映射文件中,配置所属级别就可以了

3 功能分析
(1)到添加客户页面中,在下拉列表中把所有级别显示

(2)点击保存,把数据添加到数据库里面
- 使用模型驱动封装得到值
然后调用方法执行保存
部分代码:
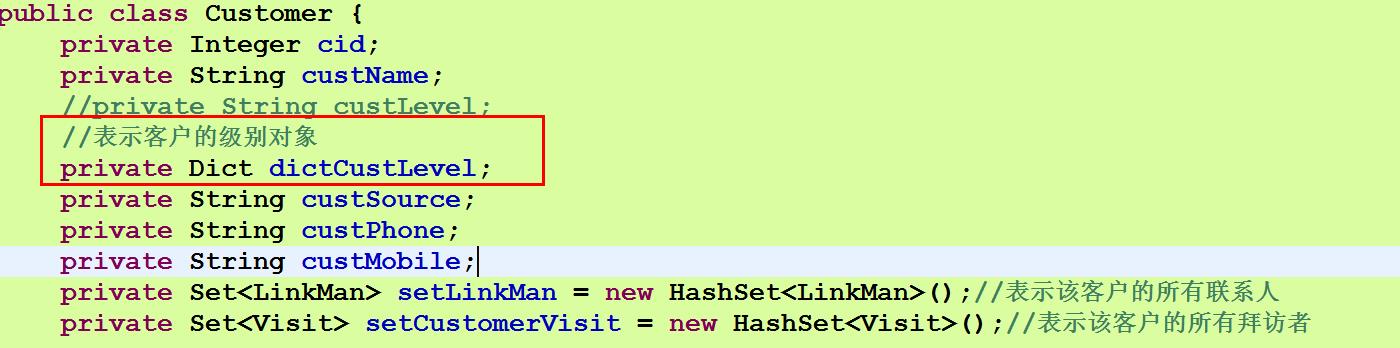
客户级别实体类Dict
package org.model;
public class Dict {
//因为需求是通过客户得到级别 没有得到某个级别的所有客户的需求 所以这里不需要配置set集合 来表示某个级别的所有客户
private String did;
//主键生成策略就不能是native类型了
//native是根据使用的数据库 设置值 mysql数据库 自动增长 并且id的类型是int类型
private String dname;
public String getDid() {
return did;
}
public void setDid(String did) {
this.did = did;
}
public String getDname() {
return dname;
}
public void setDname(String dname) {
this.dname = dname;
}
}
对应映射配置文件

客户实体类Customer
对应映射配置文件

点击超链接进入add.jsp页面 ,在该页面需要把所有级别信息显示出来供用户进行选择,所以需要在跳转的action中先把信息检索出来并且保存在域对象中

add.jsp

运行效果:
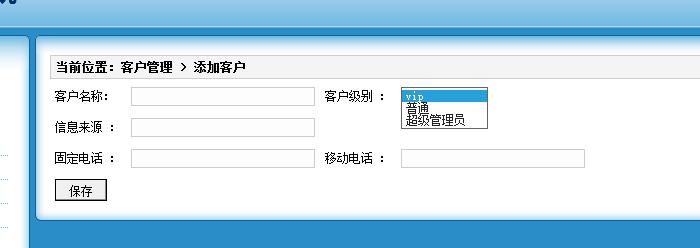
输入信息并且选择客户的级别点击保存,使用模型驱动完成数据的封装工作,然后调用方法进行保存


添加完成之后,跳到列表页面进行显示
-------------------------------------------------------------------
主键生成策略

------------------------------------------------------------------------------------------------------
统计分析
1 系统中可能有复杂查询操作,使用hibernate不能实现,需要调用普通sql语句实现
(1)在dao里面使用hibernate模板,使用hibernate模板调用普通sql

(2)根据客户级别统计
- 只使用客户表统计效果,客户级别显示的是id值而不是名称,但是希望显示客户级别名称

客户表和数据字典表多表查询操作

2 统计查询之后,返回多条记录,每条记录里面有两个值,返回list集合,
但是list里面泛型没有实体类封装,让list里面的泛型是map集合
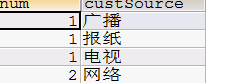
根据客户来源统计
(1) 调用底层sql
(2) 把返回结果转换map结构
(3) 在页面中显示list集合内容(list里面每部分是map结构)

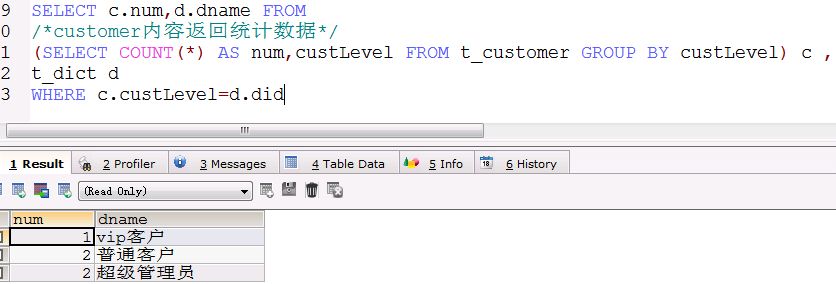
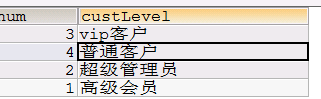
根据客户级别统计
1 在dao里面调用普通sql语句


返回list集合,list集合中每部分是数组形式

让list每部分是对象形式

但是返回结果只有两个值,没有对应对象
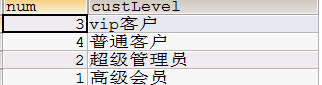
把list中每部分转换成map集合


2 在jsp中得到list集合内容
(1)遍历list集合,得到list里面多个map集合,根据map的key得到value值
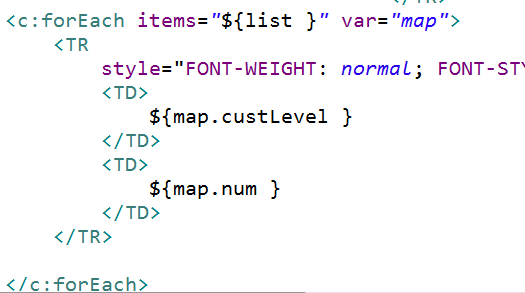

代码实现(根据客户来源进行统计):
点击超链接进入action中,进行数据检索

action调用service,service调用dao中的方法进行查询,都比较简单

值得注意的是dao实现类中的方法
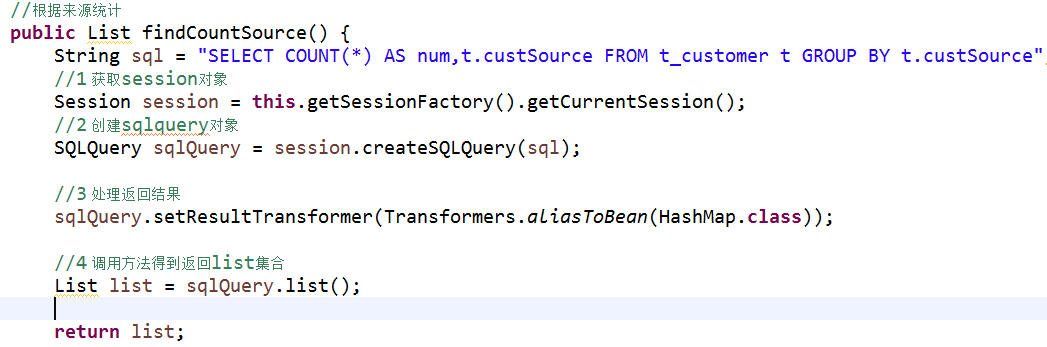
//根据客户来源查询
public List findCountSource() {
//因为查询的操作中牵涉分组 统计 以及连接查询 所以需要创建SQLQuery对象使用sql语句来完成操作
//1.得到session对象
Session session=this.getSessionFactory().getCurrentSession();
//2创建SQLquery对象 里边写的是sql语句
SQLQuery sqlQuery=session.createSQLQuery("select count(*) num,custSource from t_customer group by custSource");
8 //该对象list方法查询之后返回的是一个数组集合的形式
9 //为了取值方便 下面把他转换成map类型
sqlQuery.setResultTransformer(Transformers.aliasToBean(HashMap.class));
//调用方法得到的集合就是一个map结构
List list=sqlQuery.list();
return list;
}
显示页面

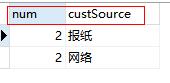
底层sql查询出来的num,custSource都作为了map中的key,多条记录,每条记录都是下面这种形式

代码实现(根据客户级别进行统计):
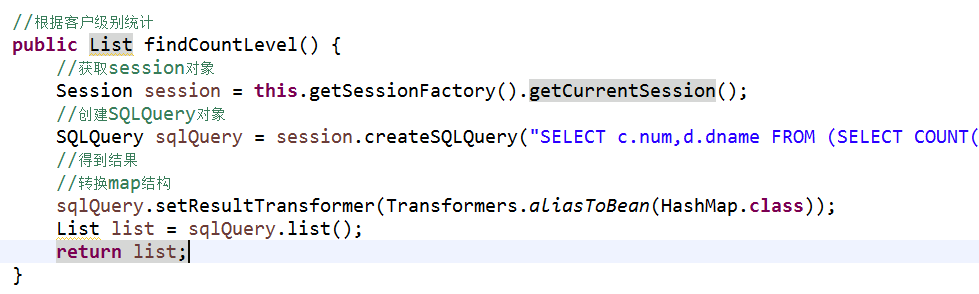
思路和上边的一样 dao实现类中的方法
//根据级别查询
public List findCountLevel() {
//1.得到session对象
Session session=this.getSessionFactory().getCurrentSession();
//2创建SQLquery对象
SQLQuery sqlQuery=session.createSQLQuery("select count(*) num,d.dname from t_customer as c,t_dict as d where c.custLevel=d.did group by d.did");
//该对象list方法查询之后返回的是一个数组集合的形式
//为了取值方便 下面把他转换成map类型
sqlQuery.setResultTransformer(Transformers.aliasToBean(HashMap.class));
//调用方法得到的集合就是一个map结构
List list=sqlQuery.list();
return list;
}
显示页面

key值
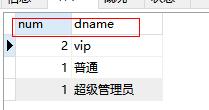
底层sql查询出来的字段名称,都作为map中的key值
最新文章
- Cocoapods - pod install 成功后找不到头文件解决
- gradle构建android项目
- Cognos 增加全局类
- How to create a PPPoE Server on Ubuntu? (Untested)
- C++ 操作 MySQL
- Spring源码情操陶冶-AbstractApplicationContext#onRefresh
- XML预览
- Ubuntu下OpenGL开发环境的搭建
- 为eclipse离线安装hibernate tools插件
- python---进程与线程
- HTML5 全屏 API
- C++语言之动态内存分配
- Django+xadmin打造在线教育平台(九)
- IntelliJ IDEA(九) :酷炫插件系列
- WC2019 题目集
- linux系统学习方法分享
- jenkins之 pipeline 小尝试
- [记录] CSS 多行文本超出部分省略
- day 18 类,对象
- [转]C#鼠标拖动任意控件