Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计
通过使Scrapy框架,进行数据挖掘和对web站点页面提取结构化数据,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求,使得我们的爬虫更强大、更高效。
熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析。同时,使用Weka 3.7工具,对所获取得到的数据进行数据挖掘分析操作。
一、项目分析
本次的实验内容要求使用scrapy框架,爬取腾讯招聘官网中网页(https://hr.tencent.com/position.php?&start=0)上所罗列的招聘信息,如:其中的职位名称、链接、职位类别、人数、地点和发布时间。并且将所爬取的内容保存输出为CSV和JSON格式文件,在python程序代码中要求将所输出显示的内容进行utf-8类型编码。
1. 网页分析
在本例实验开始之前,需要对所要求爬取的腾讯招聘网页进行网页分析,其中(https://hr.tencent.com/position.php?&start=0)的界面布局结构可如图2-1所示:
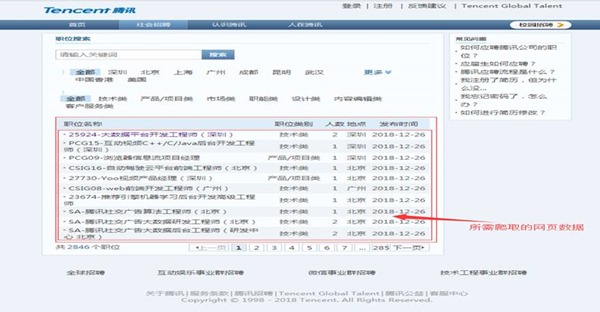
图1-1 所要爬取的信息页面布局
使用xpath_helper_2_0_2辅助工具,对其中招聘信息的职位名称、链接、职位类别、人数、地点和发布时间等信息内容进行xpath语法分析如下:
职位名称: //td[@class='l square']/a/text()
链 接: //td[@class='l square']/a/@href
职位类别://tr[@class='odd']/td[2]/text()|//tr[@class='even']/td[2]/text()
人 数://tr[@class='odd']/td[3]/text()|//tr[@class='even']/td[3]/text()
地 点://tr[@class='odd']/td[4]/text()|//tr[@class='even']/td[4]/text()
发布时间://tr[@class='odd']/td[5]/text()|//tr[@class='even']/td[5]/text()
2. url分析
scrapy 是一个为了爬取网站数据,提取结构性数据而编写的应用框架,我们只需要实现少量代码,就能够快速的抓取到数据内容。
首先程序将需要发送请求的url(requests)经ScrapyEngine(引擎)交给Scheduler(调度器)。在Scheduler(排序,入队)处理后,经ScrapyEngine,DownloaderMiddlewares交给Downloader,再向互联网发送请求,并接收下载响应(response)。
最后,将响应(response)经ScrapyEngine,SpiderMiddlewares(可选)交给Spiders的同时。Spiders处理response,提取数据并将数据经ScrapyEngine交给ItemPipeline保存,提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
二、项目工具
实验软件:Python 3.7.1 、 JetBrains PyCharm 2018.3.2 、 其它辅助工具:略
三、项目过程
(一)使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析,绘制如图3-1所示的程序逻辑框架图
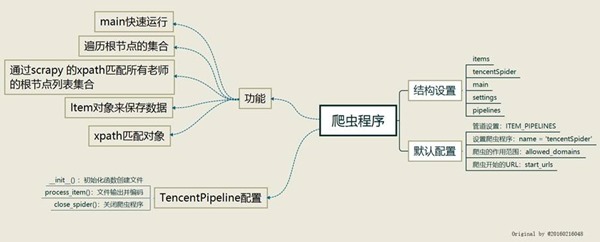
图3-1 程序逻辑框架图
(二)爬虫程序调试过程BUG描述(截图)
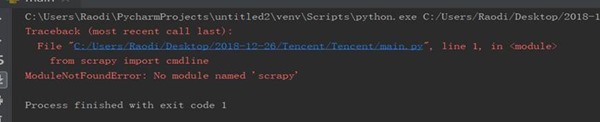
图3-2 爬虫程序BUG描述①

图3-3 爬虫程序BUG描述②
(三)爬虫运行结果
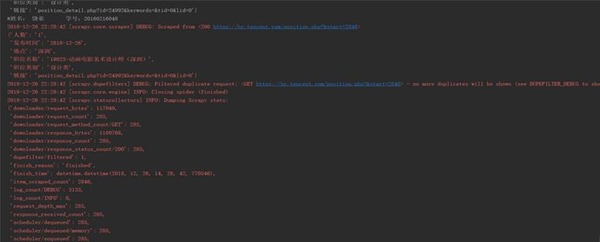
图3-4 爬虫程序输出运行结果1
图3-5 爬虫程序输出文件
四、项目心得
关于本例实验心得可总结如下:
1、 解决图3-4的程序错误,只需在gec.py的文件中进行导入操作:from Tencent.items import TencentItem 即可。对于解决如图4-1所示的内容,请如图5-1所示:
图4-1 程序错误纠正
2、 spider打开某网页,获取到一个或者多个request,经由scrapy engine传送给调度器scheduler request特别多并且速度特别快会在scheduler形成请求队列queue,由scheduler安排执行
3、 schelduler会按照一定的次序取出请求,经由引擎, 下载器中间键,发送给下载器dowmloader 这里的下载器中间键是设定在请求执行前,因此可以设定代理,请求头,cookie等
4、 下载下来的网页数据再次经过下载器中间键,经过引擎,经过爬虫中间键传送给爬虫spiders 这里的下载器中间键是设定在请求执行后,因此可以修改请求的结果 这里的爬虫中间键是设定在数据或者请求到达爬虫之前,与下载器中间键有类似的功能
5、 由爬虫spider对下载下来的数据进行解析,按照item设定的数据结构经由爬虫中间键,引擎发送给项目管道itempipeline 这里的项目管道itempipeline可以对数据进行进一步的清洗,存储等操作 这里爬虫极有可能从数据中解析到进一步的请求request,它会把请求经由引擎重新发送给调度器shelduler,调度器循环执行上述操作
最新文章
- html5+css+div随时笔记
- [NHibernate]HQL查询
- 上传图片插件鼠标手cursor:pointer;不生效
- 获取当前正在执行的Javascript脚本文件的路径
- Linux文件权限;ACL;Setuid、Setgid、Stick bit特殊权限;sudo提权
- ALV详解:OO ALV
- NABCD分析
- LeetCode OJ Symmetric Tree 判断是否为对称树(AC代码)
- Javascript之日历
- POJ 3107-Godfather(树形dp)
- iOS 证书与签名 解惑详解
- 【IOS开发笔记01】学生管理系统(上)
- MySQL用户认证及权限grant-revoke
- [2013-06-05]bat脚本设置DNS
- 【汇编语言】Doxbox 0.74 修改窗口大小
- 基于Asp.Net Core 2.1的简单问答社区系统源代码分享
- Oracle 11g rac 添加新节点测试
- asm磁盘组,asm磁盘状态学习
- (转)无效的CurrentPageIndex 值。它必须大于等于0 且小于PageCount 解决方案
- C++ new动态数组初始化