python爬虫的基本思路
2024-08-30 18:34:50
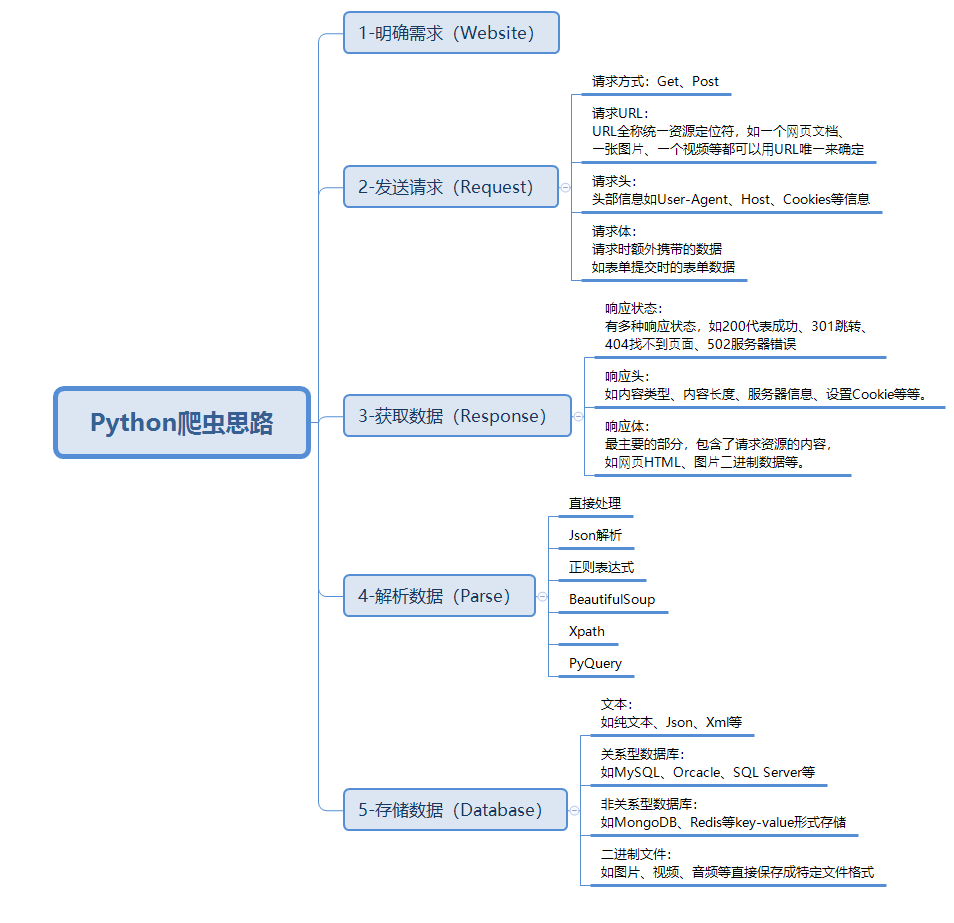
爬虫:请求网站并提取数据的自动化程序。
流程: 发送请求 -> 获取数据 -> 解析数据 -> 存储数据
最新文章
- [转]How do you create a custom AuthorizeAttribute in ASP.NET Core?
- FPGA与simulink联合实时环路系列——实验三 按键key
- js打字机效果实现
- 《CSS3实战》读书笔记 第三章:选择器:样式实现的标记
- 获取iframe的元素并进行操作
- 读书笔记 1 of Statistics :Moments and Moment Generating Functions (c.f. Statistical Inference by George Casella and Roger L. Berger)
- hiho一下第91周《Events Arrangement》(前半部分)
- Apache Kafka源码分析 - autoLeaderRebalanceEnable
- Duilib扩展《01》— 双击、右键消息扩展
- PBOC电子钱包与电子现金及QPBOC
- VS2015中DataGridView的DataGridViewComBoboxCell列值无效及数据绑定错误的解决方法
- CENTOS6 下MATLAB2014b的安装和破解(Matlab_R2014b linux版 安装笔记)
- HTML5 <Audio/>标签Api整理(二)
- BZOJ 1051: [HAOI2006]受欢迎的牛( tarjan )
- ASP.NET程序发布流程
- Base algorithm
- 对bootstrap不同版本的总结
- Linux应该知道的技巧
- Android Studio 增加按钮响应事件
- VMware12创建新的虚拟机及设置硬件环境