利用python实现《数据挖掘——概念与技术》一书中描述的Apriori算法
2024-08-25 11:22:16
from itertools import combinations data = [['I1', 'I2', 'I5'], ['I2', 'I4'], ['I2', 'I3'], ['I1', 'I2', 'I4'], ['I1', 'I3'],
['I2', 'I3'], ['I1', 'I3'], ['I1', 'I2', 'I3', 'I5'], ['I1', 'I2', 'I3']] # 候选集生成
# 输入:
# f_set: k-1项集, k:项集个数
# 输出:
# k_cand:k项候选集
def apriori_gen(f_set, k):
k_cand = []
temp = [frozenset(l) for l in combinations(f_set, k)]
for t in temp:
if has_infrequent_subset(t, f_set):
del t
else:
k_cand.append(t)
return k_cand # 非频繁项集的超集也是非频繁的
def has_infrequent_subset(c_set, f_set):
for subset in c_set:
if not frozenset([subset]).issubset(f_set):
return True
return False # 输入(绝对)最小支持度, min_sup
# 输出:全部频繁项集(不包括一项集), all_f_set
def get_f_set(min_sup=2):
all_f_set = []
L1 = frozenset([d for ds in data for d in ds])
k = 2
size = len(L1)
while k <= size:
c_k = frozenset(apriori_gen(L1, k))
for c in c_k:
count = 0
for d in data:
if c.issubset(frozenset(d)):
count += 1
if count >= min_sup:
all_f_set.append((c, count))
k += 1
return all_f_set if __name__ == '__main__':
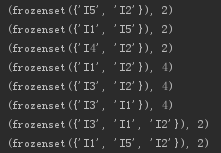
all_frequent_set = get_f_set()
for i in all_frequent_set:
print(i)
最新文章
- Activityn 生命周期
- hasSet,TreeSet,ArrayList,LinkedList,Vector,HashMap,HashTable,TreeMap利用Iterator进行输出
- Google Code Jam 2014 Round 1B Problem B
- ECshop中TemplateBeginEditable 和后台编辑讲解
- tq --uboot使用
- memcached在windows安装
- 【Chromium中文文档】安全浏览 -- Chrome中的警告都是怎么来的?
- VUE2.0实现购物车和地址选配功能学习第四节
- Time模块和datetime模块
- 新建VS工程与填坑:解决方案与项目不在同一目录
- JS闭包以及作用域初探
- Visual Studio中的.suo(Solution User Options)文件
- [转] 谈谈JS中的函数节流
- sql日期格式小应用 记录一下
- gb2312提交的url编码转换成utf8的查询
- java 标签编译后没有显示
- ChIP-seq实战 | 染色质免疫共沉淀技术 | ATAC-seq | 染色质开放性测序技术
- APIcloud制作APP 微信支付与支付宝支付
- BZOJ 4198: [Noi2015]荷马史诗 哈夫曼树 k叉哈夫曼树
- PHP——大话PHP设计模式——魔术方法