Boosting&Bagging
Boosting&Bagging
集成学习方法不是单独的一个机器学习算法,而是通过构建多个机器学习算法来达到一个强学习器。集成学习可以用来进行分类,回归,特征选取和异常点检测等。随机森林算法就是一个典型的集成学习方法,简单的说就是由一个个弱分类器(决策树)来构建一个强分类器,从而达到比较好的分类效果。
那么如何得到单个的学习器,一般有两种方法:
- 同质(对于一个强学习器而言,所用的单个弱学习器都是一样的,比如说用的都是决策树,或者都是神经网络)
- 异质(相对于同质而言,对于一个强学习器而言,所用的单个弱学习器不全是一样的,比如说用的决策树和神经网络的组合)
相对异质而言,同质学习期用的最为广泛,我们平时所讨论的集成学习方法指的就是同质个体学习器,同质个体学习器按照个体学习器之间的依赖关系分为串行(有强依赖关系)和并行(不存在关系或者有很弱的依赖关系),而在串行关系中有代表性的就是boosting系列算法,并行关系中具有代表性的就是bagging和随机森林(random forest)
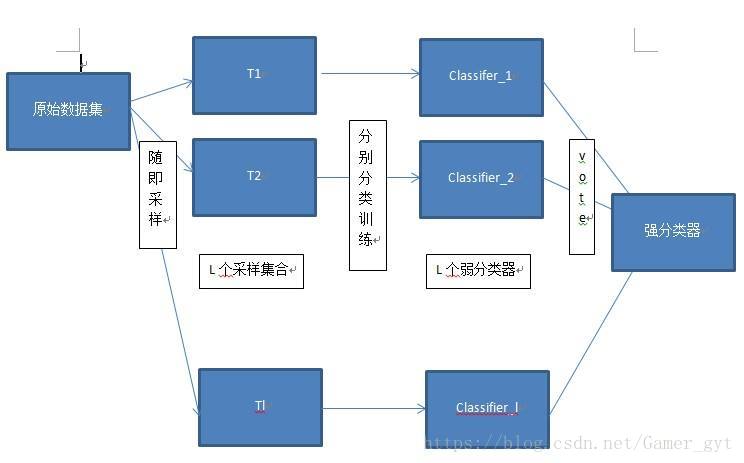
Boosting流程图
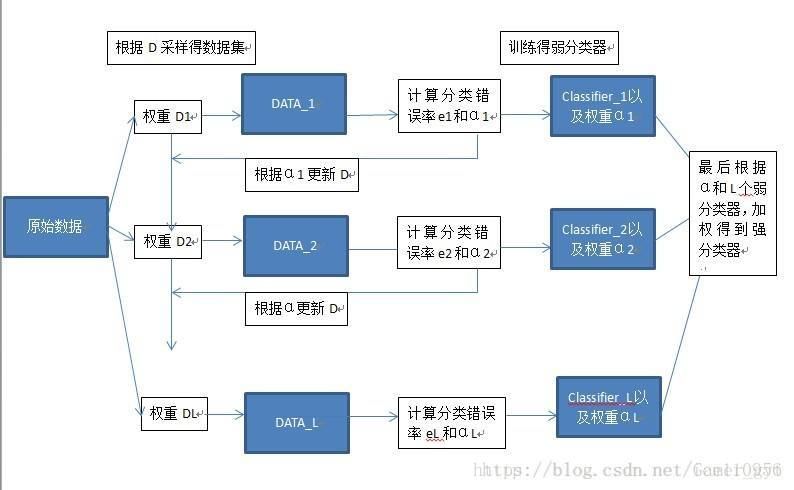
Bagging流程图
上边简单的介绍了集成学习方法和boosting&bagging的区别,那么对于单个学习器采用何种策略才能得到一个强学习器呢?
- 平均法(加权(个体学习器性能相差较大),简单(性能相近))
- 投票法(绝对多数(超过半数标记。否则拒绝预测),相对多数,加权投票)
- 学习法(通过另一个学习器来进行结合,Stacking算法)
Stacking算法:
基本思想:先从初始数据集训练出初级学习器,然后生成一个新数据集用于训练次级学习器。在这个新数据集中,初级学习器的输出被当作样例输入特征,而出事样本的标记仍被当作样例标记。注意点:若直接用初级学习器的训练集来产生次级训练集,则过拟合风险会比较大;一般会通过交叉验证等方式,用训练初级学习器未使用的样本来产生次级学习器的训练样本。
Gradient Boosting
Gradient Boosting是一种Boosting的方法,它主要的思想是,每一次建立模型是在之前建立模型损失函数的梯度下降方向。损失函数是评价模型性能(一般为拟合程度+正则项),认为损失函数越小,性能越好。而让损失函数持续下降,就能使得模型不断改性提升性能,其最好的方法就是使损失函数沿着梯度方向下降(讲道理梯度方向上下降最快)。
Gradient Boost是一个框架,里面可以套入很多不同的算法。
分类树&回归树&分类回归树
分类树
三种比较常见的分类决策树分支划分方式包括:ID3, C4.5, CART。
以C4.5分类树为例,C4.5分类树在每次分枝时,是穷举每一个feature的每一个阈值,找到使得按照feature<=阈值,和feature>阈值分成的两个分枝的熵最大的阈值(熵最大的概念可理解成尽可能每个分枝的男女比例都远离1:1),按照该标准分枝得到两个新节点,用同样方法继续分枝直到所有人都被分入性别唯一的叶子节点,或达到预设的终止条件,若最终叶子节点中的性别不唯一,则以多数人的性别作为该叶子节点的性别。
总结:分类树使用信息增益或增益比率来划分节点;每个节点样本的类别情况投票决定测试样本的类别。
回归树
回归树总体流程也是类似,区别在于,回归树的每个节点(不一定是叶子节点)都会得一个预测值,以年龄为例,该预测值等于属于这个节点的所有人年龄的平均值。分枝时穷举每一个feature的每个阈值找最好的分割点,但衡量最好的标准不再是最大熵,而是最小化均方差即(每个人的年龄-预测年龄)^2 的总和 / N。也就是被预测出错的人数越多,错的越离谱,均方差就越大,通过最小化均方差能够找到最可靠的分枝依据。分枝直到每个叶子节点上人的年龄都唯一或者达到预设的终止条件(如叶子个数上限),若最终叶子节点上人的年龄不唯一,则以该节点上所有人的平均年龄做为该叶子节点的预测年龄。
总结:回归树使用最大均方差划分节点;每个节点样本的均值作为测试样本的回归预测值。
分类回归树
Classification And Regression Trees,即既能做分类任务又能做回归任务,CART也是决策树的一种,是一种二分决策树,但是也可以用来做回归,CART同决策树类似,不同于 ID3 与 C4.5 ,分类树采用基尼指数来选择最优的切分特征,而且每次都是二分。至于怎么利用基尼系数进行最优的特征切分,大家可以参考这篇文章的详细介绍 决策树之 CART
损失函数
机器学习中的损失函数有很多,常见的有
- 0-1损失函数(0-1 loss function)
L(Y,f(X))={1,Y≠f(X)0,Y=f(X)L(Y,f(X))={1,Y≠f(X)0,Y=f(X)
该损失函数的意义就是,当预测错误时,损失函数值为1,预测正确时,损失函数值为0。该损失函数不考虑预测值和真实值的误差程度,也就是只要预测错误,预测错误差一点和差很多是一样的。
平方损失函数(quadratic losswww.cnzhaotai.com function)
L(Y,f(X))=(Y−f(X))2L(Y,f(X))=(Y−f(X))2取预测差距的平方
绝对值损失函数(absolute loss function)
L(Y,f(X))=|Y−f(X)|L(Y,f(X))=|Y−f(X)|取预测值与真实值的差值绝对值,差距不会被平方放大
对数损失函数(logarithmic loss function)
L(Y,P(Y|X))=−logP(Y|X)L(Y,P(Y|X))=−www.yibaoyule1.com logP(Y|X)该损失函数用到了极大似然估计的思想。P(Y|X)通俗的解释就是:在当前模型的基础上,对于样本X,其预测值为Y,也就是预测正确的概率。由于概率之间的同时满足需要使用乘法,为了将其转化为加法,我们将其取对数。最后由于是损失函数,所以预测正确的概率越高,其损失值应该是越小,因此再加个负号取个反。
全局损失函数
上面的损失函数仅仅是对于一个样本来说的。而我们的优化目标函数应当是使全局损失函数最小。因此,全局损失函数往往是每个样本的损失函数之和,即:
J(w,b)=1m∑i=1mL(Y,f(X))J(w,b)=1m∑i=1mL(Y,f(X))对于平方损失函数,为了求导方便,我们可以在前面乘上一个1/2,和平方项求导后的2抵消,即:
J(w,b)=12m∑i=1mL(Y,f(X))J(w,b)=12m∑i=1mL(Y,f(X))- 逻辑回归中的损失函数
在逻辑回归中,我们采用的是对数损失函数。由于逻辑回归是服从伯努利分布(0-1分布)的,并且逻辑回归返回的sigmoid值是处于(0,1)区间,不会取到0,1两个端点。因此我们能够将其损失函数写成以下形式:
L(y^,y)=−(ylogy^+(1−y)log(1−y^))Lwww.thd178.com (y^,y)=−(ylogy^+(1−y)log(1−y^))
GBDT思想
以下部分学习于 GBDT算法原理深入解析 ,原文作者讲的很好,照搬过来,毕竟笔者不是推导数学公式的料,哈哈
GBDT 可以看成是由K棵树组成的加法模型:
其中F为所有树组成的函数空间,以回归任务为例,回归树可以看作为一个把特征向量映射为某个score的函数。该模型的参数为:Θ={f1,f2,⋯,fK}Θ={f1,f2,⋯,fK}。于一般的机器学习算法不同的是,加法模型不是学习d维空间中的权重,而是直接学习函数(决策树)集合 上述加法模型的目标函数定义为:Obj=∑ni=1l(yi,y^i)+∑Kk=1Ω(fk)Obj=∑i=1nl(yi,y^i)+∑k=1KΩ(fk),其中ΩΩ表示决策树的复杂度,那么该如何定义树的复杂度呢?比如,可以考虑树的节点数量、树的深度或者叶子节点所对应的分数的L2范数等等。 如何来学习加法模型呢? 解这一优化问题,可以用前向分布算法(forward stagewise algorithm)。因为学习的是加法模型,如果能够从前往后,每一步只学习一个基函数及其系数(结构),逐步逼近优化目标函数,那么就可以简化复杂度。这一学习过程称之为Boosting。具体地,我们从一个常量预测开始,每次学习一个新的函数,过程如下:
那么,在每一步如何决定哪一个函数ff被加入呢?指导原则还是最小化目标函数。 在第tt步,模型对xixi的预测为:y^ti=y^t−1i+ft(xi)y^it=y^it−1+ft(xi),其中ft(xi)ft(xi)为这一轮我们要学习的函数(决策树)。这个时候目标函数可以写为:
举例说明,假设损失函数为平方损失(square loss),则目标函数为:
其中,(y^t−1i−yi)(y^it−1−yi)称之为残差(residual)。因此,使用平方损失函数时,GBDT算法的每一步在生成决策树时只需要拟合前面的模型的残差。
泰勒公式:设nn是一个正整数,如果定义在一个包含aa的区间上的函数ff在点aa处n+1n+1次可导,那么对于这个区间上的任意xx都有:f(x)=∑n=0Nf(n)(a)n!(x−a)n+Rn(x)f(x)=∑n=0Nf(n)(a)n!(x−a)n+Rn(x),其中的多项式称为函数在aa处的泰勒展开式,Rn(x)Rn(x)是泰勒公式的余项且是(x−a)n(x−a)n的高阶无穷小。
根据泰勒公式把函数f(x+Δx)f(x+Δx)在点xx处二阶展开,可得到如下等式:
由等式(1)可知,目标函数是关于变量y^t−1i+ft(xi)y^it−1+ft(xi)的函数,若把变量y^t−1iy^it−1看成是等式(3)中的xx,把变量ft(xi)ft(xi)看成是等式(3)中的ΔxΔx,则等式(1)可转化为:
其中gigi,定义为损失函数的一阶导数,即gi=∂y^t−1l(yi,y^t−1)gi=∂y^t−1l(yi,y^t−1);hihi定义为损失函数的二阶导数,即hi=∂2y^t−1l(yi,y^t−1)hi=∂y^t−12l(yi,y^t−1)。 假设损失函数为平方损失函数,则gi=∂y^t−1(y^t−1−yi)2=2(y^t−1−yi)gi=∂y^t−1(y^t−1−yi)2=2(y^t−1−yi),hi=∂2y^t−1(y^t−1−yi)2=2hi=∂y^t−12(y^t−1−yi)2=2,把gigi和hihi代入等式(4)即得等式(2)。 由于函数中的常量在函数最小化的过程中不起作用,因此我们可以从等式(4)中移除掉常量项,得:
由于要学习的函数仅仅依赖于目标函数,从等式(5)可以看出只需为学习任务定义好损失函数,并为每个训练样本计算出损失函数的一阶导数和二阶导数,通过在训练样本集上最小化等式(5)即可求得每步要学习的函数f(x)f(x),从而根据加法模型等式(0)可得最终要学习的模型。
GBDT在Scikit-learn中的调用
关于GBDT在Scikit-learn中的实现原文在 [点击查看][3] GBDT在sklearn中导入的包不一样,分类是 from sklearn.ensemble import GradientBoostingClassifier,回归是 from sklearn.ensemble import GradientBoostingRegressor
参数说明
GBDT的参数分为boosting类库参数和弱学习器参数,其中有GBDT的弱学习器为CART,所以弱学习器参数基本为决策树的参数,参考[点击阅读][4]
类库参数
- loss:损失函数,对于分类模型,有对数似然损失函数”deviance”和指数损失函数”exponential”两者输入选择。默认是对数似然损失函数”deviance”。在原理篇中对这些分类损失函数有详细的介绍。一般来说,推荐使用默认的”deviance”。它对二元分离和多元分类各自都有比较好的优化。而指数损失函数等于把我们带到了Adaboost算法。
- learning_rate:即每个弱学习器的权重缩减系数νν,也称作步长。
- n_estimators:就是弱学习器的最大迭代次数,或者说最大的弱学习器的个数。一般来说n_estimators太小,容易欠拟合,n_estimators太大,又容易过拟合,一般选择一个适中的数值。默认是100。在实际调参的过程中,我们常常将n_estimators和下面介绍的参数learning_rate一起考虑。
- subsample:子采样,取值是[0,1]。注意这里的子采样和随机森林不一样,随机森林使用的是放回抽样,而这里是不放回抽样。如果取值为1,则全部样本都使用,等于没有使用子采样。如果取值小于1,则只有一部分样本会去做GBDT的决策树拟合。选择小于1的比例可以减少方差,即防止过拟合,但是会增加样本拟合的偏差,因此取值不能太低。推荐在[0.5, 0.8]之间,默认是1.0,即不使用子采样。
- init:即我们的初始化的时候的弱学习器,如果不输入,则用训练集样本来做样本集的初始化分类回归预测。否则用init参数提供的学习器做初始化分类回归预测。一般用在我们对数据有先验知识,或者之前做过一些拟合的时候,如果没有的话就不用管这个参数了。
- verbose:默认是0,代表启用详细输出,若为1,代表偶尔输出进度信息
- warm_start:默认为false
- random_state:如果int,random_state随机数生成器使用的种子;如果randomstate实例,random_state是随机数发生器;如果没有,随机数生成器使用的np.random的randomstate实例。
- presort:默认情况下会在密集的数据上使用,默认是在稀疏数据正常排序。设置对true的稀疏数据将会引起错误。
决策树参数
- max_depth:决策树最大深度
- criterion:衡量分裂指标的度量方法,支持的是均方误差
- min_samples_split:内部节点再划分所需最小样本数。这个值限制了子树继续划分的条件,如果某节点的样本数少于min_samples_split,则不会继续再尝试选择最优特征来进行划分。 默认是2.如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
- min_samples_leaf:叶子节点最少样本数。这个值限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝。 默认是1,可以输入最少的样本数的整数,或者最少样本数占样本总数的百分比。如果样本量不大,不需要管这个值。如果样本量数量级非常大,则推荐增大这个值。
- min_weight_fraction_leaf:叶子节点最小的样本权重和。这个值限制了叶子节点所有样本权重和的最小值,如果小于这个值,则会和兄弟节点一起被剪枝。 默认是0,就是不考虑权重问题。一般来说,如果我们有较多样本有缺失值,或者分类树样本的分布类别偏差很大,就会引入样本权重,这时我们就要注意这个值了。
- max_features:划分时考虑的最大特征数。可以使用很多种类型的值,默认是”None”,意味着划分时考虑所有的特征数;如果是”log2”意味着划分时最多考虑log2Nlog2N个特征;如果是”sqrt”或者”auto”意味着划分时最多考虑N−−√N个特征。如果是整数,代表考虑的特征绝对数。如果是浮点数,代表考虑特征百分比,即考虑(百分比xN)取整后的特征数。其中N为样本总特征数。一般来说,如果样本特征数不多,比如小于50,我们用默认的”None”就可以了,如果特征数非常多,我们可以灵活使用刚才描述的其他取值来控制划分时考虑的最大特征数,以控制决策树的生成时间。
- max_leaf_nodes:最大叶子节点数。通过限制最大叶子节点数,可以防止过拟合,默认是”None”,即不限制最大的叶子节点数。如果加了限制,算法会建立在最大叶子节点数内最优的决策树。如果特征不多,可以不考虑这个值,但是如果特征分成多的话,可以加以限制,具体的值可以通过交叉验证得到。
- min_impurity_split:节点划分最小不纯度。这个值限制了决策树的增长,如果某节点的不纯度(基于基尼系数,均方差)小于这个阈值,则该节点不再生成子节点。即为叶子节点 。一般不推荐改动默认值1e-7。
- min_impurity_decrease:默认值为0。如果分裂
分类
>>> from sklearn.datasets import make_hastie_10_2
>>> from sklearn.ensemble import GradientBoostingClassifier
>>> X, y = make_hastie_10_2(random_state=0)
>>> X_train, X_test = X[:2000], X[2000:]
>>> y_train, y_test = y[:2000], y[2000:]
>>> clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0,
... max_depth=1, random_state=0).fit(X_train, y_train)
>>> clf.score(X_test, y_test)
0.913...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
回归
>>> import numpy as np
>>> from sklearn.metrics import mean_squared_error
>>> from sklearn.datasets import make_friedman1
>>> from sklearn.ensemble import GradientBoostingRegressor
>>> X, y = make_friedman1(n_samples=1200, random_state=0, noise=1.0)
>>> X_train, X_test = X[:200], X[200:]
>>> y_train, y_test = y[:200], y[200:]
>>> est = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1,
... max_depth=1, random_state=0, loss='ls').fit(X_train, y_train)
>>> mean_squared_error(y_test, est.predict(X_test))
5.00...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
模型评价
from sklearn import cross_validation, metrics
metrics.accuracy_score(y.values, y_pred) # 准确度
metrics.roc_auc_score(y, y_predprob) # AUC大小最新文章
- Kafka基本原理
- PayPal贝宝集成
- C#.Net 图片处理大全
- input输入框的border-radius属性在IE8下的完美兼容
- linux shell 常用基本语法
- [React Native] Error Handling and ActivityIndicatorIOS
- MediaPlayer本地播放流程解析(一)
- Apache+php+mysql+phpadmin搭建
- 【Java】广州三本秋招经历
- Linux常用命令大全(转载收藏)
- SpringBoot 之基础学习篇.
- java递归删除文件夹
- NandFlash和iNand【转】
- shell 运算符
- Angular使用总结 --- 如何正确的操作DOM
- git rebase 操作撤销
- sql server case
- Android Studio 老提示adb问题
- 怎么样imageview实现铺满全屏
- 《JAVA与模式》之迭代器模式